В настоящее время генеративные модели привлекают к себе огромное внимание в мировой среде машинного обучения. Этот тип моделей имеет практическое применение в различных сферах. Одни из самых эффективных и широко используемых типов данной модели – это Вариационные Автоэнкодеры (Variational Autoencoders – VAE) и Генеративные состязательные нейросети (Generative Adversarial Networks – GAN).

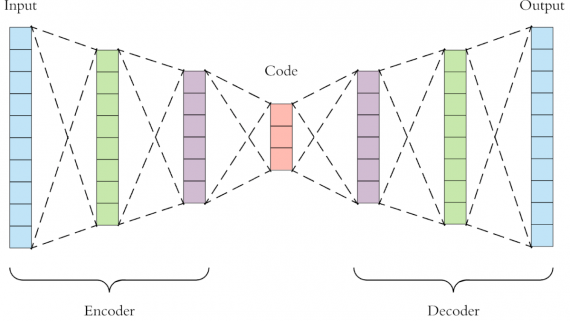
Несмотря на то, что классические автоэнкодеры могут обучаться для генерации компактных представлений и хорошо восстанавливают исходные данные, они оказываются довольно ограниченными при практическом применении. Фундаментальной проблемой автоэкодеров является тот факт, что скрытое пространство, в котором они кодируют входные данные, может не быть непрерывным и не допускать гладкой интерполяции.
Другой тип автоэнкодеров, называемых Вариационными Автоэнкоднерами, может решить эту проблему, так как их скрытое пространство вследствие своего устройства является непрерывным и позволяет легко производить случайную выборку и интерполяцию. Это делает VAEs столь популярными в применении ко многим задачам, особенно в области компьютерного зрения. Однако, управление глубокими нейронными сетями и, в особенности, глубокими автоэнкодерами – сложная задача, ключевая особенность которой — строгий контроль процесса обучения.
Ранние работы
Проблема выявления признаков (feature disentanglement) давно была рассмотрена в литературе на примере обработки изображений и видео, а также анализа текстов. Выявление факторов вариации играет важную роль для управления глубокими нейросетями и понимания их принципа работы.
Предыдущие работы помогли установить, что имеет место разделение скрытых представлений изображений в несколько пространств, каждое из которых ответственно за различные степени вариации. К примеру, одной степенью вариаций обладают идентичность, освещение, пространственное окружение, а другой, более общей — пространственные трансформации (повороты, смещения, масштабирование). Также существуют более специфичные уровни вариаций, в которые входят, например, возраст, пол, использование очков.
Деформирующий автоэнкодер
Не так давно, Zhixin Shu и коллеги представили новые Деформирующие Автоэнкодеры, или коротко – DAEs (Deforming autoencoders). DAE представляет собой генеративную модель анализа изображений, которая выделяет признаки без дополнительных подсказок. В своей работе, исследователи предлагают способ выделения признаков, предполагая создавать экземпляры объектов посредством деформации «шаблонного» объекта. Это означает, что вариативность объекта может быть разделена на уровни, связанные с пространственными трансформациями формы объекта. Несмотря на простоту идеи, это решение, основанное на глубоких автоэнкодерах и самостоятельном обучении нейросети, доказало свою эффективность в ряде задач.
Описание метода
Деформирующий автоэнкодер способен определять форму и внешний вид объекта как степени вариативности в изученном малоразмерном скрытом пространстве. Подход основан на архитектуре, состоящей из энкодера, который кодирует входное изображение в два скрытых вектора (один – для формы, другой – для вида), и двух декодеров, принимающих векторы в качестве входных данных и выдающих сгенерированную текстуру и деформации.
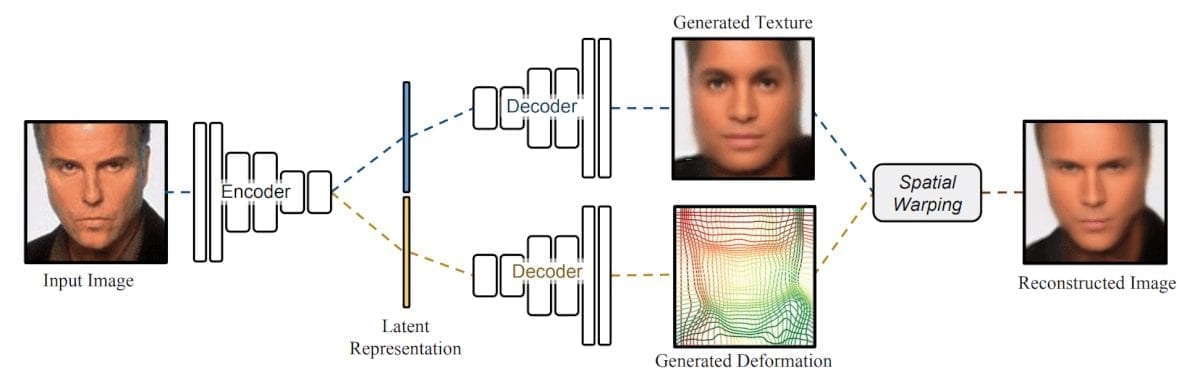
Независимые декодеры необходимы для получения функций внешнего вида и деформации. Сгенерировнная пространственная информация используется для деформации текстуры к наблюдаемым координатам изображения. В этом случае Деформирующий Аквтоэнкодер может восстановить входное изображение и в то же время определеить форму и вид объекта как различные особенности. Вся нейросеть тренируется без помощника на основе лишь простых потерь восстановленич изображения.
В дополнение к DAEs, исследователи предлагают Деформирующие Автоэнкодеры с заданной классификацией, которые учатся восстанавливать изображение и одновременно определяют форму и вид факторов вариативности, соответствующие определенному классу. Для реализации этого подхода, они вводят класифицирующую нейросеть, которая принимает третий скрытый вектор, используемый для кодирования класса. Такой тип архитектуры позволяет изучать смешанную модель, обусловленную классом входного изображения.
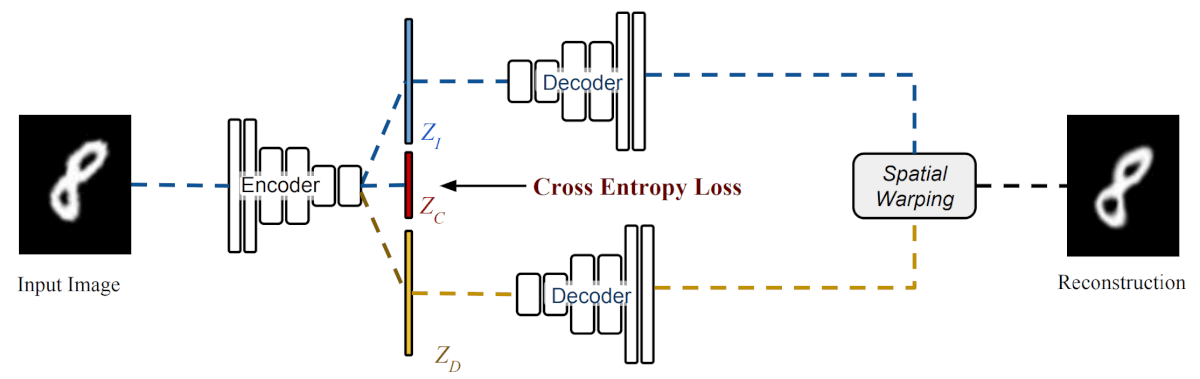
Исследовтели показывают, что введение классифицированного обучения резко улучшает эффективность и стабильность процесса обучения. Более наглядно это можно объяснить так: нейросеть учится разделять типы пространственной деформации, различные для каждого класса.
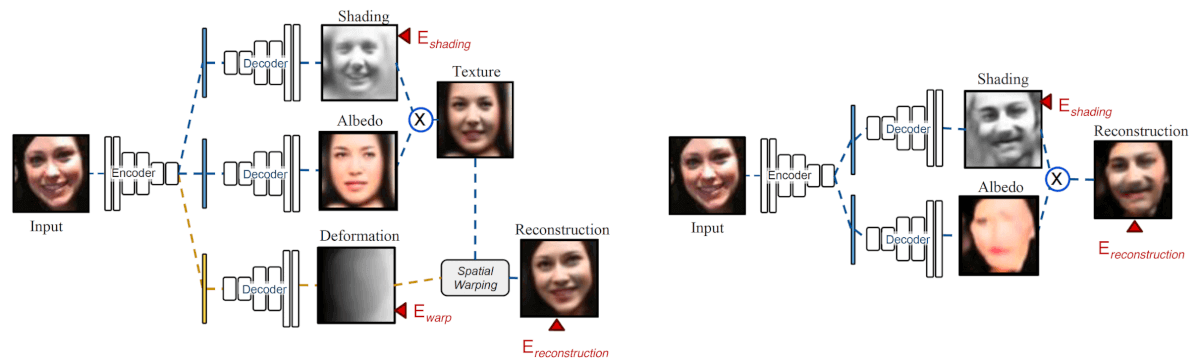
Кроме того, исследователи предлагают использовать свою разработку для вычисления альбедо и теней на портретных изображениях, что является распространенной проблемой машинного зрения. Они называют эту архитектуру Встроенный Деформирующий Автоэнкодер.
Результаты
Было показано, что DAE способен успешно выявлять форму и внешний вид объектов во время обучения. Исследователи показали, что Деформирующие Автоэнкодеры с заданной классификацией дают наилучшие результаты как при восстановлении, так и при изучении внешнего вида объектов.

Помимо качественной оценки, архитектура энкодера оценивалась количественно на основе точности локализации. Метод прошел испытания на:
- Наложении изображений без учителя.
- Изучении семантически важных множеств для формы и внешнего вида объектов.
- Внутренняя декомпозиция без учителя.
- Детектирование локализации без учителя.

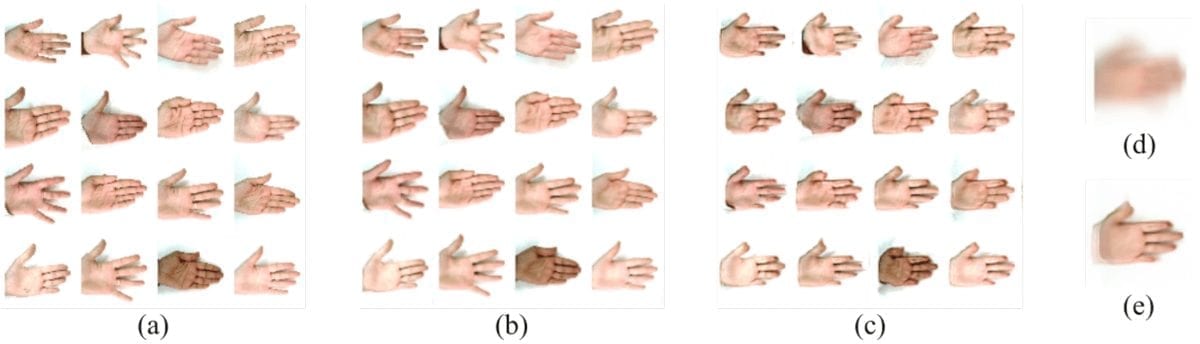


Видео, показывающее возможности Деформирующих Автоэнкодеров:
Сравнение с другими современными методами
Предлагаемый метод прошёл проверку с помощью теста MAFL на основе средней ошибки точности детектирования локализации. Метод превосходит подход, реализованный Thewlis и коллегами.

Заключение

Приведение изображений в каноническую систему координат облегчает оценку альбедо и затенения без дополнительных исследований. Авторы ожидают, что это приведет в будущем к полноценному выявлению признаков (disentanglement) в нормалях, освещении и 3D геометрии.
Исследователи представили Деформирующие Автоэнкодеры как специфичную архитектуру, способную выявлять определённые факторы вариативности – в данном случае это форма и внешний вид объектов. Результаты работы этой модели показывают, что она способна успешно выявлять факторы вариативности посредством применения архитектуры автоэнкодеров, и дают основание полагать, что DAE найдут широкое применение в задачах компьютерного зрения в ближайшем будущем.