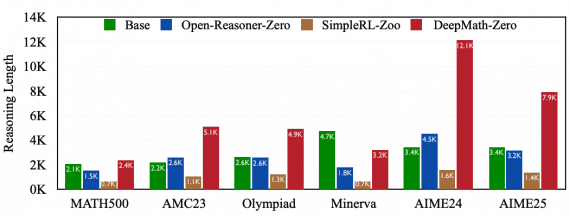
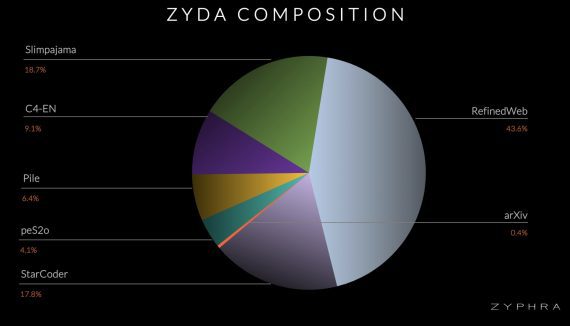
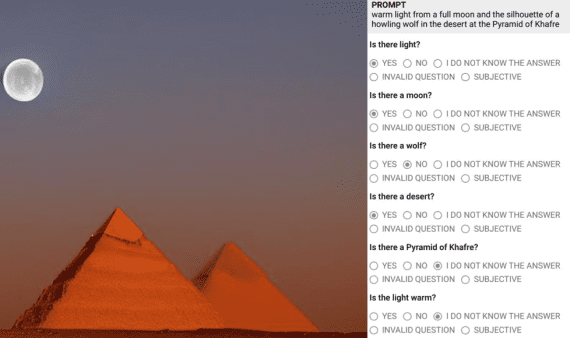
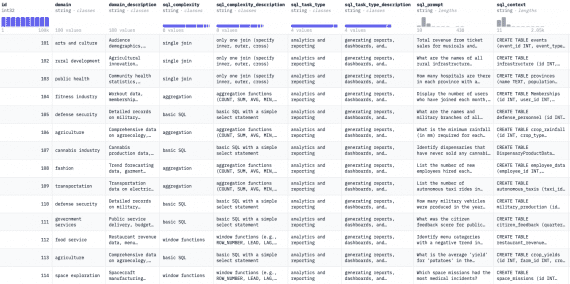
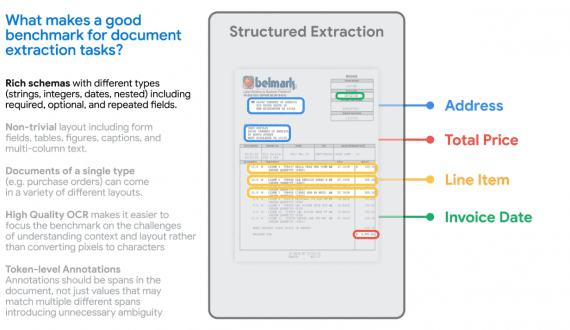
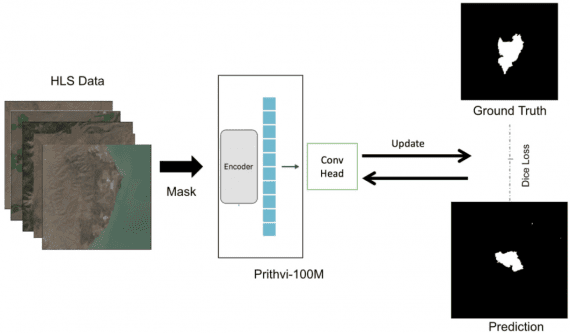
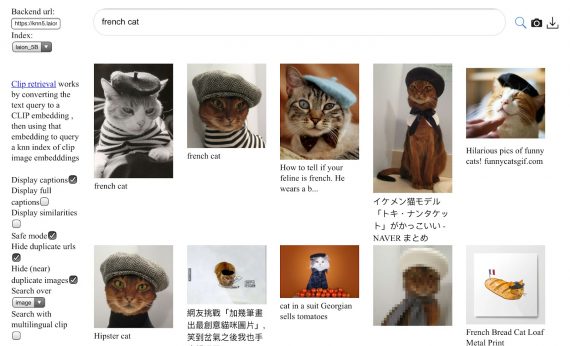
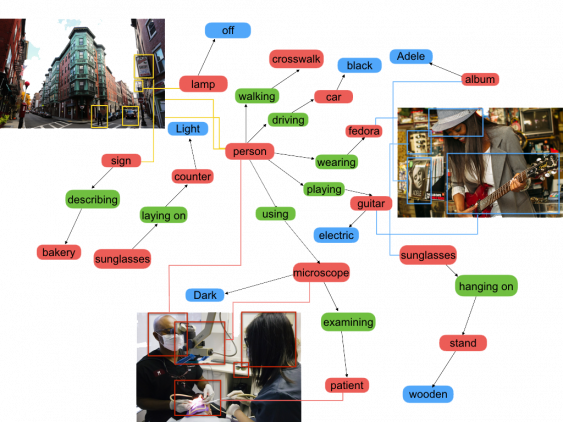
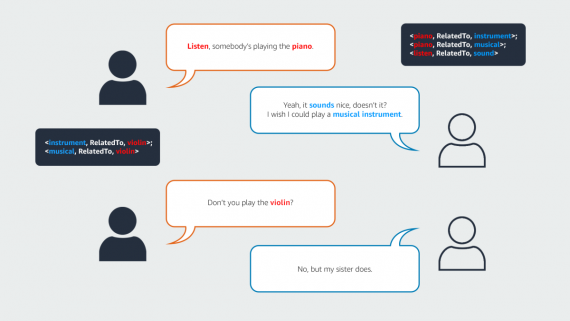
VBVR: 2 Million Videos for Reasoning Training — an Open Dataset That Changes the Rules
26 February 2026

VBVR: 2 Million Videos for Reasoning Training — an Open Dataset That Changes the Rules
A team of more than 50 researchers from around the world — from CMU, Oxford and other universities — has published Very Big Video Reasoning (VBVR), a massive dataset for…