Исследователи из института Карнеги-Меллон, Google Research и Университета Джорджии представили open source модель генерации видео MAGVIT (Masked Generative Video Transformer). Единая модель MAGVIT способна улучшать FPS, экстраполировать кадры, создавать видео за пределами кадров, заполнять пропущенные участки видео и генерировать видео по заданным условиям. MAGVIT улучшил результаты state-of-the-art подходов на трех бенчмарках генерации видео. На датасете Kinetics-600 MAGVIT показал улучшение на 39%.
Работа авторов будет представлена на конференции CVPR 2023, код модели доступен на Github.
Описание модели
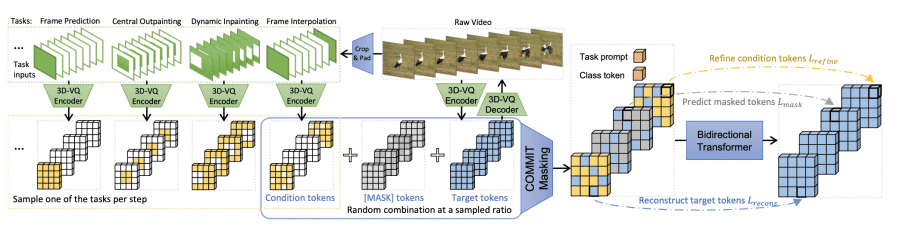
Энкодер 3D-VQ квантизирует видео в дискретные токены, а декодер 3D-VQ отображает их обратно в пространство пикселей. На каждом шаге обучения выбирается одна из задач и создаются ее входные условия путем обрезки и дополнения исходного видео, где зеленый цвет обозначает действительные пиксели, а белый цвет — дополнение. Условные входы квантизируются с помощью энкодера 3D-VQ, non-padding часть выбирается в качестве условных токенов.
Последовательность маскированных токенов объединяет условные токены, токены [MASK] и целевые токены, с задачей и токеном класса в качестве префикса. Двунаправленный трансформер учится предсказывать целевые токены с помощью трех целей: уточнение условных токенов, предсказание маскированных токенов и восстановление целевых токенов.
Авторы разработали 3D-VQ архитектуру для квантизации видео с высоким качеством восстановления. Квантизация происходит с коэффициентом 4 по времени и в 64 раза по высоте и ширине с использованием кодовой книги из 1024 элементов.
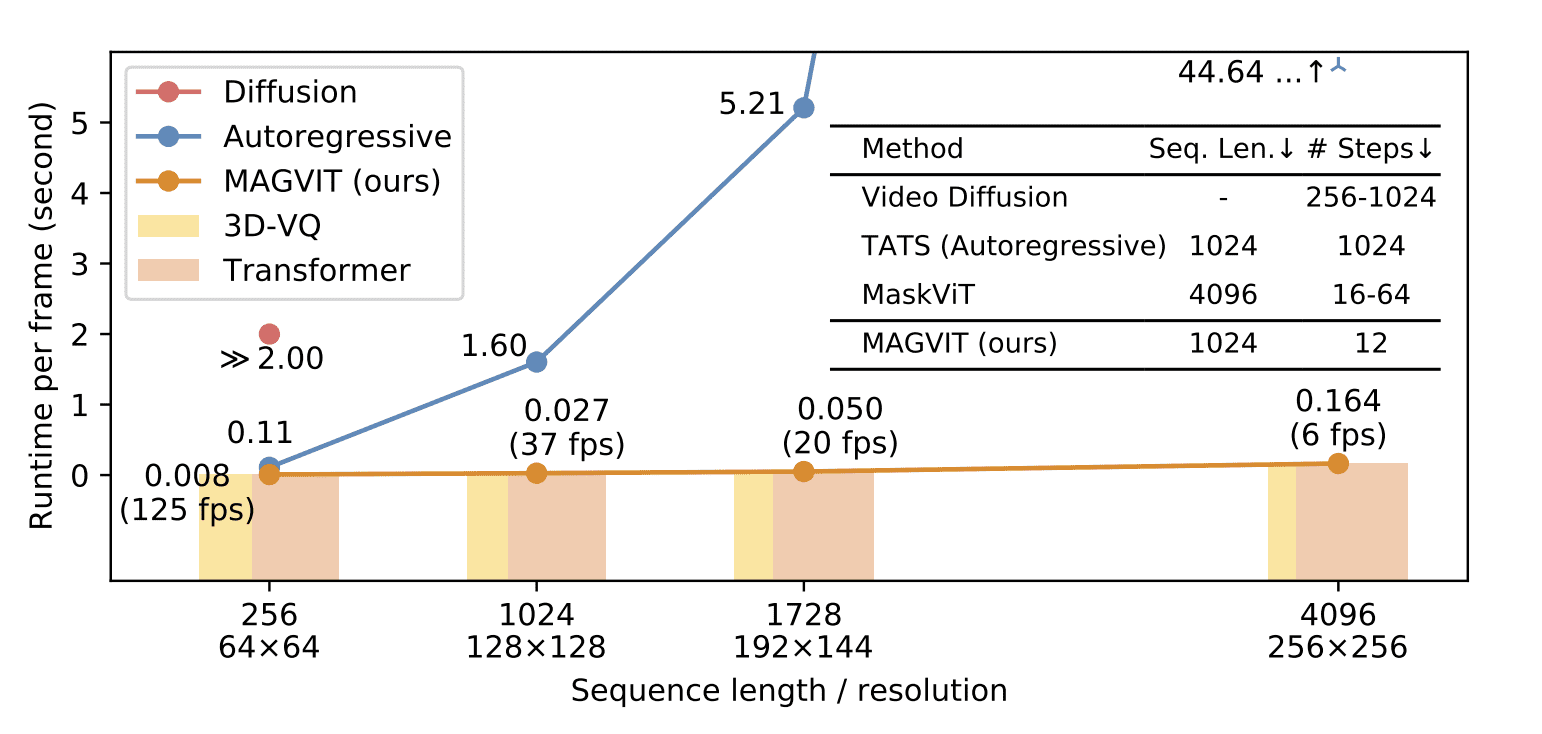
Базовая версия MAGVIT работает со скоростью 37 кадров в секунду на одном графическом процессоре V100.
Обучение MAGVIT
Модель обучалась на общедоступном наборе данных Something-Something-V2 в два этапа:
- на первом VQ-автоэнкодер использовался для квантизации видео в дискретные токены в пространственных и временных измерениях;
- на втором модель Transformer с маскированием токенов получала на вход маскированные визуальные токены и условные токены, и предсказывала токены в маскированных позициях.
Результаты
MAGVIT демонстрирует state-of-the-art показатели в синтезе видео на основе описания класса и первого кадра. Он работает на порядок или два быстрее, чем модели диффузии видео и авторегрессивные модели.
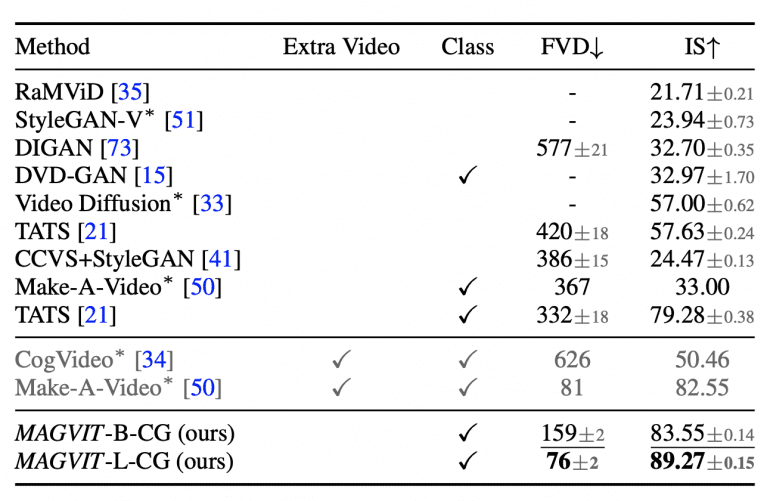
Производительность генерации на наборе данных UCF-101:
Производительность предсказания кадров на наборах данных BAIR и Kinetics-600:

Сравнение эффективности подходов генерации видео по времени вывода: