Bonsai 27B: модель с 27 миллиардами параметров впервые запустили на смартфоне благодаря 1-битным весам
15 июля 2026

Bonsai 27B: модель с 27 миллиардами параметров впервые запустили на смартфоне благодаря 1-битным весам
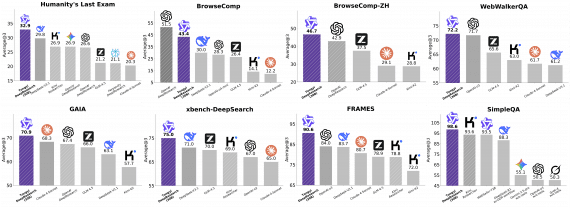
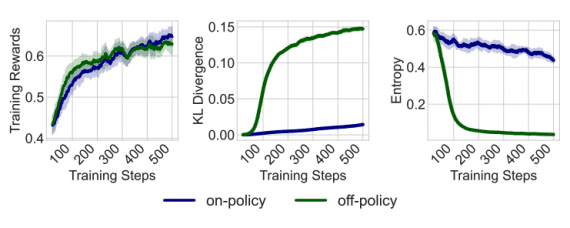
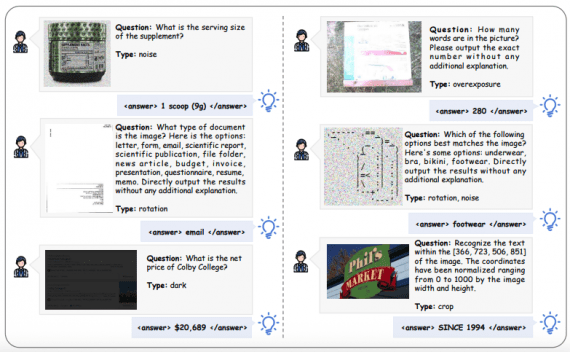
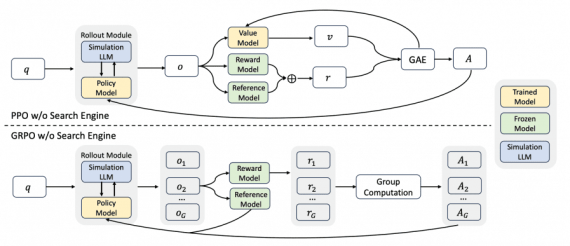
Стартап PrismML, основанный исследователями из Caltech, представил Bonsai 27B — это бинарная и тернарная версии модели Qwen3.6-27B, которые сохраняют 90–95% качества исходной модели при сжатии весов в 9.4–14.2 раза. Тернарная…