TreeQuest Framework: Adaptive LLM Teams Outperform Individual Models by 30%
8 July 2025

TreeQuest Framework: Adaptive LLM Teams Outperform Individual Models by 30%
Researchers from Sakana AI have introduced Adaptive Branching Monte Carlo Tree Search (AB-MCTS) — a revolutionary approach to creating “dream teams” from large language models that allows them to dynamically…
Show-o2: Open-source 7B multimodal model outperforms 14B models on benchmarks using significantly less training data
26 June 2025

Show-o2: Open-source 7B multimodal model outperforms 14B models on benchmarks using significantly less training data
Researchers from Show Lab at the National University of Singapore and ByteDance introduced Show-o2 — a second-generation multimodal model that demonstrates superior results in image and video understanding and generation…
MiniCPM4: Open Local Model Achieves Qwen3-8B Performance with 7x Inference Acceleration
15 June 2025

MiniCPM4: Open Local Model Achieves Qwen3-8B Performance with 7x Inference Acceleration
The OpenBMB research team presented MiniCPM4 — a highly efficient language model designed specifically for local devices. MiniCPM4-8B achieves comparable performance to Qwen3-8B (81.13 vs 80.55), while requiring 4.5 times…
AI-Powered Testing Tools to Automate Model Validation Pipelines
11 June 2025

AI-Powered Testing Tools to Automate Model Validation Pipelines
Deep learning has transformed artificial intelligence, nurturing advancements in language modelling, decision systems, and image recognition. Despite the performance optimization, the workflow at the backend of deep learning model development…
Strict On-Policy Training with Optimal Baseline: Microsoft Introduces Simplified Algorithm for RLHF
4 June 2025
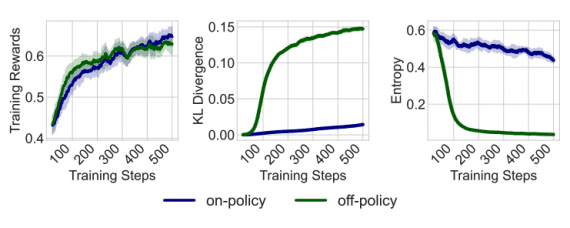
Strict On-Policy Training with Optimal Baseline: Microsoft Introduces Simplified Algorithm for RLHF
The Microsoft Research team introduced On-Policy RL with Optimal reward baseline (OPO) — a simplified reinforcement learning algorithm for aligning large language models. The new method addresses key problems of…
Mistral Agents API: AI Agent Framework with Web Search, Code Generation, and Image Generation Capabilities
28 May 2025
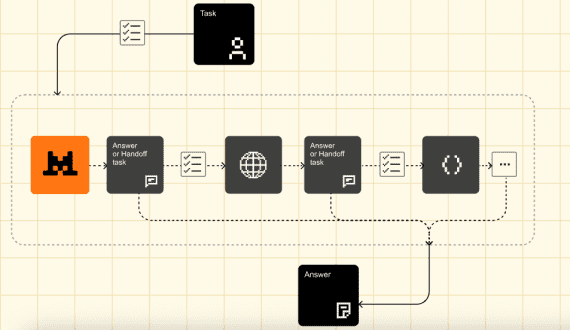
Mistral Agents API: AI Agent Framework with Web Search, Code Generation, and Image Generation Capabilities
French startup Mistral AI introduced Agents API — a framework for creating autonomous AI agents with built-in connectors, persistent memory, and orchestration capabilities. Developers can create unlimited agents and build…
Visual-ARFT: Multimodal AI Agents Outperform GPT-4o by 18.6% in Complex Visual Tasks
22 May 2025
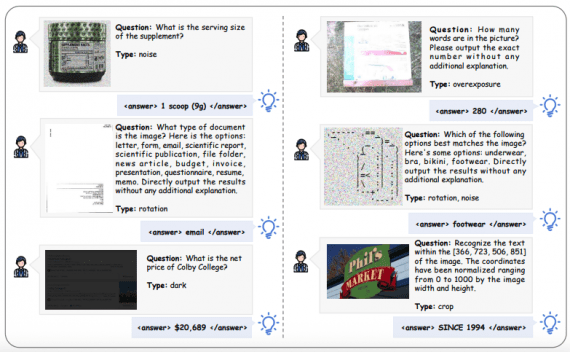
Visual-ARFT: Multimodal AI Agents Outperform GPT-4o by 18.6% in Complex Visual Tasks
A research team from Shanghai Jiao Tong University and Shanghai Artificial Intelligence Laboratory has introduced Visual Agentic Reinforcement Fine-Tuning (Visual-ARFT) — a new approach to training large multimodal models with…
NVIDIA Isaac 5.0: Enhanced Sensor Physics and Expanded Synthetic Data Generation
19 May 2025

NVIDIA Isaac 5.0: Enhanced Sensor Physics and Expanded Synthetic Data Generation
NVIDIA continues to push the boundaries of AI-driven robotics with significant updates to its Isaac ecosystem, announced at COMPUTEX 2025. These innovations address key challenges in robotics development by enhancing…
ZEROSEARCH: A Framework That Cuts LLM Search Training Costs by 88%
9 May 2025
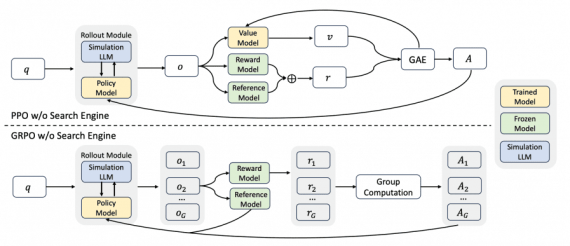
ZEROSEARCH: A Framework That Cuts LLM Search Training Costs by 88%
Alibaba’s NLP research team has officially open-sourced ZEROSEARCH, a complete framework for training LLMs to search without using real search engines. ZEROSEARCH builds on a key insight: LLMs have already…
Phi-4-reasoning: Microsoft’s Breakthrough in AI Thinking
4 May 2025

Phi-4-reasoning: Microsoft’s Breakthrough in AI Thinking
Microsoft recently unveiled Phi-4-reasoning, a 14-billion parameter model that achieves exceptional performance on complex reasoning tasks, outperforming models 5-47 times larger while requiring significantly less computational resources, with developers able…
DeepMath-103K: Advancing AI Reasoning Through Challenge
21 April 2025
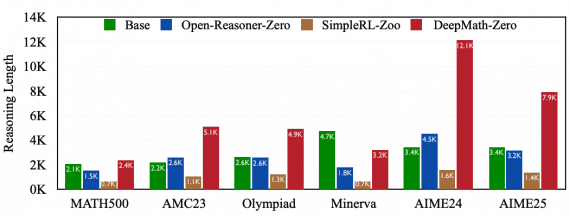
DeepMath-103K: Advancing AI Reasoning Through Challenge
Mathematical reasoning stands as a crucial benchmark for artificial intelligence systems, requiring logical deduction, symbolic manipulation, and multi-step problem-solving. Recent breakthroughs in AI reasoning have been significantly driven by reinforcement…
MedSAM2: Open Source SOTA 3D Medical Image and Video Segmentation Model
13 April 2025

MedSAM2: Open Source SOTA 3D Medical Image and Video Segmentation Model
Medical image segmentation plays a critical role in precision medicine, enabling more accurate diagnosis, treatment planning, and quantitative analysis. While significant progress has been made in developing both specialized and…
Claude for Education: Revolutionizing Higher Education with AI-Powered Learning
3 April 2025
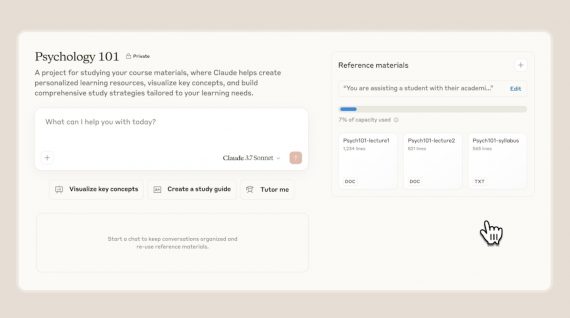
Claude for Education: Revolutionizing Higher Education with AI-Powered Learning
Anthropic has released Claude for Education, specifically designed for implementation in universities and other higher education institutions. While the classic chatbot provides direct answers to questions, Claude for Education uses…
Llama Nemotron: NVIDIA Launches Family of Open Reasoning AI Models Overtaking DeepSeek R1
19 March 2025

Llama Nemotron: NVIDIA Launches Family of Open Reasoning AI Models Overtaking DeepSeek R1
NVIDIA has announced the open Llama Nemotron family of models with reasoning capabilities, designed to provide a business-ready foundation for creating advanced AI agents. These models can work independently or…
Chain-of-Experts: Novel Approach Improving MoE Efficiency with up to 42% Memory Reduction
11 March 2025
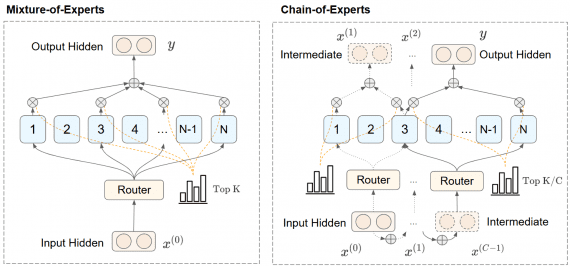
Chain-of-Experts: Novel Approach Improving MoE Efficiency with up to 42% Memory Reduction
Chain-of-Experts (CoE) – a novel approach fundamentally changing how sparse language models process information, delivering better performance with significantly less memory. This breakthrough addresses key limitations in current Mixture-of-Experts (MoE)…
R1-Onevision: Open Source 7B-Parameter Model Outperforming GPT-4o in Maths and Reasoning Tasks
27 February 2025

R1-Onevision: Open Source 7B-Parameter Model Outperforming GPT-4o in Maths and Reasoning Tasks
Researchers from Zhejiang University have released R1-Onevision, a 7B parameters multimodal reasoning model that processes and analyzes visual inputs with unprecedented logical precision, capable of understanding complex mathematical, scientific, and…
Step-Video-T2V: Text-to-Video Open-Source Model Achieves 16x Video Compression Breakthrough
20 February 2025

Step-Video-T2V: Text-to-Video Open-Source Model Achieves 16x Video Compression Breakthrough
Researchers from Stepfun AI have developed Step-Video-T2V, a 30-billion-parameter text-to-video model that generates videos up to 204 frames in length, 544×992 resolution, capable of understanding both Chinese and English prompts.…
Adobe Drops Industry-First Commercially Safe AI Video Model
13 February 2025
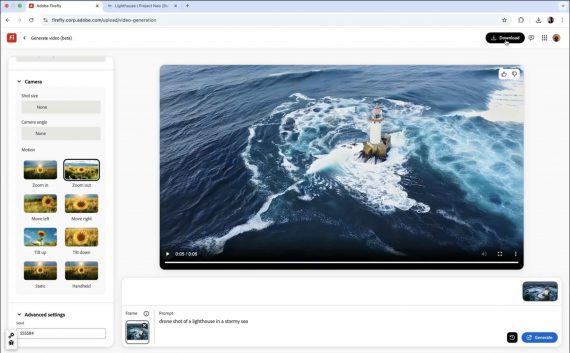
Adobe Drops Industry-First Commercially Safe AI Video Model
Adobe has launched its Firefly video model in public, marking the first generative AI tool built specifically for commercial use, addressing enterprise concerns about IP rights and legal safety in…
EPFL Study: Language Models Don’t Translate Into English – They Operate Through Concepts
30 January 2025
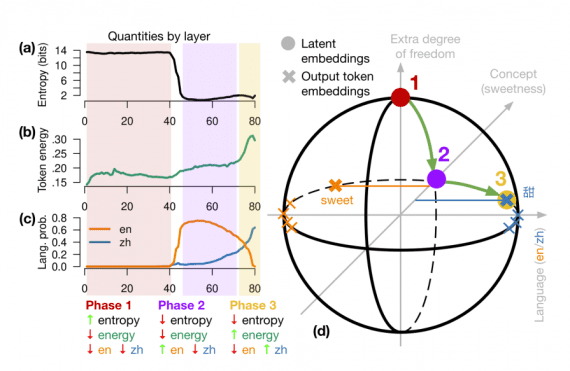
EPFL Study: Language Models Don’t Translate Into English – They Operate Through Concepts
New research from EPFL sheds light on the internal mechanisms of multilingual data processing in LLMs, which is critical for understanding how modern language models work and how to optimize…
ByteDance Unveil TA-TiTok Tokenizer Achieving SOTA in Text-to-Image Generation Using Only Public Data
19 January 2025

ByteDance Unveil TA-TiTok Tokenizer Achieving SOTA in Text-to-Image Generation Using Only Public Data
Researchers from ByteDance and POSTECH introduced TA-TiTok (Text-Aware Transformer-based 1-Dimensional Tokenizer), a novel approach to making text-to-image AI models more accessible and efficient. Their work demonstrates through MaskGen models how…
MiniMax-01: 4M Context Length Benchmark Leader Powered by Lightning Attention
15 January 2025
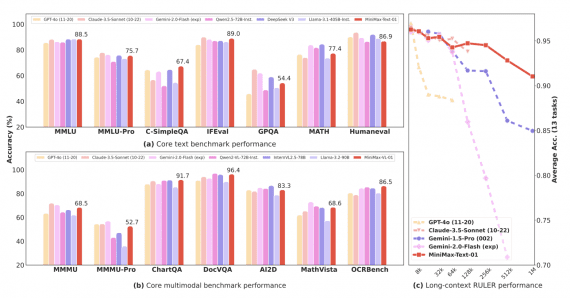
MiniMax-01: 4M Context Length Benchmark Leader Powered by Lightning Attention
MiniMax has open-sourced its latest MiniMax-01 series, introducing two models that push the boundaries of context length and attention mechanisms: MiniMax-Text-01 for language processing and MiniMax-VL-01 for visual-language tasks. The…