
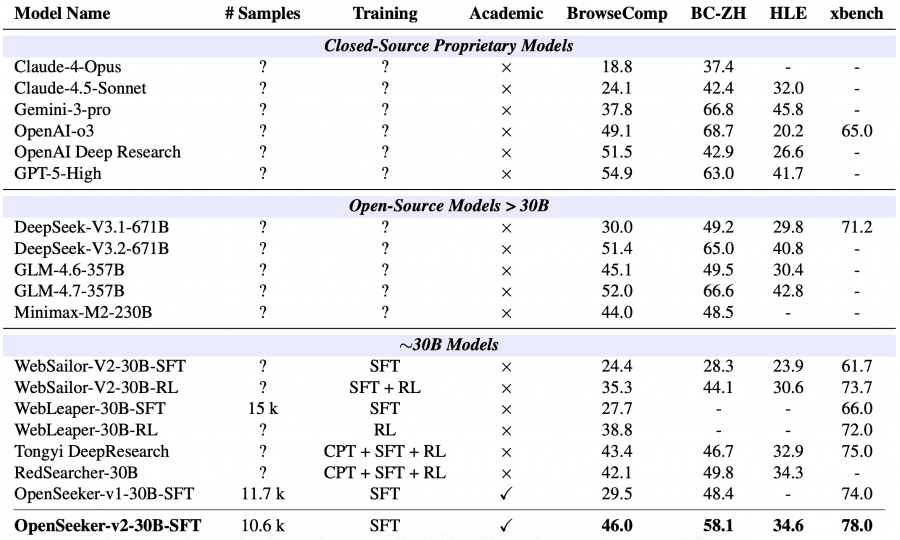
Researchers from Shanghai Jiao Tong University have proven that building a best-in-class deep research agent doesn’t require hundreds of billions of pre-training tokens or expensive reinforcement learning. Just 10,600 carefully curated training samples, generated entirely automatically without human annotators, and a single SFT run. Their model OpenSeeker-v2 outperformed Tongyi DeepResearch from Alibaba on all four benchmarks, even though Alibaba used a three-stage pipeline: CPT (continual pre-training — an additional pre-training stage on hundreds of billions of domain-specific tokens to instill agentic priors before fine-tuning) + SFT + RL. OpenSeeker-v2 was trained in a single SFT stage, skipping CPT and RL entirely. The project is fully open-source: model weights are available on Hugging Face, and the training code and data generation code are on GitHub.
Why Deep Research Agents Matter
A regular search engine returns a list of links — the user then reads, compares, and draws conclusions on their own. A deep research agent does this autonomously: it receives a complex query, formulates a chain of search queries, follows links, reads pages, reconciles contradictory sources, and assembles a final answer from dozens of documents. For example, the query “which companies received government subsidies for AI chip development in Europe over the past two years, and what is the total amount” can’t be answered with a single search — you need to gather data from many sources, verify it, and synthesize it into a unified answer. That’s exactly what deep research agents do.
Until now, only large companies like Alibaba or OpenAI had the resources for this — they rely on a multi-stage training pipeline: first CPT on hundreds of billions of tokens to build agentic foundations, then SFT (supervised fine-tuning) on curated demonstrations of correct behavior, and finally RL (reinforcement learning) for policy optimization based on reward signals. Such a pipeline requires enormous compute and proprietary data, putting it out of reach for academic labs.
The authors of OpenSeeker-v2 asked a different question: what if it’s not about pipeline complexity, but about training data quality? If you provide the model with sufficiently complex and informative samples, is a single SFT run enough?
Model Architecture and Training
OpenSeeker-v2 is built on Qwen3-30B-A3B-Thinking-2507 — a model with 30 billion total parameters where only 10% are activated during inference. This is a mixture-of-experts (MoE) architecture: the model is large, but only a fraction of its weights are engaged per forward pass, significantly reducing inference compute. The context window is 256k tokens, and the agent can make up to 200 tool calls per task.
The agent operates under the ReAct paradigm: at each step it produces a reasoning trace, selects a tool call, receives an observation, and moves to the next step. This continues until the agent produces a final answer.
The model was trained on 10,600 task samples — without RL and without CPT.
All training data was generated fully automatically, without human annotators and without purchasing external datasets. The pipeline works as follows: a knowledge graph is taken, a subgraph is built around a random seed node, a question is generated from it, then the agent searches for the answer on the web — and the entire sequence of its steps is recorded as a training sample. This is one reason the approach is accessible to academic teams: no data annotation budget required.
Compared to the previous version, three changes were made to the data generation pipeline:
- Scaled up the knowledge graph. Task generation uses a graph G = (V, E), where a local subgraph is built around each seed node. In OpenSeeker-v2, the subgraph expansion budget was increased: the larger the subgraph, the richer the context and the harder the task — the model is forced to find answers not in a single document, but by performing multi-hop reasoning across multiple sources.
- Expanded the tool set. The agent now has access to a larger set of tools than in v1, allowing the model to learn more diverse retrieval and information processing strategies.
- Filtered out low-difficulty samples. All samples where the agent solved the task in fewer than T_min tool-call steps were discarded: D_v2 = {(q, τ) ∈ D_raw | T(τ) ≥ T_min}. Samples solvable via shallow keyword matching don’t make it into training — only those requiring long-horizon reasoning.

Benchmark Results
The model was evaluated on four benchmarks measuring an agent’s ability to search and synthesize information from the web. BrowseComp and BrowseComp-ZH (Chinese version) test deep search with unambiguous answers. Humanity’s Last Exam (HLE) consists of 3,000 expert-level questions across various domains. xbench-DeepSearch evaluates deep research quality.
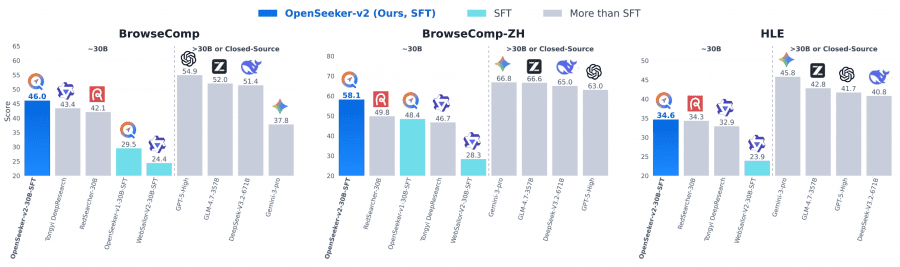
Among ~30B-parameter agents using the ReAct paradigm, OpenSeeker-v2 achieved state-of-the-art performance on all four benchmarks: 46.0% on BrowseComp, 58.1% on BrowseComp-ZH, 34.6% on HLE, and 78.0% on xbench. Tongyi DeepResearch from Alibaba, trained with a full CPT+SFT+RL pipeline, scored 43.4%, 46.7%, 32.9%, and 75.0% respectively. The gap on BrowseComp-ZH is particularly notable — 11.4 percentage points.
OpenSeeker-v2 also outperformed several much larger general-purpose models: DeepSeek-V3.1-671B scored 30.0% on BrowseComp, GLM-4.6-357B — 45.1%, Minimax-M2-230B — 44.0%, Claude-4.5-Sonnet — 24.1%. None of these models are specialized for deep search, but the result is telling: a specialized 30B deep research agent outperforms general-purpose models more than 10x its size on domain-specific benchmarks.
Why It Works: The Role of Data Quality
The key finding is that with sufficiently high-quality training samples, SFT is competitive with complex multi-stage RL pipelines. The authors attribute this to the following: long and difficult samples force the model to learn long-horizon search planning and sustained multi-step reasoning. OpenSeeker-v2 averages 64.67 tool calls per task — noticeably more than competing models in the training data.
Compared to OpenSeeker-v1, using the same model scale and training recipe, scores improved substantially: BrowseComp from 29.5 to 46.0, BrowseComp-ZH from 48.4 to 58.1, xbench from 74.0 to 78.0. The performance ceiling of the SFT-only approach has clearly not been reached — training data quality remains the primary scaling lever.
What’s Next
The authors’ internal experiments suggest strong scaling potential as training data volume and diversity increase. The next step is scaling up the training set while preserving high task difficulty.
OpenSeeker-v2 demonstrates that building a frontier deep research agent doesn’t require corporate infrastructure. An academic team with limited resources but carefully designed training data can match and exceed industrial solutions — lowering the barrier to entry for independent research on LLM agents.
Read also: Claude Code: Getting Started Guide






