DreamX-World-5B: An Open-Source World Model with Camera Control, Text-Based Control, and Location Memory
17 June 2026

DreamX-World-5B: An Open-Source World Model with Camera Control, Text-Based Control, and Location Memory
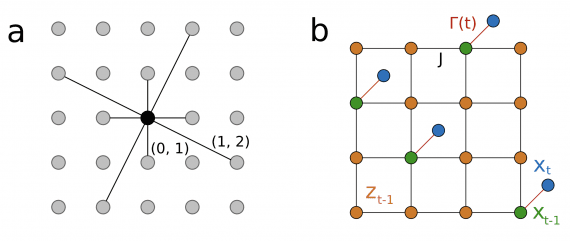
The AMAP-ML team has published DreamX-World 1.0, an interactive generative world model that turns text or an image into a controllable video with precise camera control, memory of previously visited…