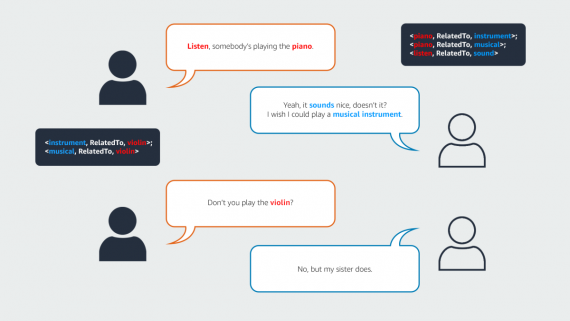
VBVR: открытый датасет на 2 миллиона видео для обучения видеомоделей рассуждению
26 февраля 2026

VBVR: открытый датасет на 2 миллиона видео для обучения видеомоделей рассуждению
Команда из более чем 50 исследователей со всего мира — из CMU, Oxford и других университетов — опубликовала Very Big Video Reasoning (VBVR) — огромный набор данных для обучения видеомоделей…