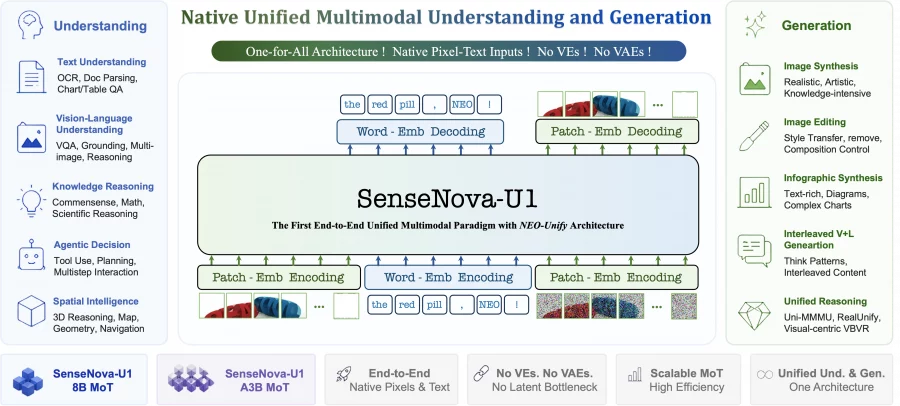
Команда SenseNova представила новую мультимодальную архитектуру SenseNova-U1, которая объединяет понимание изображений, генерацию и редактирование внутри единого трансформера без отдельного визуального энкодера и вариационного автокодировщика. Такой подход убирает необходимость постоянно переводить данные между разными пространствами представлений, из-за чего модель лучше сохраняет визуальные детали, стабильнее работает с текстом внутри изображений и эффективнее объединяет мультимодальное рассуждение с генерацией. На бенчмарках для редактирования изображений компактная версия SenseNova-U1-8B-MoT обходит Qwen-Image, BAGEL, FLUX.1-Kontext и OmniGen, а 30B модель показывает результаты на уровне лучших открытых мультимодальных моделей Qwen2.5-VL и InternVL на задачах мультимодального понимания, OCR и визуального рассуждения.
Авторы выложили код на Github, а веса и чекпоинты моделей опубликовали на Hugging Face. В репозитории уже доступны скрипты для запуска вывода модели, демонстрационные конвейеры обработки, конфигурации моделей и примеры генерации изображений по тексту, редактирования изображений и смешанной генерации текста и изображений. Авторы также выложили готовые примеры запуска моделей через библиотеку Hugging Face Transformers. Отдельно исследователи опубликовали техническое описание архитектуры NEO-unify в блоге Hugging Face.
В Github опубликовано несколько вариантов SenseNova-U1, включая dense- и MoE-версии модели, а также отдельные чекпоинты для мультимодального понимания и генерации.

Почему обычные мультимодальные модели плохо объединяют понимание и генерацию
Авторы начинают с довольно простой мысли. Почти все современные мультимодальные модели состоят из двух независимых частей. За понимание изображения отвечает визуальный энкодер, обычно что-то вроде ViT или CLIP-подобной модели. За генерацию изображения отвечает диффузионная модель с вариационным автокодировщиком. Из-за этого внутри модели появляются два разных пространства признаков.
В результате модель вынуждена постоянно конвертировать данные между разными пространствами представлений. Это создаёт несколько проблем:
- теряется часть визуальной информации во время компрессии скрытого представления;
- понимание и генерация обучаются разными функциями потерь;
- архитектура становится сложнее и тяжелее;
- мультимодальное рассуждение работает хуже из-за разрыва между задачами.
Авторы считают, что проблема тут не только инженерная. Они прямо пишут, что разделение понимания и генерации стало структурным ограничением для развития мультимодального ИИ.
Что именно предлагают авторы
SenseNova-U1 построена на архитектуре NEO-unify. Главная идея заключается в том, чтобы работать напрямую с пикселями и текстом без промежуточных модулей кодирования и декодирования.
Модель использует:
- нативный мультимодальный трансформер;
- сопоставление потоков в пространстве пикселей вместо латентной диффузии;
- единое пространство самовнимания для текста и изображений;
- архитектуру Mixture-of-Transformers;
- генерацию изображений без сильной потери визуальных деталей при сжатии.
Авторы называют это нативной объединённой мультимодальной парадигмой. То есть модель изначально обучается как единая мультимодальная фундаментальная модель, а не как набор соединённых компонентов.
В Github авторы отдельно подчёркивают, что модель работает напрямую с пикселями и текстом без отдельного латентного пространства. Для генерации используется сопоставление потоков в пространстве пикселей с визуальным сжатием 32×, а текст и изображения обрабатываются внутри общей базовой архитектуры трансформера.

Как работает архитектура
Вместо визуального энкодера модель использует очень лёгкое разбиение изображения на патчи. Изображение делится на блоки размером 32×32 пикселя, после чего они напрямую отправляются в трансформер. Для этого используются всего два сверточных слоя с функцией активации GELU.
Интересно, что генерация тоже происходит напрямую в пространстве пикселей. Модель не использует диффузионную голову или вариационный автокодировщик. Вместо этого трансформер сразу предсказывает пиксельные патчи через многослойный перцептрон. Это уменьшает архитектурную сложность и убирает узкое место, которое обычно появляется в латентных диффузионных моделях.
Судя по пайплайну инференса в репозитории, модель действительно работает без классического диффузионного пайплайна в стиле Stable Diffusion. В коде отсутствует отдельный VAE кодер-декодер этап, который обычно используется почти во всех современных диффузных моделях.
На схеме ниже хорошо видно отличие от стандартных подходов.
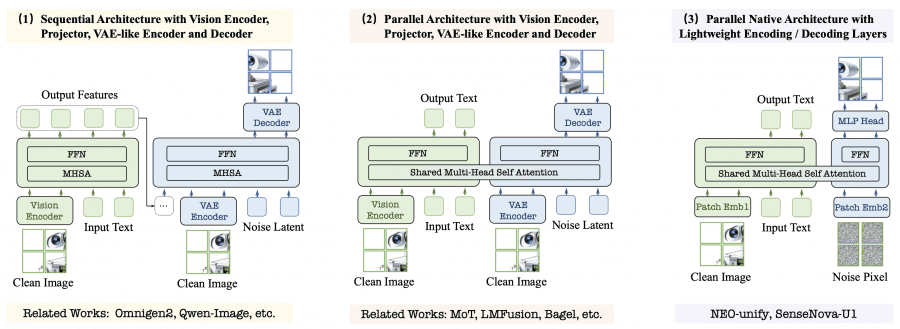
Слева показаны традиционные конвейеры обработки с вариационным автокодировщиком и визуальным энкодером. Справа находится архитектура SenseNova-U1, где текст и изображения обрабатываются внутри единого базового трансформера.
Mixture-of-Transformers вместо обычного трансформера
Ещё одна важная часть работы — Mixture-of-Transformers или смесь трансформеров.
Обычно мультимодальные модели сталкиваются с проблемой конфликтующих градиентов. Когда одна часть модели обучается на визуальных задачах, а другая на языковом моделировании, обновления параметров начинают мешать друг другу. Особенно это заметно при совместном обучении.
В SenseNova-U1 авторы разделяют поток понимания и поток генерации внутри трансформер-слоёв. Внимание остаётся общим, но feed-forward блоки и нормализация разделяются по типу токенов.
Есть три основные версии модели:
- SenseNova-U1-8B-MoT — плотная модель на 8 миллиардов параметров;
- SenseNova-U1-A3B-MoT — модель типа mixture-of-experts с 30 миллиардами параметров и 3 миллиардами активных параметров во время вывода;
- SenseNova-U1-A3B-MoT-SFT — дообученная версия модели с 30 миллиардами параметров и 3 миллиардами активных параметров после контролируемого дообучения для мультимодального взаимодействия, генерации и редактирования изображений.
Технические параметры моделей:
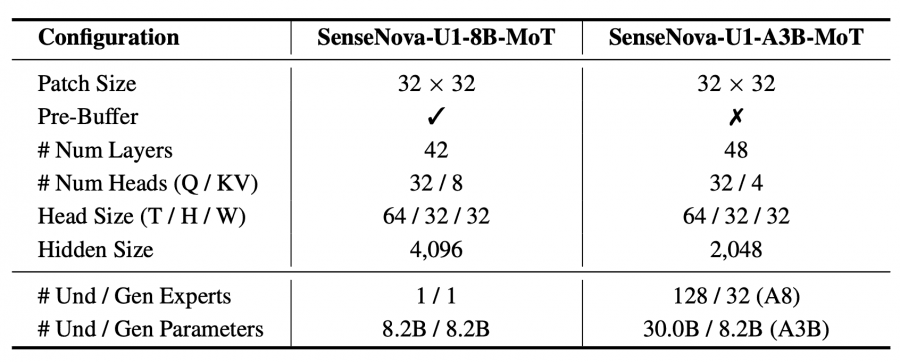
В MoE-версии используется top-k routing с активацией только 8 экспертов на токен. Это снижает стоимость вывода и позволяет масштабировать мультимодальную модель эффективнее обычного плотного трансформера.
В репозитории видно, что вывод для A3B-MoT использует потоковую маршрутизацию mixture-of-experts. Во время работы модели активируется только часть экспертов, поэтому модель с 30 миллиардами параметров требует значительно меньше вычислений, чем обычный плотный трансформер такого же размера.
Как обучали модель
Обучение разделили на четыре больших этапа.
Сначала идёт этап предварительного обучения пониманию. На этом этапе модель обучается мультимодальному пониманию на текстах и изображениях.
Потом начинается предварительное обучение генерации. Здесь ветка генерации учится напрямую генерировать пиксельные патчи c обучением через flow matching.
После этого запускается совместное мультимодальное обучение, где понимание и генерация обучаются совместно внутри одной архитектуры. Финальный этап — supervised fine-tuning, или контролируемое дообучение.
Интересно, что генерация работает через сопоставление потоков в пространстве пикселей, а не через латентное диффузионное пространство. Формально функция потерь выглядит так::
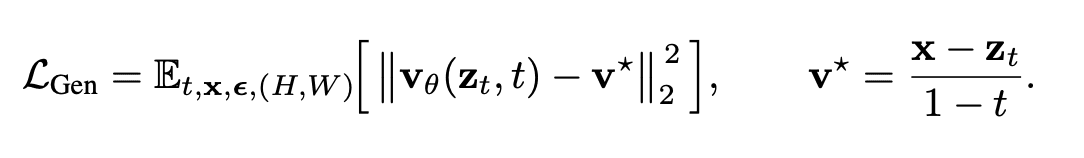
Это стандартная функция среднеквадратичной ошибки для предсказания скорости внутри flow matching framework. Авторы утверждают, что такой подход лучше сохраняет визуальное качество и семантическую согласованность.
Что умеет модель
Авторы тестировали модель на нескольких типах задач:
- ответы на вопросы по изображениям;
- распознавание текста и разбор документов;
- генерация изображений по тексту;
- редактирование изображений;
- смешанная генерация текста и изображений;
- генерация инфографики;
- пространственное рассуждение.
Особенно интересно выглядит генерация инфографики. Большинство диффузионных моделей плохо работают с текстом внутри изображений. У них возникают артефакты, неправильные символы и сломанная структура.
SenseNova-U1 показывает заметно более стабильную генерацию изображений с большим количеством текста. Это связано с тем, что текст и изображения обрабатываются внутри единого авторегрессионного пространства трансформера.
В Github авторы показывают примеры генерации инфографики, презентаций, комиксов, сложных layout и text-heavy image generation. Это одна из самых сильных сторон модели, потому что большинство open-source diffusion model всё ещё плохо работают с длинным текстом внутри изображения.
Примеры редактирования изображений и смешанной генерации текста и изображений моделью SenseNova-U1:


Результаты на бенчмарках
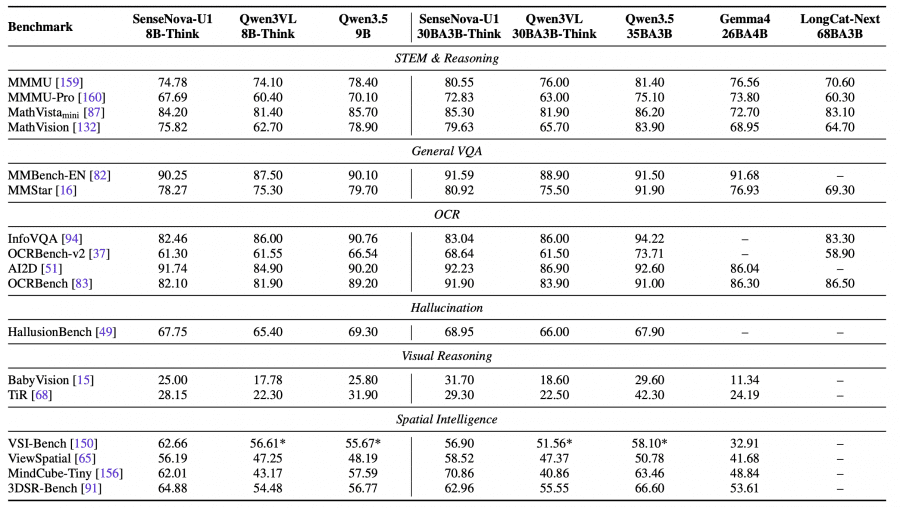
Авторы сравнили SenseNova-U1 с GPT-4o, Gemini 2.5 Pro, Qwen2.5-VL, Qwen-Image, BAGEL, InternVL-U, OmniGen и FLUX.1-Kontext на бенчмарках для мультимодального понимания, визуального рассуждения, распознавания текста, генерации изображений и редактирования изображений.
SenseNova-U1-A3B-MoT показывает результаты уровня лучших открытых VLM на задачах понимания и рассуждения. Модель набирает:
-
- 94.9 на OCRBench;
- 87.3 на MMBench;
- 74.1 на MathVista;
- 68.8 на MMMU;
- 96.1 на DocVQA.
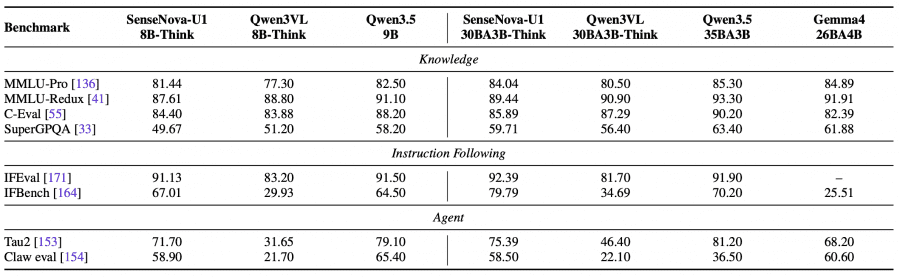
Топ-1 результат на GenEval:
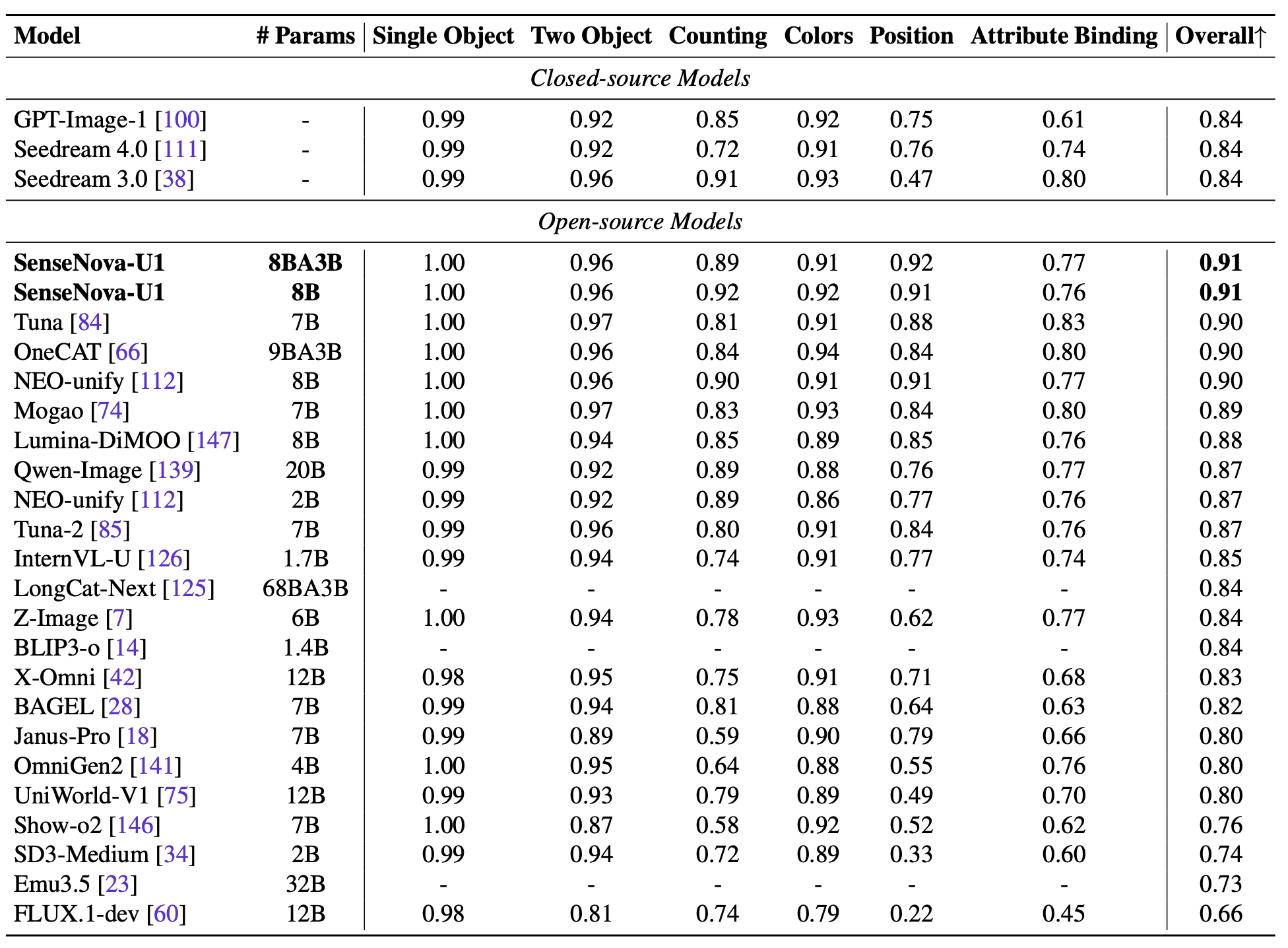
На задачах image editing и генерации изображений модель также показывает сильные результаты. Особенно заметен отрыв на benchmark с большим количеством текста внутри изображения и сложным layout.
На RISEBench результаты такие:
- SenseNova-U1-8B-MoT — 58.2;
- SenseNova-U1-A3B-MoT — 57.4;
- Qwen-Image-Edit-2511 — 49.9;
- BAGEL — 36.5;
- FLUX.1-Kontext-Dev — 26.0;
- OmniGen — 22.0.
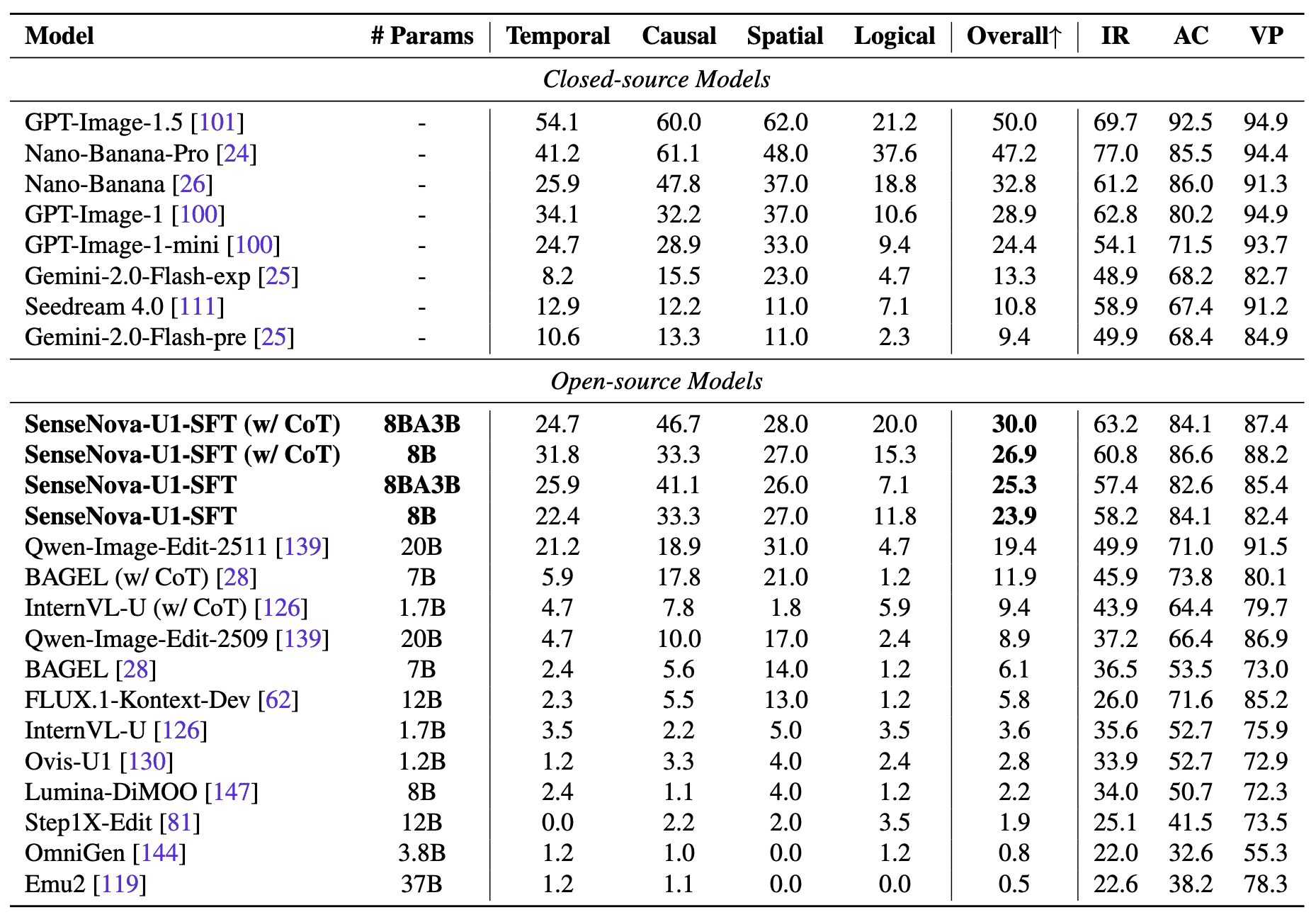
Авторы отдельно подчёркивают, что модель хорошо справляется с interleaved generation — задачами, где нужно одновременно генерировать текст, изображения, схемы и layout внутри одного документа.
В ablation study авторы показывают, что отказ от VAE и VE действительно помогает одновременно сохранять и семантику изображения, и мелкие визуальные детали.
Почему это важно
Сейчас большинство компаний, работающих с ИИ, движутся в сторону универсальных мультимодальных моделей. Gemini, Qwen-Image, BAGEL и другие модели постепенно объединяют понимание изображений и генерацию.
Но у многих решений всё ещё сохраняется разделение между визуальным энкодером и диффузионным конвейером генерации. SenseNova-U1 интересна тем, что пытается полностью убрать это разделение.
Авторы фактически проверяют гипотезу, что мультимодальный интеллект может возникать внутри единой базовой архитектуры трансформера без специальных промежуточных пространств представлений.
Отдельно интересно, что авторы уже выложили публичное демо с мультимодальным взаимодействием, генерацией изображений и редактированием изображений прямо в браузере. Для open-weight мультимодальной модели такого масштаба это пока редкость.
Пока это ещё не идеальная универсальная мультимодальная модель. Но работа показывает, что моделирование напрямую в пространстве пикселей начинает конкурировать с латентной диффузией даже на сложных задачах генерации и мультимодального рассуждения.
Работа показывает, что мультимодальные модели постепенно движутся к объединению генерации, понимания и языкового моделирования внутри одной архитектуры.







Неплохо, посмотрим как это будет развиваться, выглядит достаточно перспективно