Google опубликовала в открытом доступе VRDU – датасет и бенчмарк для обучения моделей пониманию содержания документов. VRDU нацелен на ускорение развития моделей, обрабатывающих сложные документы для повышения эффективности бизнес-процессов и уменьшение количества ручной работы.
Система, которая может автоматически извлекать данные из документов, например, квитанций, страховых полисов и финансовых отчетов, потенциально может значительно повысить эффективность бизнес-процессов, избегая ручной работы, подверженной ошибкам. Однако академические датасеты не в состоянии охватить проблемы, наблюдаемые в реальных примерах использования. Как следствие, академические тесты показывают высокую точность существующих моделей, но плохо работают в реальных приложениях.
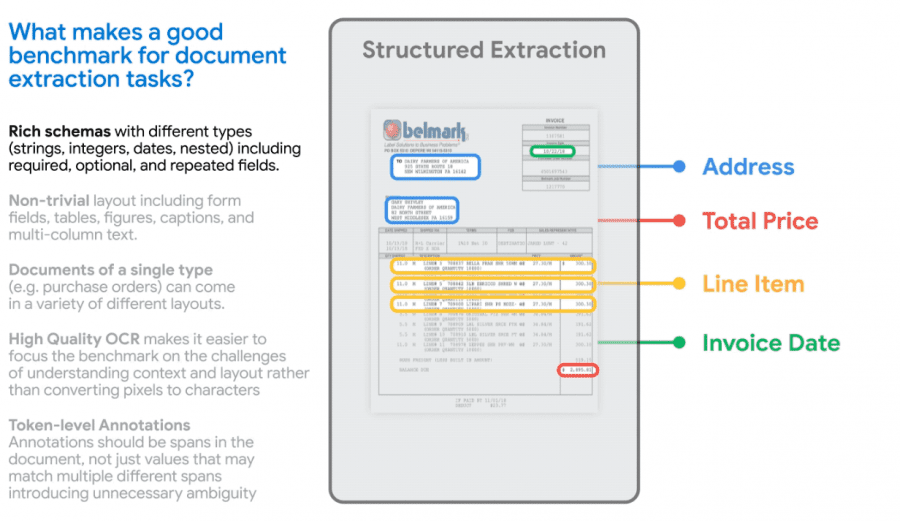
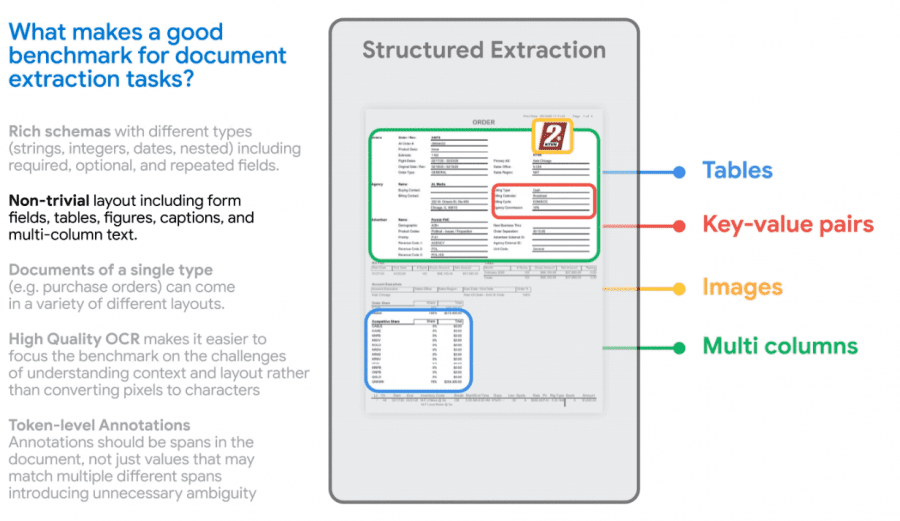
Исследователи Google сформулировали список особенностей задачи извлечения содержания из документов. Этот список включает использование различных форматов данных (числовых, строковых и дат), которые могут являться обязательными или необязательными для заполнения в документе определенного шаблона, а также наличие различных форматов оформления, структур и связей между данными (включая структуры типа ключ-значение, табличные данные и изображения). Датасет и бенчмарк Google VRDU (Visually-rich Document Understanding) были разработаны с учетом данных особенностей.
Датасет VRDU состоит из документов двух типов: регистрационных форм и форм для покупки рекламы. Датасет содержит более 2 000 документов, таких как счета-фактуры и квитанции. Документы являются текстовыми файлами, полученными путем преобразования в текст с помощью Google Cloud изображений, собранных в открытом доступе в Интернете. Затем документы были размечены вручную для сопоставления значений, встречающихся в данных, с их аннотацией (например, числового значения величины налога с названием поля «Налог»).
Бенчмарк позволяет проверять модели на трех видах задач:
- обучение на едином шаблоне, когда модель обучается и используется только на одном шаблоне документов;
- обучение на нескольких шаблонах, когда модель обучается и используется на ряде шаблонов документов;
- обучение на новых шаблонах, когда модель используется на структурах документов, которые не использовались при ее обучении.
Датасет и бенчмарк VRDU доступны в открытом доступе по лицензии Creative Commons.