
A team of researchers from CUHK MMLab published OpenGame — the first agentic framework for creating browser-based 2D games from natural language descriptions. The project is fully open: the framework code, GameCoder-27B model weights, and datasets are available on GitHub, with more details on the project page. A user writes something like “I want a ninja platformer with a double jump,” and the agent independently generates code, assets, and music. It sounds simple, but the engineering behind it is quite complex.

Why This Is Hard
This may seem obvious, but it is worth spelling out. Creating a game is fundamentally different from writing ordinary code. A game is not a single file but an interconnected multi-file structure where the engine, physics, assets, and logic must all work in strict coordination. The authors identify three main reasons why standard language models fail at this.
First — logical incoherence: the model loses track of the global game loop state, and the project freezes or never launches. Second — engine ignorance: models ignore the ready-made abstractions of the Phaser framework and rewrite everything from scratch, producing broken code. Third — cross-file inconsistencies: even when individual files look correct, the project breaks due to mismatched asset keys, improper scene initialization, or missing configuration fields. OpenGame is designed to address exactly this set of problems.
How OpenGame Is Built
The framework has three interconnected components: the specialized language model GameCoder-27B, a six-phase agent pipeline, and an experience accumulation mechanism called Game Skill.
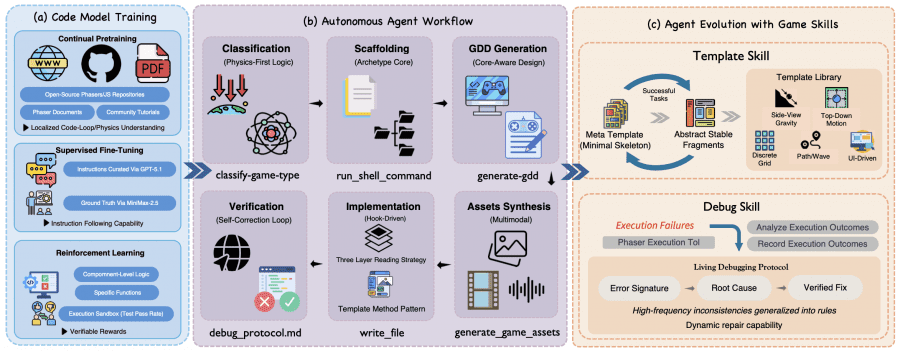
GameCoder-27B was trained in three stages on top of the base model Qwen3.5-27B. During continual pre-training, the model ingested data from open-source Phaser/JavaScript repositories on GitHub and official documentation, building an understanding of game loops, physics, and state management. In the supervised fine-tuning stage, the authors used synthetic question-answer pairs: prompts were generated by GPT-5.1, and reference solutions were produced by MiniMax-2.5. Finally, during reinforcement learning, the model trained on code execution — generating individual game modules such as collision detection and state machines, with rewards computed from actual test run results.
The agent pipeline runs through six sequential phases: game type classification, project scaffolding, technical game design document (GDD) generation, multimodal asset creation (images, music), code implementation, and self-correction with verification.
Classification is based on physics rather than genre — for example, “does the character fall without ground support?” identifies a platformer, while “can the character move in any direction without jumping?” identifies a top-down game. This reduces errors when selecting the appropriate template.
Game Skill: How the Agent Learns from Its Mistakes
The key distinction between OpenGame and straightforward prompting is the Game Skill mechanism, which accumulates experience across tasks. It has two parts.
Template Skill starts from a single base template M0 — a minimal game-agnostic project skeleton — and progressively builds a library L of specialized templates. As the agent completes tasks, it extracts stable, reusable fragments and merges them into the library. Through experimentation, five families consistently emerged: gravity-based platformer, top-down with continuous movement, discrete grid, tower defense with enemy waves, and UI-driven games. Importantly, these five types were not defined in advance — they emerged from repeated reuse patterns.
Debug Skill maintains a living debugging protocol P: every time something breaks, the agent records the error signature, root cause, and verified fix. The next time a similar problem appears, the agent consults the accumulated knowledge rather than solving it from scratch. Beyond reactive repair, the protocol also includes lightweight pre-compilation checks — for example, verifying that asset keys in the configuration match the actual files.
OpenGame-Bench: Evaluating Playability
Standard code benchmarks test static inputs and outputs, but that approach does not work for games. The authors built OpenGame-Bench — an evaluation pipeline covering 150 tasks with unique prompts spanning five genres. Evaluation runs through a headless browser that actually executes the generated game. The benchmark code was not publicly released at the time of writing.
Three metrics are used: Build Health (BH) measures whether the project compiles and runs without critical errors; Visual Usability (VU) combines a pixel-level heuristic (frame entropy and motion detection) with a multimodal model judge score; Intent Alignment (IA) measures how well the original prompt requirements are satisfied, also via a VLM judge. All three metrics are normalized to a 0–100 scale.
Results: OpenGame vs. Other Approaches
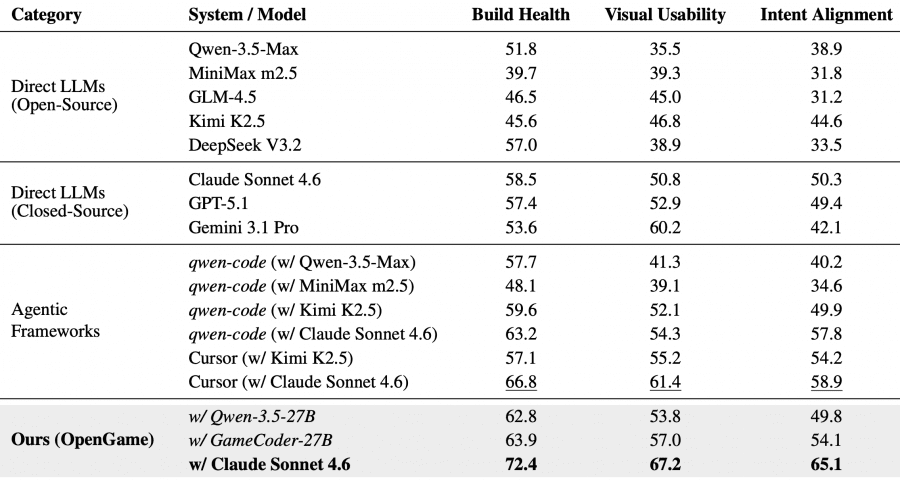
OpenGame with Claude Sonnet 4.6 as the reasoning engine achieves BH = 72.4, VU = 67.2, IA = 65.1 — a new state of the art. The closest competitor, Cursor with the same backend, trails by 5.6, 5.8, and 6.2 points respectively. The largest gap is on Intent Alignment (+6.2), indicating that structured planning and template-based scaffolding preserve user-specified mechanics better than unconstrained generation.
GameCoder-27B inside OpenGame achieves BH = 63.9, VU = 57.0, IA = 54.1 — surpassing all direct open-source and closed-source model baselines on Build Health and Intent Alignment, while being significantly smaller than proprietary alternatives.
That said, even the best configuration leaves roughly 34.9% of mechanical requirements partially or fully unsatisfied. This reflects the genuine difficulty of translating an ambiguous text prompt into a self-consistent multi-file structure — no model does this reliably yet.
What Matters More: the Model or the Framework?
Ablation studies show that the primary quality gains come from the framework architecture, not from a stronger base model. Adding continual pre-training to Qwen3.5-27B yields a small improvement in Build Health. Supervised fine-tuning adds +1.9 to Intent Alignment. Reinforcement learning with code execution improves Visual Usability and Intent Alignment slightly further. But the combined contribution of all three training stages is smaller than the contribution of the well-structured agent pipeline itself.
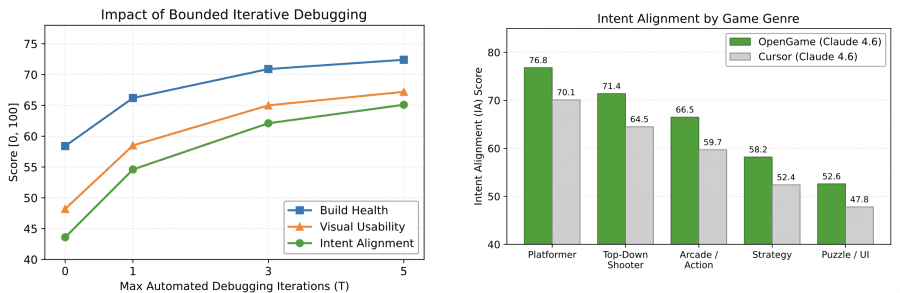
The effect of iterative debugging is notable: at zero iterations (zero-shot generation), Build Health is only 58.4. By the third iteration, most cross-file inconsistencies are resolved; after the fifth, gains plateau. This means self-correction over several steps is not an optional feature but a necessary condition for producing working projects.
By genre, the agent performs best on platformers (IA = 76.8) and top-down shooters (71.4), where physics clearly constrains the structure and specialized templates work well. Performance drops most on strategy games (58.2) and puzzle/UI games (52.6): logical errors in these genres often trigger neither compiler warnings nor runtime crashes, so the agent simply receives no signal that something is wrong.
Conclusion
OpenGame shows that reliable game generation requires not just a more powerful language model, but a combination of three things: domain-specialized training, a structured agent pipeline, and accumulated engineering knowledge about failure modes. The authors hope OpenGame will serve as an open foundation for research on agentic software engineering — tasks where quality unfolds over time and demands real execution, not just static code checks.










