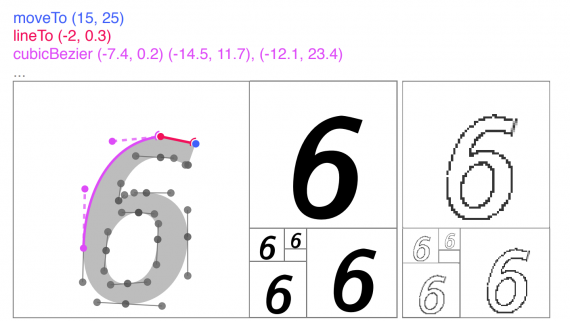
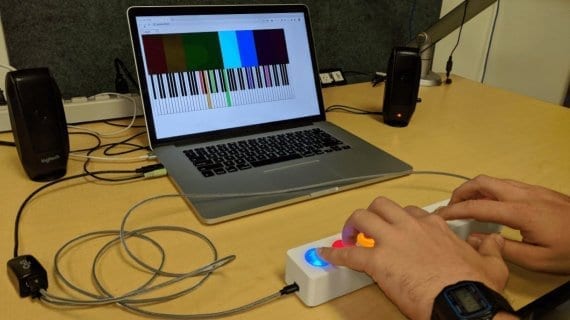
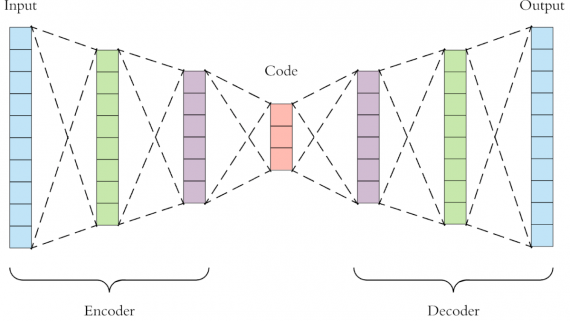
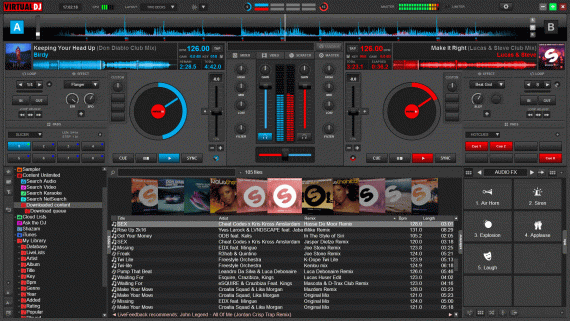
Jukebox: нейросеть от OpenAI генерирует песни
1 мая 2020
Jukebox: нейросеть от OpenAI генерирует песни
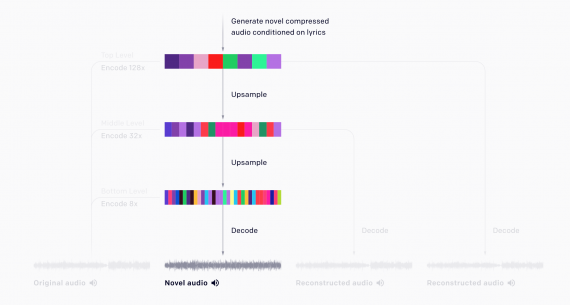
Jukebox — это нейросеть от OpenAI, которая генерирует песни. Модель принимает на вход жанр, артиста и текст песни. На выходе нейросеть отдает аудиозапись с сгенерированной песней. Тысячи примеров сгенерированных песен…