21 апреля 2026 года OpenAI выпустила ChatGPT Images 2.0 на базе модели gpt-image-2. По данным LM Arena, новая модель сразу заняла первое место во всех категориях генерации изображений с отрывом +242 балла Elo от ближайшего конкурента — прежде всего за счёт почти идеального рендеринга текста на нескольких языках и точного следования сложным инструкциям.
Главное техническое нововведение — интеграция механизма reasoning из O-серии. Перед тем как начать генерацию, модель планирует композицию, проверяет количество объектов и ограничения промпта. В ChatGPT это называется thinking mode и доступно подписчикам Plus, Pro и Business. Через API параметр thinking принимает три уровня: low, medium и high. Стандартный режим без рассуждений доступен всем пользователям ChatGPT бесплатно. API открыт для всех зарегистрированных разработчиков OpenAI.
Примеры генераций
Все генерации выполнены в бесплатном режиме ChatGPT без включения механизма рассуждений. В описании изображения указан промпт.





История линейки: от GPT Image 1 до версии 2.0
Чтобы понять масштаб изменений, стоит вспомнить, как развивалась эта линейка. GPT Image 1 появился в марте 2025 года как нативная функция генерации изображений в GPT-4o. За первую неделю 130 миллионов пользователей создали более 700 миллионов изображений, а Sam Altman написал, что «GPU буквально плавятся». В декабре 2025 года вышел GPT Image 1.5 с улучшенным следованием инструкциям и более точной цветопередачей, который занял второе место в рейтинге LM Arena. Теперь вышел gpt-image-2, который OpenAI позиционирует не как генератор-игрушку, а как полноценный инструмент для визуальных рабочих процессов.
Параллельно 12 мая 2026 года OpenAI планирует отключить DALL-E 2 и DALL-E 3 — это официальный сигнал о том, что gpt-image-2 становится основной производственной заменой всего предыдущего поколения.
Технические характеристики GPT-Image-2: что изменилось
Главное принципиальное отличие gpt-image-2 от предшественников — не просто улучшенная отрисовка, а полностью переработанная архитектура. Руководитель исследований Boyuan Chen подтвердил, что архитектура была «переработана с нуля», хотя и отказался уточнять, использует ли модель традиционный диффузионный или авторегрессионный подход. Самое существенное нововведение — интеграция механизма reasoning из O-серии, что делает gpt-image-2 первой image-моделью с нативными возможностями рассуждения (thinking).
Ниже сравнение ключевых параметров с предыдущей версией:
| Характеристика | gpt-image-1 | gpt-image-2 |
|---|---|---|
| Максимальное разрешение | 1024 пикс. | 2000 пикс. по длинной стороне |
| Форматы кадра (aspect ratio) | 1:1, 3:2, 2:3 | 1:1, 3:2, 2:3, 16:9, 9:16, 3:1, 1:3 |
| Изображений за один запрос | 1 | до 10 (с сохранением стилевой согласованности) |
| Отрисовка текста | только английский, часто с ошибками | мультиязычный, включая кириллицу, CJK, индийские шрифты |
| Режим reasoning | нет | есть (параметр thinking) |
| Веб-поиск при генерации | нет | есть, в режиме thinking |
| Дата среза знаний | — | декабрь 2025 |
Модель получила обновлённый срез знаний на декабре 2025 года, что позволяет генерировать более точные и контекстуально релевантные изображения. Это особенно важно для инфографики, образовательных материалов и визуальных объяснений, где точность не менее важна, чем эстетика.
Режим Thinking: «сначала подумать, потом нарисовать»
Режим thinking — это, пожалуй, самое интересное нововведение с технической точки зрения. Модель gpt-image-2 читает промпт, планирует компоновку, отрисовывает чёткий мультиязычный текст и может генерировать до десяти изображений за один запрос с разрешением до 2000 пикселей в широком наборе форматов кадра, которые не поддерживала предыдущая версия.
Параметр thinking имеет три уровня: low, medium и high. Они балансируют между задержкой генерации и точностью компоновки. Для схем, таблиц и любых изображений с числами рекомендуется уровень medium как наиболее практичный. В режиме thinking модель также может обращаться к веб-поиску прямо во время генерации — это помогает, например, при создании инфографики с реальными данными или карт с корректными метками.
Вот как выглядит базовый запрос к API с включённым reasoning:
curl https://api.openai.com/v1/images/generations
-H "Authorization: Bearer $OPENAI_API_KEY"
-H "Content-Type: application/json"
-d '{
"model": "gpt-image-2",
"prompt": "Четырёхпанельная инфографика по OAuth 2.1, стрелки подписаны на русском и японском языках.",
"size": "2000x1000",
"n": 1,
"quality": "high",
"thinking": "medium"
}'Важный нюанс по стоимости: мышление тарифицируется отдельно по reasoning-токенам. Схема с жёстким требованием к компоновке обойдётся дороже, чем свободная иллюстрация.
Ценообразование и доступность GPT-Image-2
Для разработчиков модель доступна через API с reasoning-режимом, поторочным ценообразованием и той же структурой endpoint, что используется в production. Стоимость токенов по официальной странице ценообразования OpenAI: $5 за миллион входных текстовых токенов, $10 за миллион выходных текстовых токенов, $8 за миллион входных image-токенов и $30 за миллион выходных image-токенов. При стандартном качестве в 1024×1024 это примерно $0.21 за изображение — на 60% дороже, чем gpt-image-1, что объясняется большим холстом и шагом reasoning.
По доступности: стандартный gpt-image-2 доступен бесплатным пользователям ChatGPT. Thinking-режим, расширенный reasoning и веб-поиск во время генерации — только для подписчиков Plus, Pro и Business. API-доступ привязан к аккаунту разработчика OpenAI.
Модель также доступна внутри Codex, среды разработки OpenAI, что позволяет создавать визуальные материалы в том же рабочем пространстве, где пишется код, верстаются презентации и другие артефакты.
Что показывают бенчмарки
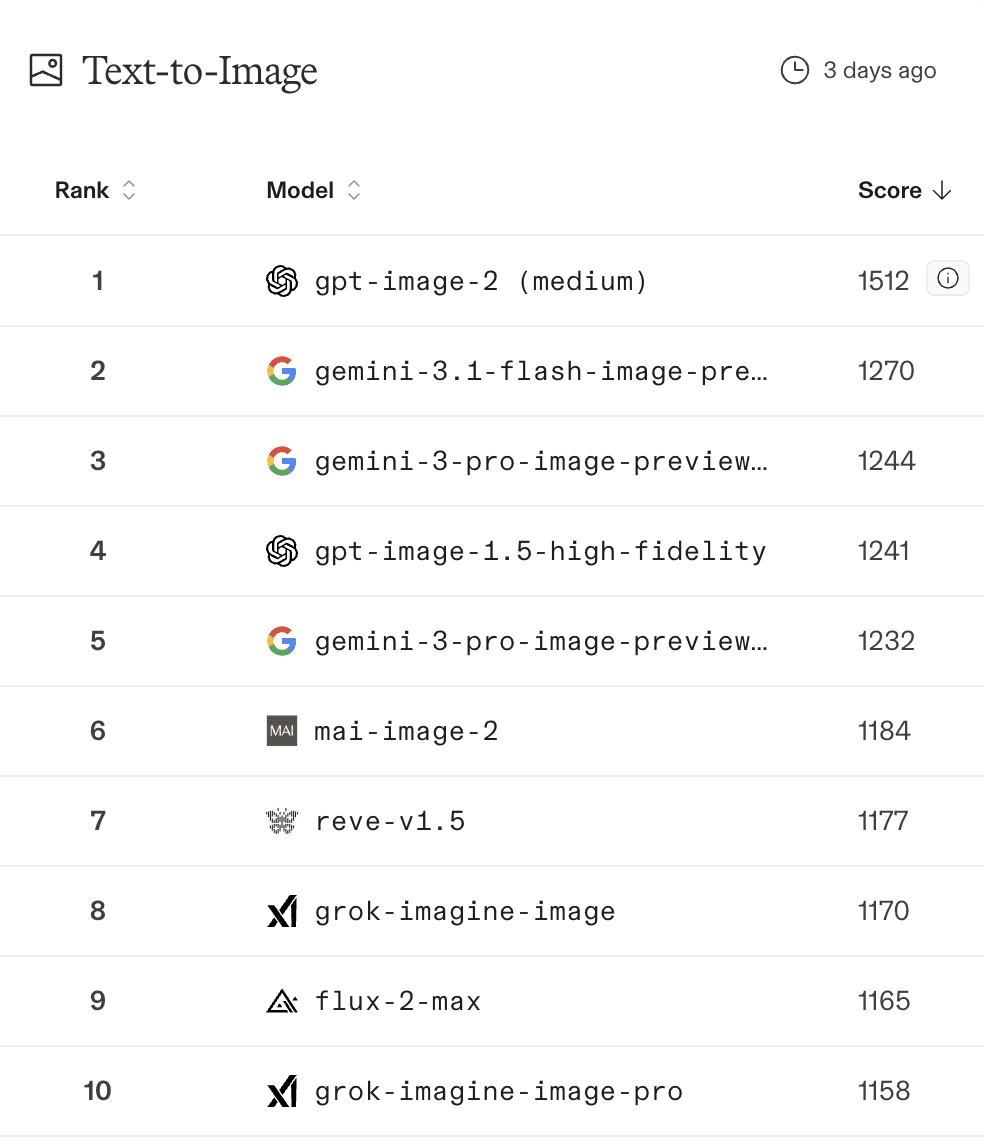
По данным Arena, gpt-image-2 занимает первое место во всех категориях Image Arena Leaderboard: 1512 баллов в text-to-image, 1513 в редактировании одного изображения и 1464 в редактировании нескольких изображений, с отрывом +242 балла Elo от ближайшего конкурента по text-to-image. Это очень существенный разрыв: в рейтинговой системе Elo разница в 242 балла означает приблизительно 80% вероятность победы в слепом сравнении.
Независимые реакции разработчиков в X сошлись на одном тезисе: это не просто более красивая генерация, а принципиально более полезная модель для UI-макетов, документации, продуктовой визуализации и итеративных дизайн-циклов. Наиболее интересное системное следствие — image-генерация начинает работать как frontend для агентов-кодировщиков: сгенерировать визуальную спецификацию UI, а затем передать её Claude Code или другому код-агенту как референс для реализации.
Реакция сообщества: что говорят пользователи
Реакция в X и AI-сообществах оказалась в целом очень положительной, хотя и с оговорками. Пользователи ждали этого релиза уже несколько недель. Модель называли «GPT-image-2» на Reddit и в X задолго до официального релиза. Ранее в апреле пользователь Reddit сообщил, что OpenAI уже тестирует модель в ChatGPT на ограниченной аудитории.
Из конкретных примеров, которые разошлись в сообществе: манга-комиксы с повторяющимися персонажами и развивающимся сюжетом, персонализированные версии «Где Уолдо?», полные страницы журналов с точно читаемыми текстовыми блоками. Ранние тестировщики особо отметили точность UI-макетов и отрисовку текста как главные практические преимущества модели.
Figma, Canva, Adobe Firefly и fal уже объявили о начале интеграции gpt-image-2 в свои продукты в день релиза — это говорит о том, что модель воспринимается как инфраструктурный инструмент, а не только как feature в ChatGPT.
Из честной критики: фотореалистичные лица при крупном кадре по-прежнему дают артефакты. Точные Brand assets (конкретная геометрия логотипа) ненадёжны. Длинные текстовые блоки (полные абзацы внутри изображения) разваливаются после нескольких сотен символов. Стилевая согласованность сохраняется внутри одного пакетного запроса, но между отдельными сессиями — нет.
Сравнение с конкурентами
До релиза gpt-image-2 в рейтинге LM Arena для text-to-image лидировала модель Google Gemini, а gpt-image-1.5 занимал второе место. С выходом gpt-image-2 расклад изменился: по данным Arena, новая модель OpenAI вышла на первое место с существенным отрывом. Основные конкуренты в пространстве reasoning + image на данный момент: Google Nano Banana 2 (вышел чуть раньше) и набор open-weight мультимодальных моделей, которые сокращают разрыв в отрисовке текста.
Практический выбор для разработчиков: gpt-image-2 предпочтителен, если нужна точность отрисовки текста, reasoning над компоновкой и интеграция с остальным стеком OpenAI. Open-weight мультимодальные альтернативы выигрывают по стоимости за изображение, возможности self-hosting и разрешительным лицензиям для коммерческих выходных данных.
Итог
gpt-image-2 — первая попытка применить reasoning к задаче генерации изображений в промышленном масштабе. Модель перестала быть «генератором картинок» и стала ближе к инструменту, который понимает задачу визуально: планирует слайды, собирает инфографику, пишет корректный текст на нескольких языках и самостоятельно проверяет результат. Это принципиально другой класс задач по сравнению с тем, что умели DALL-E и GPT Image 1.
Отрыв в 242 балла Elo на арене и мгновенные интеграции от Figma, Canva и Adobe в день релиза — хороший индикатор того, что рынок воспринимает модель как производственный инструмент, а не академическую демонстрацию. Реальные ограничения (фотореалистичные лица, точные логотипы, многостраничный связный текст) остаются, но область применения уже сейчас значительно шире, чем у предшественников.