
Исследователи из Шанхайского университета Цзяо Тун доказали, что для создания лучшего в своём классе deep research агента не нужны сотни миллиардов токенов предобучения и дорогостоящее обучение с подкреплением. Достаточно 10 600 правильно подобранных обучающих примеров, сгенерированных полностью автоматически без участия людей-разметчиков, и одного прохода дообучения на размеченных данных. Их модель OpenSeeker-v2 побила Tongyi DeepResearch от Alibaba на всех четырёх бенчмарках, хотя Alibaba использовала трёхэтапный пайплайн, где только этап непрерывного предобучения (CPT) требует обработки сотен миллиардов токенов. OpenSeeker-v2 обучили за один этап, без предобучения и без обучения с подкреплением. Проект полностью открытый: веса модели доступны на Hugging Face, а код обучения и код генерации обучающих данных — на GitHub.
Зачем нужны deep research агенты
Обычный поисковик возвращает список ссылок — дальше человек сам читает, сопоставляет и делает выводы. Deep research агент делает это самостоятельно: получает сложный вопрос, формулирует цепочку поисковых запросов, переходит по ссылкам, читает страницы, сопоставляет противоречивые источники и собирает итоговый ответ из десятков документов. Например, на вопрос «какие компании получили государственные субсидии на разработку ИИ-чипов в Европе за последние два года и каков их суммарный объём» нельзя ответить одним поиском — нужно обойти множество источников, проверить данные и сложить всё в единый ответ. Именно это умеют делать deep research агенты.
Но до сих пор их разработкой занимались только крупные компании вроде Alibaba или OpenAI, у которых есть ресурсы на многоэтапный пайплайн обучения: сначала CPT на сотнях миллиардов токенов, потом SFT (дообучение на размеченных данных), а в конце RL (обучение с подкреплением) для тонкой настройки на основе обратной связи. Такой пайплайн требует огромных вычислительных мощностей и закрытых корпусов данных, что делает его недоступным для университетских лабораторий.
Авторы OpenSeeker-v2 задались вопросом: а что если дело не в сложности пайплайна, а в качестве обучающих данных? Если дать модели достаточно сложные и информативные примеры, может, хватит и одного SFT?
Как устроена модель и обучение
OpenSeeker-v2 построен на базе Qwen3-30B-A3B-Thinking-2507 — модели с 30 миллиардами параметров, где при генерации ответа активируется только 10% из них. Это архитектура смеси экспертов (MoE, mixture-of-experts): модель большая, но на каждый запрос задействует лишь часть своих весов, что заметно снижает вычислительные затраты. Контекстное окно составляет 256k токенов, а на одну задачу агент может совершить до 200 вызовов инструментов.
Агент работает по парадигме ReAct: на каждом шаге он формулирует рассуждение, выбирает инструмент, получает результат и переходит к следующему шагу. Так продолжается до тех пор, пока агент не придёт к финальному ответу.
Обучали модель на 10 600 примерах решения задач — без RL и без дополнительного предобучения.
Все обучающие данные генерировали полностью автоматически, без участия людей-разметчиков и без покупки внешних датасетов. Процесс выглядит так: берётся граф знаний, вокруг случайного узла строится подграф, на его основе автоматически генерируется вопрос, затем агент ищет ответ в интернете — и вся последовательность его шагов записывается как обучающий пример. Это одна из причин, почему подход доступен университетским командам: не нужен бюджет на разметку данных.
По сравнению с предыдущей версией в процессе генерации данных изменили три вещи:
- Увеличили граф знаний. Для генерации задач используется граф G = (V, E), где вокруг каждого начального узла строится локальный подграф. В OpenSeeker-v2 размер этого подграфа увеличили: чем больше граф, тем богаче контекст и тем сложнее задача — модель вынуждена искать ответ не в одном документе, а выстраивать цепочку переходов между несколькими источниками (multi-hop reasoning).
- Расширили набор инструментов. Агент получил доступ к большему числу инструментов, чем в первой версии. Это позволяет модели учиться более разнообразным стратегиям поиска и обработки информации.
- Выбросили простые задачи. Из обучающего набора убрали все примеры, где агент решал задачу меньше чем за T_min шагов: D_v2 = {(q, τ) ∈ D_raw | T(τ) ≥ T_min}. Задачи, решаемые одним поиском, в обучение не попадают — только те, где нужно думать долго.

Результаты на бенчмарках
Модель проверяли на четырёх бенчмарках, которые замеряют способность агента искать и обобщать информацию из интернета. BrowseComp и BrowseComp-ZH (китайская версия) — задачи на глубокий поиск с однозначными ответами. Humanity’s Last Exam (HLE) — 3000 вопросов экзаменационного уровня из разных областей знаний. xbench-DeepSearch — проверка качества глубокого исследования.
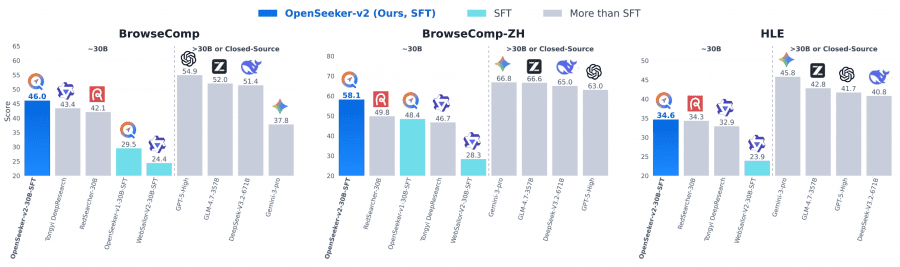
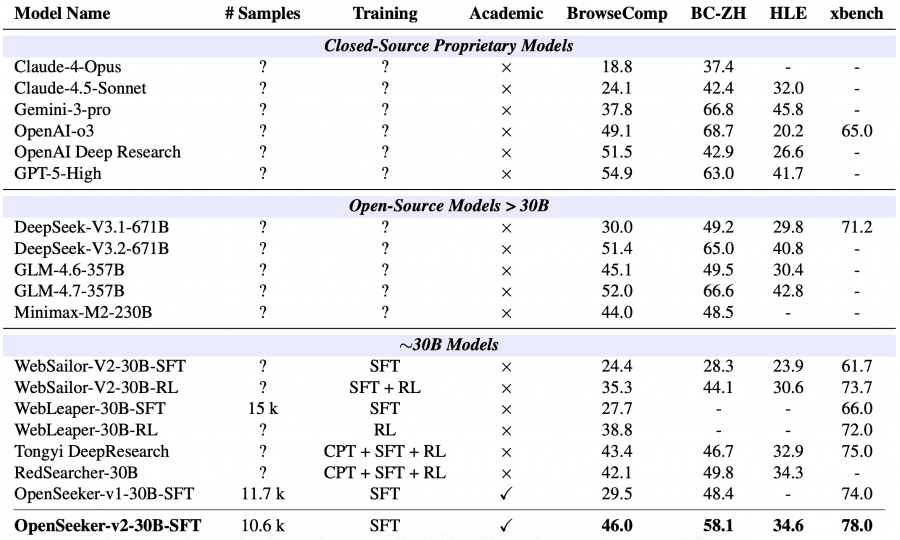
Среди агентов масштаба около 30 миллиардов параметров с парадигмой ReAct OpenSeeker-v2 занял первое место на всех четырёх бенчмарках: 46.0% на BrowseComp, 58.1% на BrowseComp-ZH, 34.6% на HLE и 78.0% на xbench. Tongyi DeepResearch от Alibaba с полным пайплайном CPT+SFT+RL набрал 43.4%, 46.7%, 32.9% и 75.0% соответственно. Отрыв на BrowseComp-ZH особенно заметный — 11.4 процентных пункта.
Кроме того, OpenSeeker-v2 обошёл несколько значительно более крупных универсальных моделей: DeepSeek-V3.1-671B набрал 30.0% на BrowseComp, GLM-4.6-357B — 45.1%, Minimax-M2-230B — 44.0%, Claude-4.5-Sonnet — 24.1%. Ни одна из них не заточена специально под глубокий поиск, но сам факт показателен: специализированный deep research агент на 30B параметров бьёт универсальные модели в 10 и более раз большего размера на профильных задачах.
Почему это работает: роль качества данных
Главный вывод работы — при достаточно высоком качестве обучающих примеров SFT не уступает сложным многоэтапным пайплайнам с RL. Авторы объясняют это так: длинные и трудные примеры вынуждают модель учиться планировать поиск на много шагов вперёд и не останавливаться на полпути. OpenSeeker-v2 в среднем делает 64.67 вызовов инструментов на одну задачу — заметно больше, чем у конкурентов.
По сравнению с OpenSeeker-v1, при том же масштабе модели и том же методе обучения, результат вырос: на BrowseComp с 29.5 до 46.0, на BrowseComp-ZH с 48.4 до 58.1, на xbench с 74.0 до 78.0. Потолок SFT-подхода явно ещё не достигнут — качество обучающих данных остаётся главным рычагом роста.
Что дальше
Внутренние эксперименты авторов показывают, что результаты продолжают расти при увеличении объёма и разнообразия обучающих данных. Следующий шаг — масштабировать обучающий набор, сохраняя высокую сложность задач.
OpenSeeker-v2 показывает, что для создания передового deep research агента не нужна корпоративная инфраструктура. Университетская команда с ограниченными ресурсами, но с правильно подобранными обучающими данными, способна обойти промышленные решения — а это открывает дорогу для независимых исследований в области LLM-агентов.







