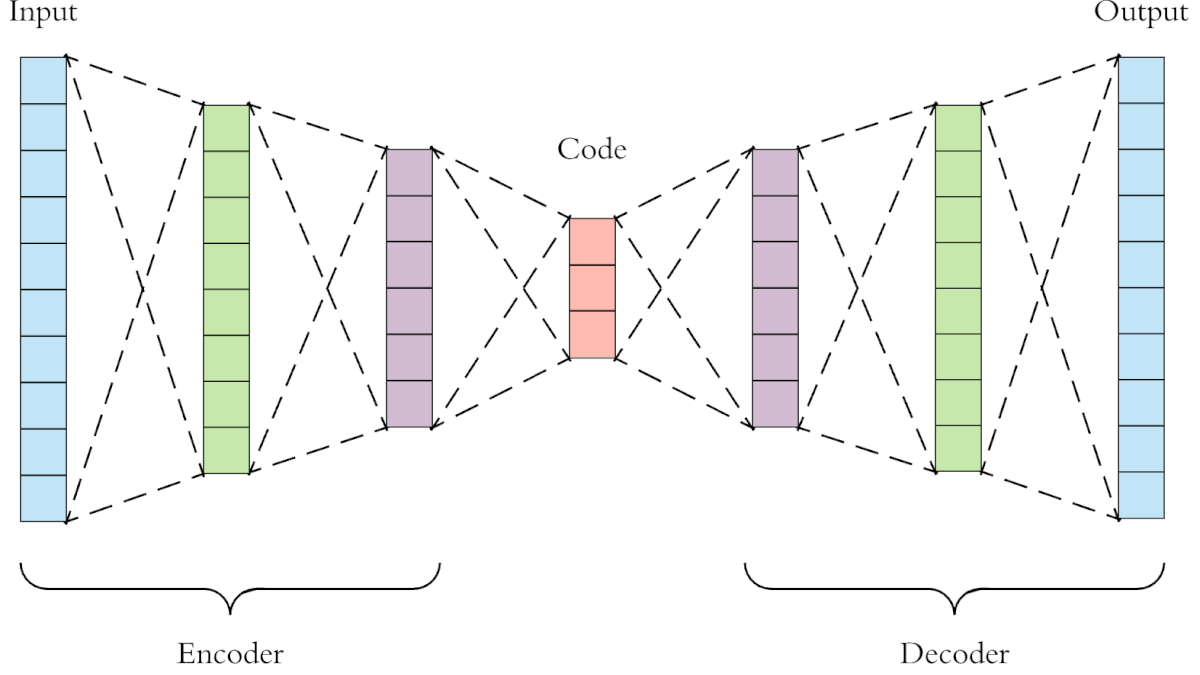
Autoencoder (автокодер, автоэнкодер, AE) — нейронная сеть, которая копирует входные данные на выход. По архитектуре похож на персептрон. Автоэнкодеры сжимают входные данные для представления их в latent-space (скрытое пространство), а затем восстанавливают из этого представления output (выходные данные). Цель — получить на выходном слое отклик, наиболее близкий к входному.
Отличительная особенность автоэнкодеров — количество нейронов на входе и на выходе совпадает.
Автокодер состоит из двух частей:
- Энкодер: отвечает за сжатие входа в latent-space. Представлен функцией кодирования h = f (x);
- Декодер: предназначеа для восстановления ввода из latent-space. Представлен функцией декодирования h = f (x).
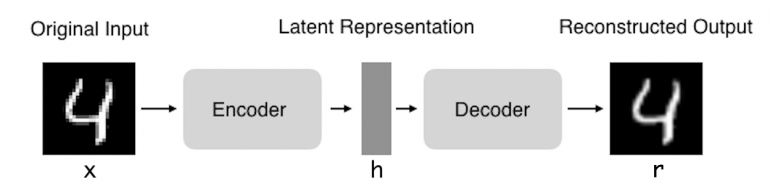
Таким образом, автокодер описывают функцией g (f (x)) = r, где r совпадает с изначальным x на входе.
Зачем копировать вход на выход
Если бы единственной задачей автоэнкодеров было копирование входных данных на выход, они были бы бесполезны. Исследователи рассчитывают на то, что скрытое представление h будет обладать полезными свойствами.
Этого добиваются созданием ограничений для задачи копирования. Один из способов получить полезные результаты от автоэнкодера — ограничить h размерами меньшими , чем x. D этом случае автокодирование называется неполным.
Автоэнкодер может начать выполнять задачу копирования, не извлекая полезной информации о распределении данных, если
- размерность скрытого представления совпадает с размерностью входа;
- размерность скрытого представления больше, чем размерность входа;
- автоэнкодеру предоставляется слишком большой объем данных.
В этих случаях даже линейный кодер и линейный декодер копируют входные данные на выход, не изучая ничего полезного о распределении.
В идеале можно организовать любую архитектуру автокодера, задавая размер кода и емкость энкодера и декодера на основе сложности моделируемого распределения.
Где применяются автоэнкодеры
Два основных практических применения автоэнкодеров для визуализации данных:
- сглаживание шума;
- снижение размерности.
С соответствующими ограничениями по размерности и разреженности автоэнкодеры могут изучать data projections, которые более интересны, чем PCA (метод главных компонент) или другие базовые техники.
Автоэнкодеры обучаются автоматически на примерамх данных. Это означает, что легко натренировать части алгоритма, которые будут затем хорошо работать на конкретном типе ввода и не будут требовать применения новой техники, а только соответствующие данные для обучения.
Однако автоэнкодеры будут плохо справляться со сжатием изображений. По мере того, как автокодер обучается по заданному датасету, он достигает разумных результатов сжатия, аналогичных используемому для тренировок набору, но плохо работает как компрессор общего назначения. Сжатие JPEG, например, будет справляться намного лучше.
Автокодеры обучены как сохранять информацию, так и придавать новым представлениям разные свойства. Для этого используют разные типы автоэнкодеров.
Типы автоэнкодеров
В этой статье будут описаны четыре следующих типа автокодеров:
- Автокодер Vanilla;
- Многослойный автокодер;
- Сверточный автокодер;
- Регуляризованный.
Чтобы проиллюстрировать типы автокодеров, с помощью структуры Keras и датасета MNIST создан пример каждого из них. Код для каждого типа автокодера доступен на GitHub.
Автоэнкодер vanilla
В своей простейшей форме автокодер является сетью из трех слоев, то есть нейронной сетью с одним скрытым слоем. Вход и выход совпадают, мы узнаем, как восстановить входные данные, используя, например, оптимизатор adam и функцию потерь среднеквадратичной ошибки.
Здесь мы видим неполный автокодер, поскольку размер скрытого слоя (64) меньше, чем вход (784). Это ограничение заставит нашу нейронную сеть изучить сжатое представление данных.
Многослойный автоэнкодер
Если одного скрытого слоя недостаточно, автокодер расширяют до большего их количества.
Теперь наша реализация использует 3 скрытых слоя вместо одного. Любой из скрытых слоев можно выбрать как представление функции, но мы сделаем сеть симметричной и будем использовать средний слой.
Сверточные автоэнкодеры
Можно ли использовать автокодеры со свертками вместо использования с полносвязными слоями?
Ответ — да. И принцип тот же, но только с использованием 3D-векторов вместо 1D-векторов.
Разрешение входного изображения уменьшается, чтобы получить скрытое представление меньших размеров, и чтобы автоэнкодер изучил сжатое изображение.
Регуляризованный автоэнкодер
Вместо того, чтобы ограничивать емкость модели, сохраняя кодер и декодер неглубокими, и использовать короткий код, регуляризованные автокодеры используют функцию потерь. Она добавляет модели другие свойства, кроме копирования своего входа на вывод. На практике используют два типа регуляризованного автоэнкодера: разреженный (sparse) и шумоподавляющий (denoising).
Sparse
Sparse автокодеры обычно изучают образы для других (по сравнению с классификацией) задач. Автоэнкодер, регуляризованный как sparse, реагирует на уникальные характеристики датасета, на котором он был обучен, а не просто действовать в качестве идентификатора. Таким образом, обучая sparse автокодер, получают модель, которая в качестве побочного эффекта изучила полезные образы.
Еще один способ, с помощью которого ограничивают реконструкцию автокодера, является наложение ограничения на его потери. Например, мы могли бы добавить в функцию потерь термин регуляризации. Это позволит автокодеру изучать разреженные представления данных.
В наш скрытый слой мы добавили регулятор активности l1, который будет применять штраф к функции потерь во время фазы оптимизации. Как результат, представление теперь более уникальное по сравнению с автокодером vanilla.
Denoising
Вместо добавления штрафа к функции потерь мы можем получить автокодер, который изучает что-то полезное, изменив значение реконструкционной ошибки функции потерь. Это можно сделать, добавив шум ко входному изображению и научив автокодер его удалять. Таким образом, кодер будет извлекать наиболее важные функции и изучать более редкое представление данных.
Интересные статьи по теме:
- Генеративно-состязательная нейросеть (GAN). Руководство для новичков
- Персептрон Розенблатта — машина, которая смогла обучаться
- Обучение с подкреплением на Python с библиотекой Keras







А разве при такой реализации сверточный автоэнкодер не будет иметь разные размерности на входе и выходе?