NLPAug allows you to eliminate the imbalance between data classes in text datasets by replacing words with synonyms, double translation, and other methods. Using the library increases the efficiency of neural networks that operate with texts, without the need to change the model architecture and fine-tune it.
The content of the dataset used for training a neural network is one of the key factors determining its effectiveness. The most common problems with datasets that make it impossible to build a reliable machine learning model are the insufficient amount of data and the imbalance of different data groups presented in the dataset. Data augmentation is the synthesis of new data from existing data. Augmentation can be applied to any type of data, from numbers to images. For example, to increase the number of images, you can deform (rotate, crop, etc. d.) available photos. A much more complex task is the augmentation of text data. For example, changing the order of words at first glance may seem to completely change the meaning of a sentence.
The NLPAug library provides effective tools for fast text augmentation:
replacing a certain number of words with their synonyms;
replacing a certain number of words with words that have similar (based on cosine similarity) vector representations (such as word2vec or GloVe);
context-based word substitution using transformers (for example, BERT);
double translation, that is, the translation of a text to another language and back, during which several words are replaced.
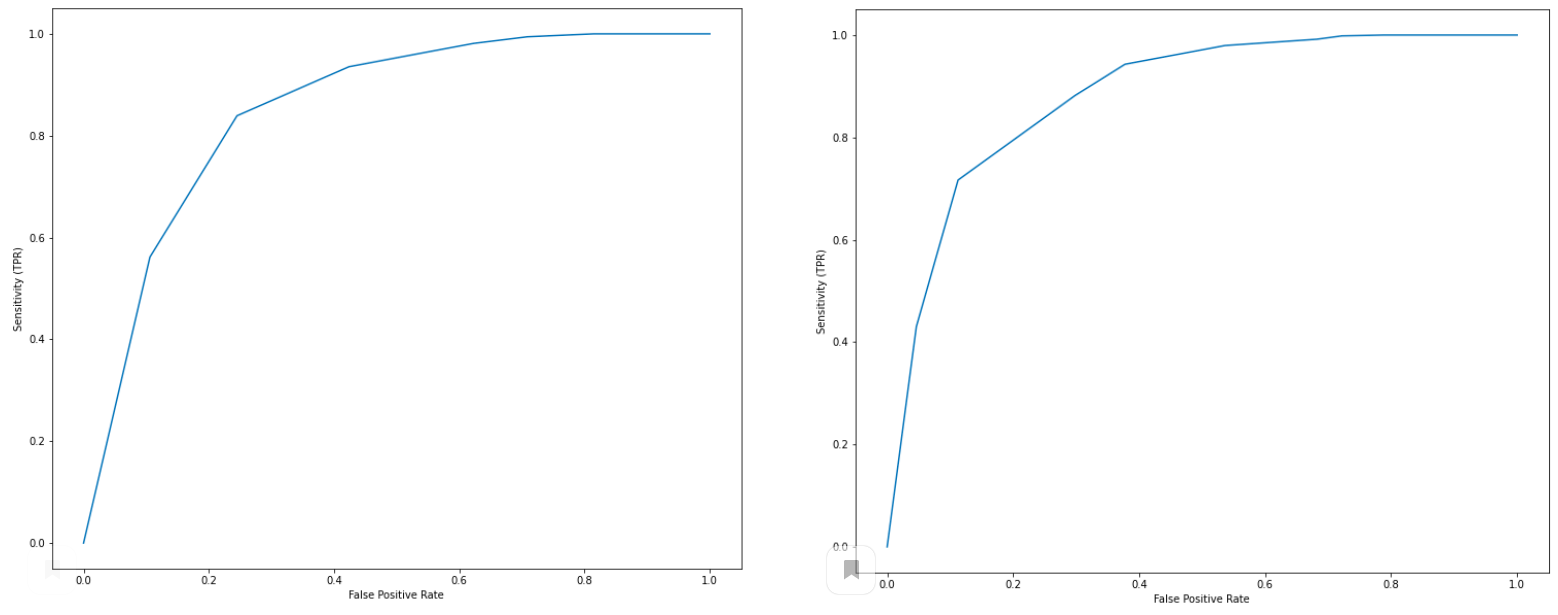
NLPAug makes it possible to increase the efficiency of models (for example, in terms of ROC curves) without changing the architecture and fine-tuning neural networks. As an example, we can consider a dataset consisting of 7,000 Yelp reviews of coffee shops, for which the tonality of the texts is analyzed and compared with the ratings of coffee shops on a 5-point scale set by the review authors. Initially, the dataset is highly unbalanced: the number of positive reviews is 6.5 times higher than the number of negative ones. In the example, negative reviews are augmented: from each such review, two new ones are generated, in which a maximum of 3 words are changed to synonyms. This operation takes less than 1 minute on the CPU, requires less than 5 lines of code, and results in an increase in the AUC from 0.85 to 0.88: