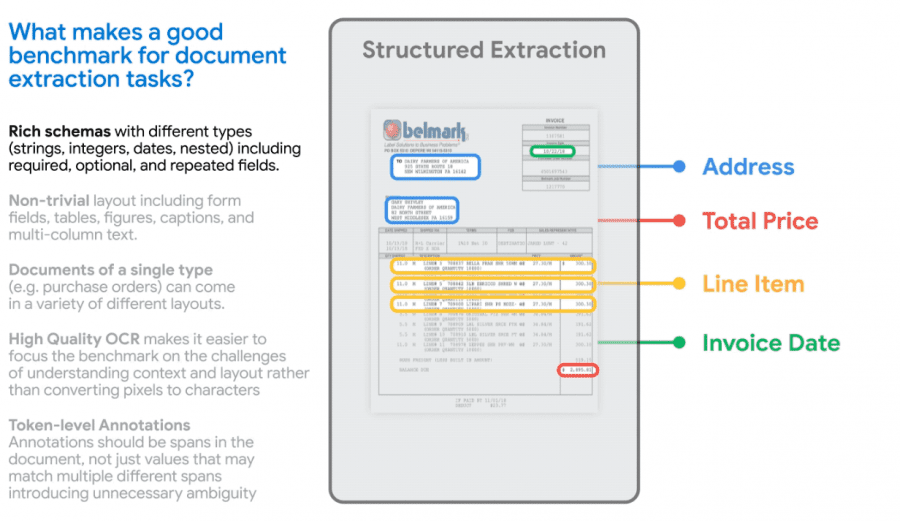
Google has publicly released VRDU, a dataset and benchmark designed for training models in understanding document content. VRDU aims to accelerate the development of models capable of processing complex documents to enhance business process efficiency and reduce manual workload.
Incorporating a system that can automatically extract data from documents such as receipts, insurance policies, and financial reports holds the potential to significantly boost business process efficiency by minimizing error-prone manual labor. However, academic datasets fall short in addressing real-world usage complexities. Consequently, while academic tests exhibit high accuracy for existing models, their real-world performance is subpar.
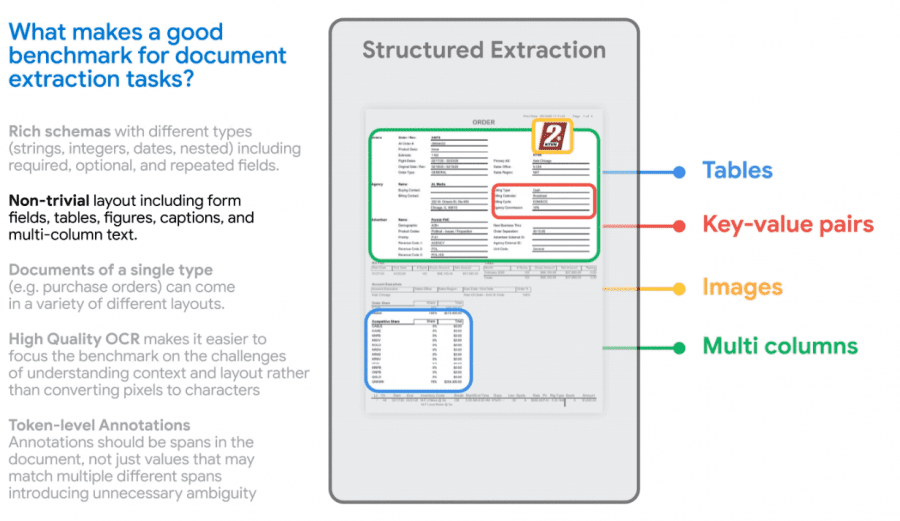
Google researchers have identified a list of task intricacies related to content extraction from documents. This list encompasses the use of diverse data formats (numeric, textual, and date), which can be mandatory or optional within the context of a specific document template. It also takes into account varying formatting styles, structures, and data relationships (including key-value structures, tabular data, and images). The Google VRDU (Visually-rich Document Understanding) dataset and benchmark were designed with these aspects in mind.
The VRDU dataset comprises two types of documents: registration forms and advertising purchase forms. The dataset comprises over 2,000 documents such as invoices and receipts. These documents are textual files derived from converting Google Cloud images, collected from publicly available sources on the internet, into text. Subsequently, the documents were manually annotated to match the values present in the data with their corresponding annotations (e.g., associating numeric tax values with the field labeled “Tax”).
The benchmark facilitates testing models across three types of tasks:
- Single-template training, where the model is trained and used only on one specific document template;
- Multi-template training, where the model is trained and used on a variety of document templates;
- New-template training, where the model is utilized with document structures that weren’t part of its training data.
The dataset and benchmark for VRDU are openly available under the Creative Commons license.









