Ученые из Google Brain исследовали, как извлечь представления высокоуровневых характеристик объектов из векторных изображений, и использовали это для генерации шрифтов в формате SVG. Несмотря на текущие успехи в применении GANов для генерации объектов на изображениях, они все еще имеют ограничения. Одно из них — ограниченная возможность извлечения высокоуровневых характеристик объектов из изображений.
Постановка задачи и данные
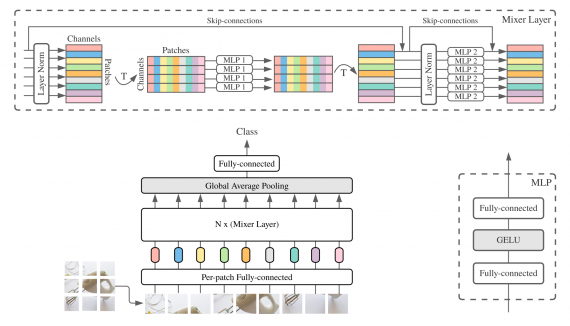
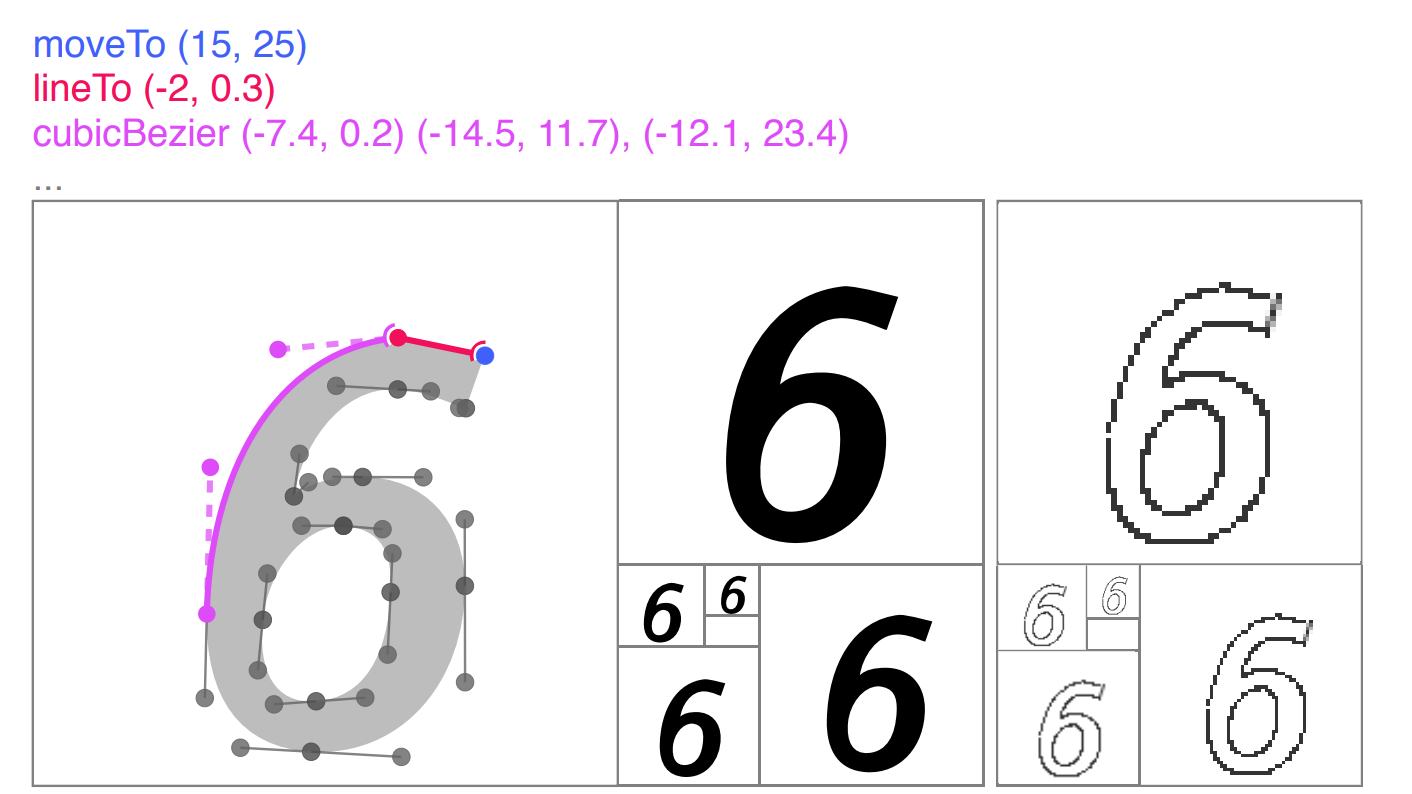
Цель исследования заключалась в том, чтобы научить сеть генерировать шрифты, используя данные из SVG формата. На выходе модели вместо набора пикселей исследователи планировали получить список SVG команд для отрисовки объекта.
Выборка состояла из 14 миллионов символов в сумме и 62 уникальных категорий символов (0-9, a-z, A-Z). Каждый набор символов (файл со шрифтом) был преобразован из SFD в SVG и нормализован. При конвертации из одного формата в другой исследователи ограничили список SVG команд до четырех: moveTo, lineTo, cubicBezier и EOS. Подробнее процесс обработки и нормализации описан в оригинальной статье. Итоговая обучающая выборка состояла из 12.6 миллионов примеров, а тестовая — из 1.4 миллионов.
Архитектура модели
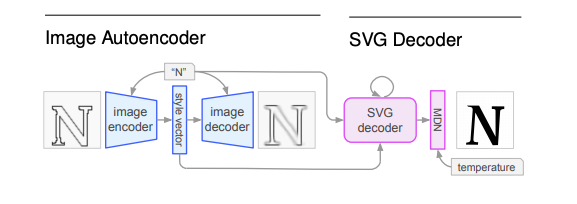
Модель имела двухступенчатую структуру:
- Сначала на вход вариационному автоэкодеру (VAE) поступала картинка в SVG формате;
- SVG декодер принимал на вход предсказанный класс (тип символа) и его векторное представление и выдавал сгенерированный символ.
SVG декодер состоял из нескольких LSTM и одной Mixture Density Network (MDN).
Результаты
Ученые использовали качественную оценку результатов работы модели. Ниже представлены отобранные примеры сгенерированных шрифтов.

Интересно отметить, что исследователи отдельно не задавали, что символы, идущие друг за другом на одной строке представляют собой один шрифт. Эта характеристика была латентно выучена моделью и в векторном пространстве символы с похожими шрифтами находились ближе друг к другу.
В попытке квантифицировать оценку модели исследователи выбрали два способа. На картинках (a) изображены графики функции потери для обучающей/тестовой выборок (верхняя) и отдельных классов символов (нижняя). На картинках (b) визуализированы функции потери на тестовой выборке для двух классов: “8” (верхняя) и “7” (нижняя).
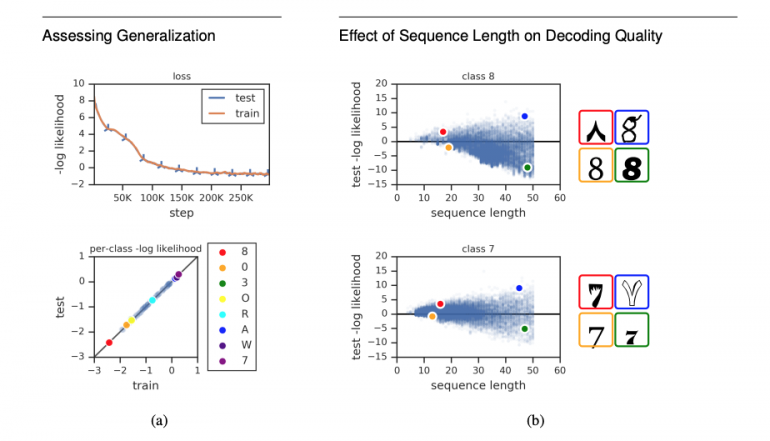
Можно отметить, что предложенная архитектура успешно учится как генерировать символы разными шрифтами, так и распространять шрифт сгенерированного символа на последующие.
Ограничения и дальнейшая работа
Первое ограничение модели заключается в том, что на одном из этапов обучения она выбирает команды с низкой вероятностью. Это, в свою очередь, ведет к серии ошибок. Примером этого являются сгенерированные символы “3” (красная линия означает совершенную ошибку) и “6” (разрыв линии наверху).
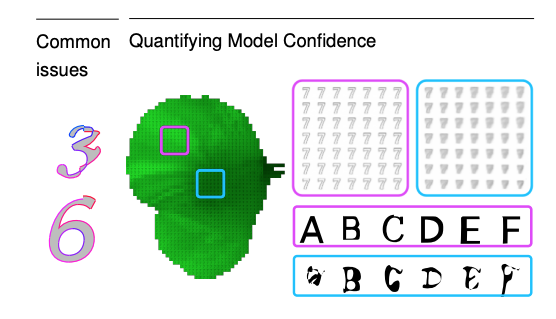
Кроме того, низкая степень уверенности модели ведет к тому, что сгенерированные символы получаются нечеткими. Векторное пространство символов визуализировано на изображении выше: чем ярче зеленый, тем выше уверенность модели (ниже дисперсия VAE). Розовым отмечен пример, когда степень уверенности модели высокая, обратный случай указан голубым цветом. Данные ограничения будут приняты во внимание в будущих исследованиях.