Google представила Gemini 2.5 Flash Image aka Nano Banana — новую модель генерации изображений
26 августа 2025

Google представила Gemini 2.5 Flash Image aka Nano Banana — новую модель генерации изображений
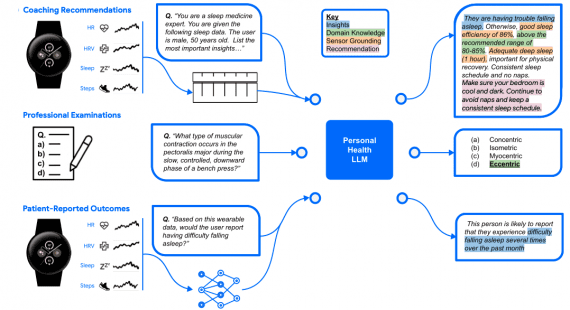
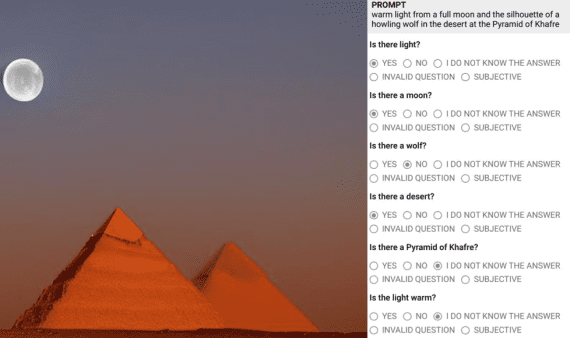
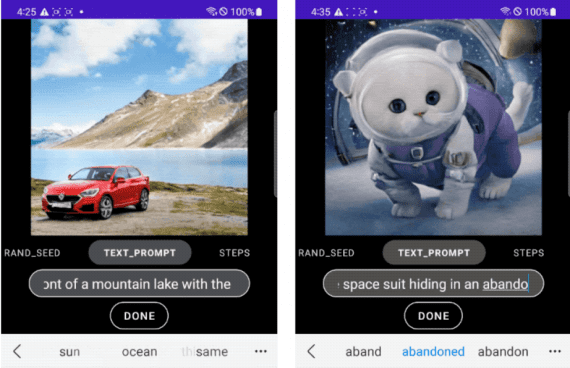
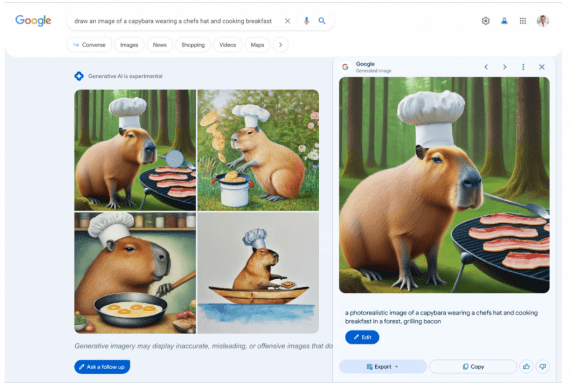
Google представила Gemini 2.5 Flash Image (с внутренним кодовым названием nano-banana) — модель для генерации и редактирования изображений. Модель поддерживает комбинирование нескольких изображений в одно, сохраняет консистентность персонажей между генерациями,…