Исследователи проекта RIKEN разработали новый метод машинного обучения, который позволяет обучать модели классифицировать объекты без отрицательных данных в обучающем датасете.
В задачах классификации алгоритмы используют положительные и отрицательные данные. Например, если нужно определить улыбку на фотографии, то изображения с улыбающимся человеком будут классифицированы как положительные, а фото человека без улыбки — как отрицательные. Трудность работы с этой технологией в том, что для обучения требуются и те и другие примеры.
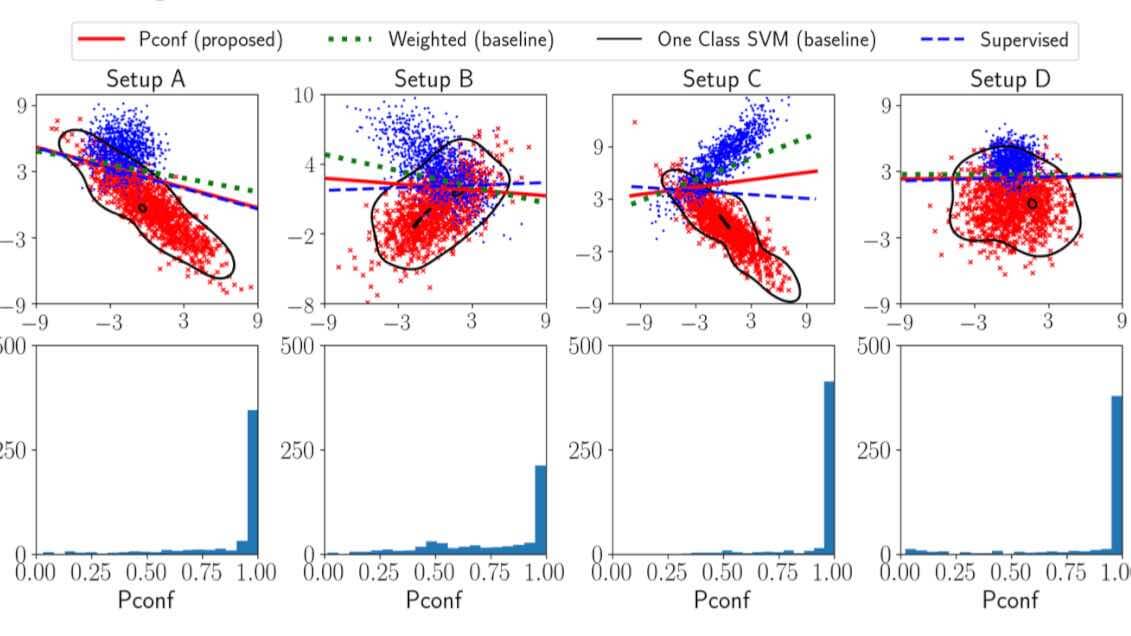
В новом подходе ученые работают только с положительными данными. Такой метод будет полезен в случае, если отрицательные данные для модели невозможно получить. Команда использует показатель доверия (Pconf), который математически высчитывает соответствие вероятности, относится ли результат к положительному классу.
Например, при прогнозировании покупок можно легко получить данные клиентов, которые уже совершили покупку — положительные, но отрицательные получить невозможно, потому что нет информации о людях, которые покупку не совершали. В такой задаче показателем доверия могут выступить данные из опросов существующих клиентов, насколько они готовы совершить подобную покупку у конкурентов. Данные преобразовываются в вероятность 0 или 1 и используются как Pconf.
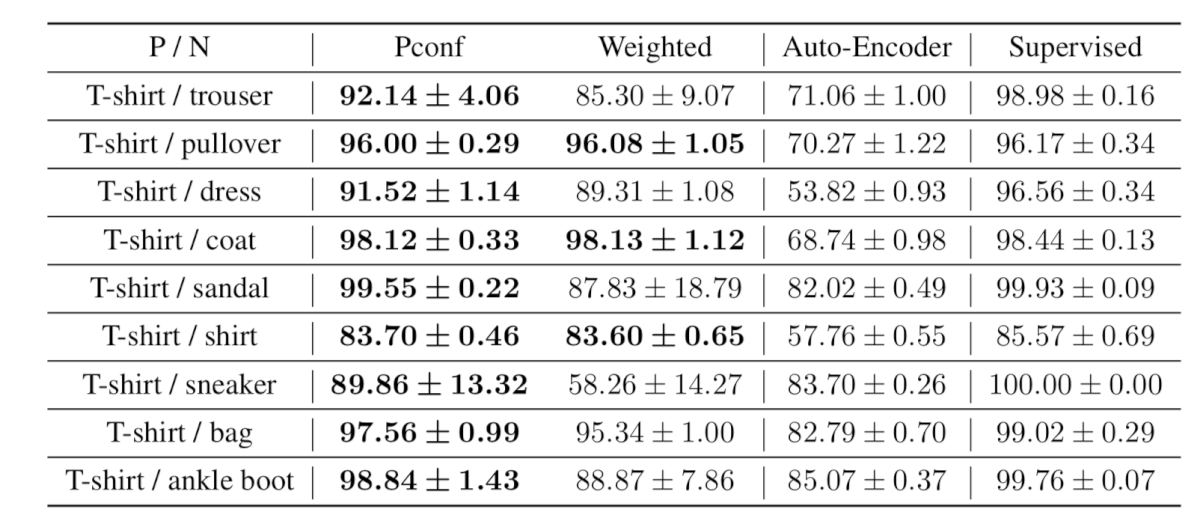
Исследователи протестировали работу метода на датасетах MNIST и The CIFAR-10. Результаты Pconf сопоставимы с другими современными методами классификации, использующими отрицательные данные для обучения. Подход поможет улучшить работу моделей классификации и минимизировать ошибки в случаях, когда невозможно получить отрицательные данные для подготовки.