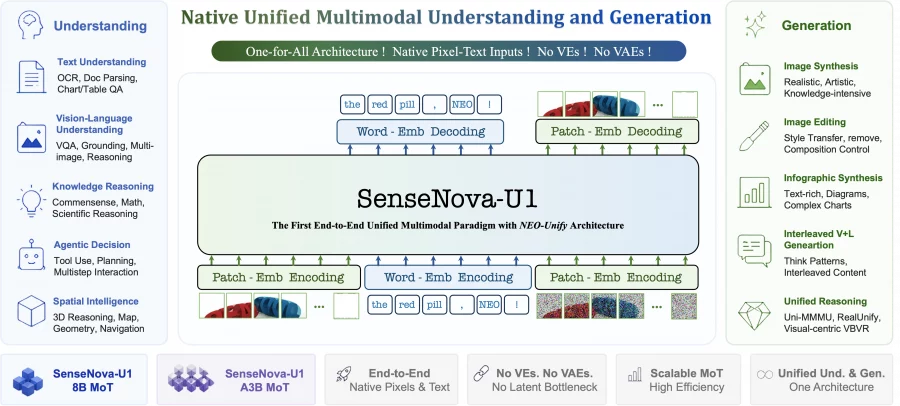
SenseNova introduced a new multimodal architecture, SenseNova-U1, which combines image understanding, generation, and editing inside a single transformer without a separate visual encoder or variational autoencoder. This approach removes the need to constantly translate data between different representation spaces, allowing the model to preserve visual details better, work more reliably with text inside images, and combine multimodal reasoning with generation more effectively. On image editing benchmarks, the compact SenseNova-U1-8B-MoT outperforms Qwen-Image, BAGEL, FLUX.1-Kontext, and OmniGen, while the 30B model performs at the level of leading open multimodal models such as Qwen2.5-VL and InternVL on multimodal understanding, OCR, and visual reasoning tasks.
The authors released the code on Github, and published the model weights and checkpoints on Hugging Face. The repository already includes scripts for running model inference, demo pipelines, model configurations, and examples for text-to-image generation, image editing, and interleaved text-image generation. The authors also provided ready-to-run model launch examples through the Hugging Face Transformers library. Separately, the researchers published a technical description of the NEO-unify architecture in a Hugging Face blog post.
Several SenseNova-U1 variants are available on Github, including dense and MoE versions of the model, as well as separate checkpoints for multimodal understanding and generation.

Why conventional multimodal models struggle to unify understanding and generation
The authors start from a fairly simple idea. Almost all modern multimodal models consist of two independent parts. Image understanding is handled by a visual encoder, usually something like ViT or a CLIP-like model. Image generation is handled by a diffusion model with a variational autoencoder. Because of this, two different feature spaces appear inside the model.
As a result, the model has to constantly convert data between different representation spaces. This creates several problems:
- part of the visual information is lost during latent representation compression;
- understanding and generation are trained with different loss functions;
- the architecture becomes more complex and heavier;
- multimodal reasoning works worse because of the gap between tasks.
The authors argue that the problem is not only an engineering one. They explicitly write that the separation of understanding and generation has become a structural limitation for the development of multimodal AI.
What exactly the authors propose
SenseNova-U1 is built on the NEO-unify architecture. The main idea is to work directly with pixels and text without intermediate encoding and decoding modules.
The model uses:
- a native multimodal transformer;
- flow matching in pixel space instead of latent diffusion;
- a unified self-attention space for text and images;
- the Mixture-of-Transformers architecture;
- image generation without significant loss of visual details during compression.
The authors call this a native unified multimodal paradigm. In other words, the model is trained from the start as a single multimodal foundation model, rather than as a set of connected components.
On Github, the authors separately emphasize that the model works directly with pixels and text without a separate latent space. For generation, it uses flow matching in pixel space with 32× visual compression, while text and images are processed inside a shared transformer backbone.

How the architecture works
Instead of a visual encoder, the model uses very lightweight image patching. The image is divided into 32×32 pixel blocks, after which they are sent directly into the transformer. This uses only two convolutional layers with GELU activation.
Interestingly, generation also happens directly in pixel space. The model does not use a diffusion head or a variational autoencoder. Instead, the transformer directly predicts pixel patches through a multilayer perceptron. This reduces architectural complexity and removes the bottleneck that usually appears in latent diffusion models.
Judging by the inference pipeline in the repository, the model really works without a classical Stable Diffusion-style diffusion pipeline. The code does not include a separate VAE encoder-decoder stage, which is usually used in almost all modern diffusion models.
The diagram below clearly shows the difference from standard approaches.
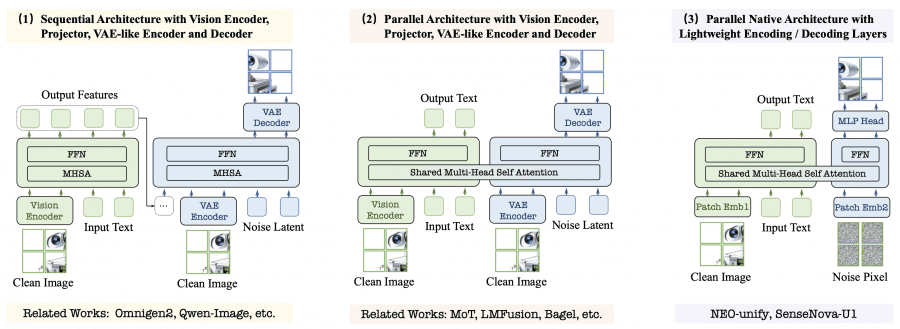
On the left are traditional processing pipelines with a variational autoencoder and visual encoder. On the right is the SenseNova-U1 architecture, where text and images are processed inside a single transformer backbone.
What the new architecture gives in practice
The authors separately emphasize that the NEO-unify architecture is needed not only to simplify the model, but also to increase the efficiency of multimodal learning. Compared with many open-source diffusion models and VLMs, SenseNova-U1 shows higher generation quality with lower inference latency.
The graphs below show that SenseNova-U1-8B-MoT achieves a good balance between generation speed and quality on benchmarks for image generation, infographics, and layout-heavy tasks. In terms of quality-to-speed ratio, the model outperforms BAGEL, Z-Image, OmniGen, and FLUX.1-Kontext, while also competing with larger commercial models.
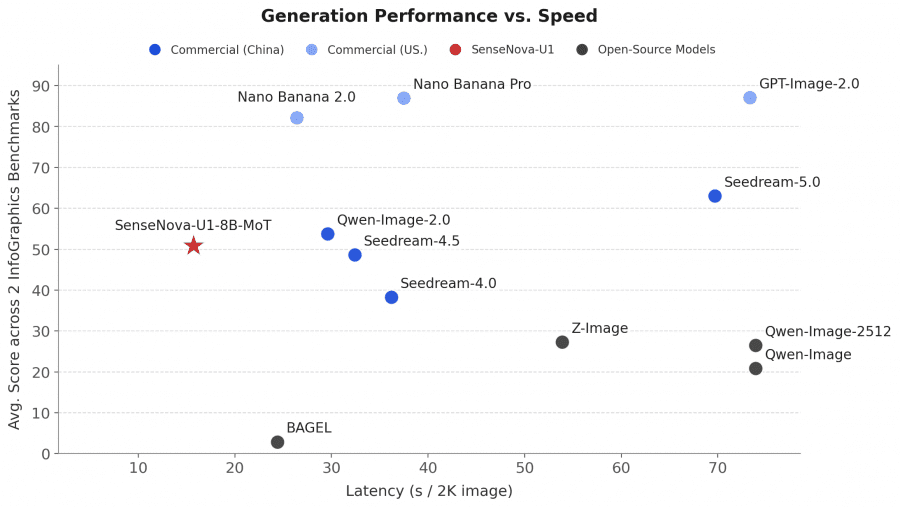
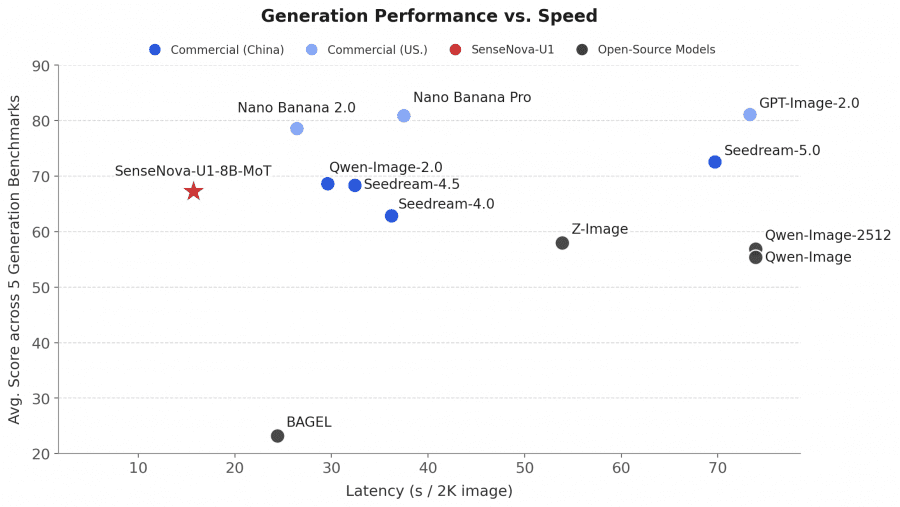
The authors highlight three main advantages of the architecture:
- state-of-the-art results among open models on both multimodal understanding and generation tasks;
- native interleaved text-image generation within a single inference process;
- strong performance on information-dense images, including infographics, presentations, comics, posters, and complex layouts.
The authors also show that the model handles document generation well when long text, diagrams, charts, and complex visual structure are present at the same time. For most diffusion models, such tasks remain difficult because of information loss during latent image compression.
Mixture-of-Transformers instead of a regular transformer
Another important part of the work is Mixture-of-Transformers, or a mixture of transformers.
Usually, multimodal models face the problem of conflicting gradients. When one part of the model is trained on visual tasks and another on language modeling, parameter updates start interfering with each other. This is especially noticeable during joint training.
In SenseNova-U1, the authors separate the understanding stream and the generation stream inside transformer layers. Attention remains shared, but feed-forward blocks and normalization are separated by token type.
There are three main versions of the model:
- SenseNova-U1-8B-MoT — a dense model with 8 billion parameters;
- SenseNova-U1-A3B-MoT — a mixture-of-experts model with 30 billion parameters and 3 billion active parameters during inference;
- SenseNova-U1-A3B-MoT-SFT — a post-trained version of the model with 30 billion parameters and 3 billion active parameters after supervised fine-tuning for multimodal interaction, generation, and image editing.
Technical model parameters:
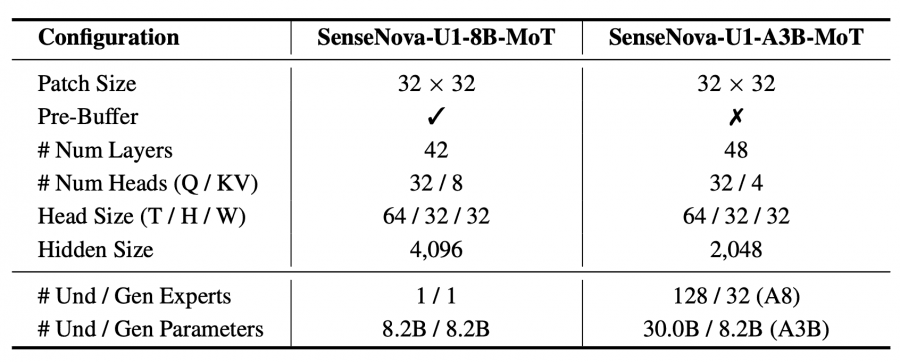
The MoE version uses top-k routing with only 8 experts activated per token. This lowers inference cost and allows the multimodal model to scale more efficiently than a regular dense transformer.
The repository shows that inference for A3B-MoT uses stream-wise mixture-of-experts routing. During model operation, only part of the experts are activated, so the model with 30 billion parameters requires significantly less computation than a dense transformer of the same size.
How the model was trained
Training was split into four large stages.
First comes the preliminary understanding training stage. At this stage, the model is trained for multimodal understanding on text and images.
Then generation pre-training begins. Here, the generation branch learns to generate pixel patches directly through flow matching training.
After that, joint multimodal training starts, where understanding and generation are trained together inside one architecture. The final stage is supervised fine-tuning.
Interestingly, generation works through flow matching in pixel space rather than through latent diffusion space. Formally, the loss function looks like this:
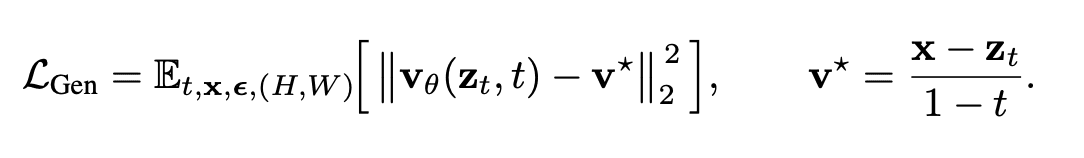
This is a standard mean squared error loss function for velocity prediction inside a flow matching framework. The authors argue that this approach better preserves visual quality and semantic consistency.
What the model can do
The authors tested the model on several types of tasks:
- answering questions about images;
- text recognition and document parsing;
- text-to-image generation;
- image editing;
- interleaved text-image generation;
- infographic generation;
- spatial reasoning.
Infographic generation looks especially interesting. Most diffusion models struggle with text inside images. They produce artifacts, incorrect characters, and broken structure.
SenseNova-U1 shows noticeably more stable generation of images with a lot of text. This is because text and images are processed inside a single autoregressive transformer space.
On Github, the authors show examples of infographic generation, presentations, comics, complex layouts, and text-heavy image generation. This is one of the model’s strongest sides, because most open-source diffusion models still struggle with long text inside images.
Examples of image editing and interleaved text-image generation by SenseNova-U1:


Benchmark results
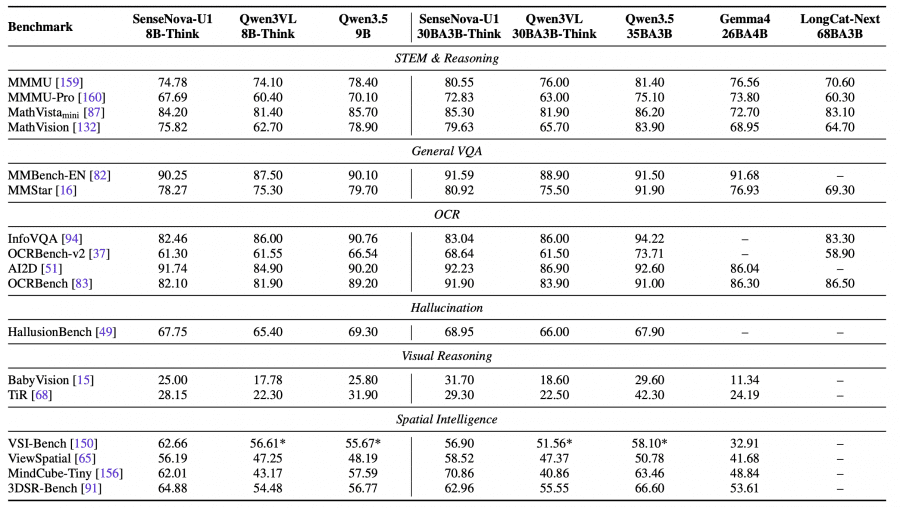
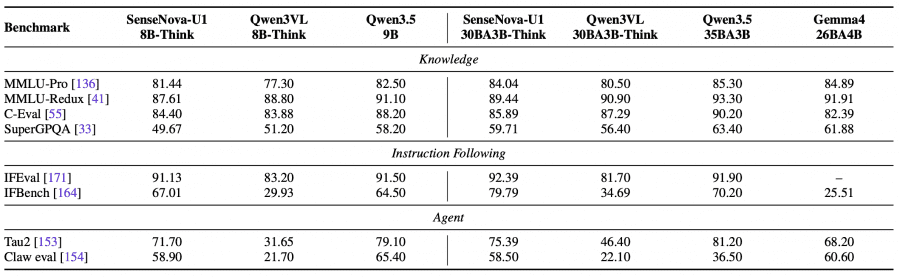
The authors compared SenseNova-U1 with GPT-4o, Gemini 2.5 Pro, Qwen2.5-VL, Qwen-Image, BAGEL, InternVL-U, OmniGen, and FLUX.1-Kontext on benchmarks for multimodal understanding, visual reasoning, text recognition, image generation, and image editing.
SenseNova-U1-A3B-MoT shows results at the level of the best open VLMs on understanding and reasoning tasks. The model scores:
-
- 94.9 on OCRBench;
- 87.3 on MMBench;
- 74.1 on MathVista;
- 68.8 on MMMU;
- 96.1 on DocVQA.
Top-1 result on GenEval:
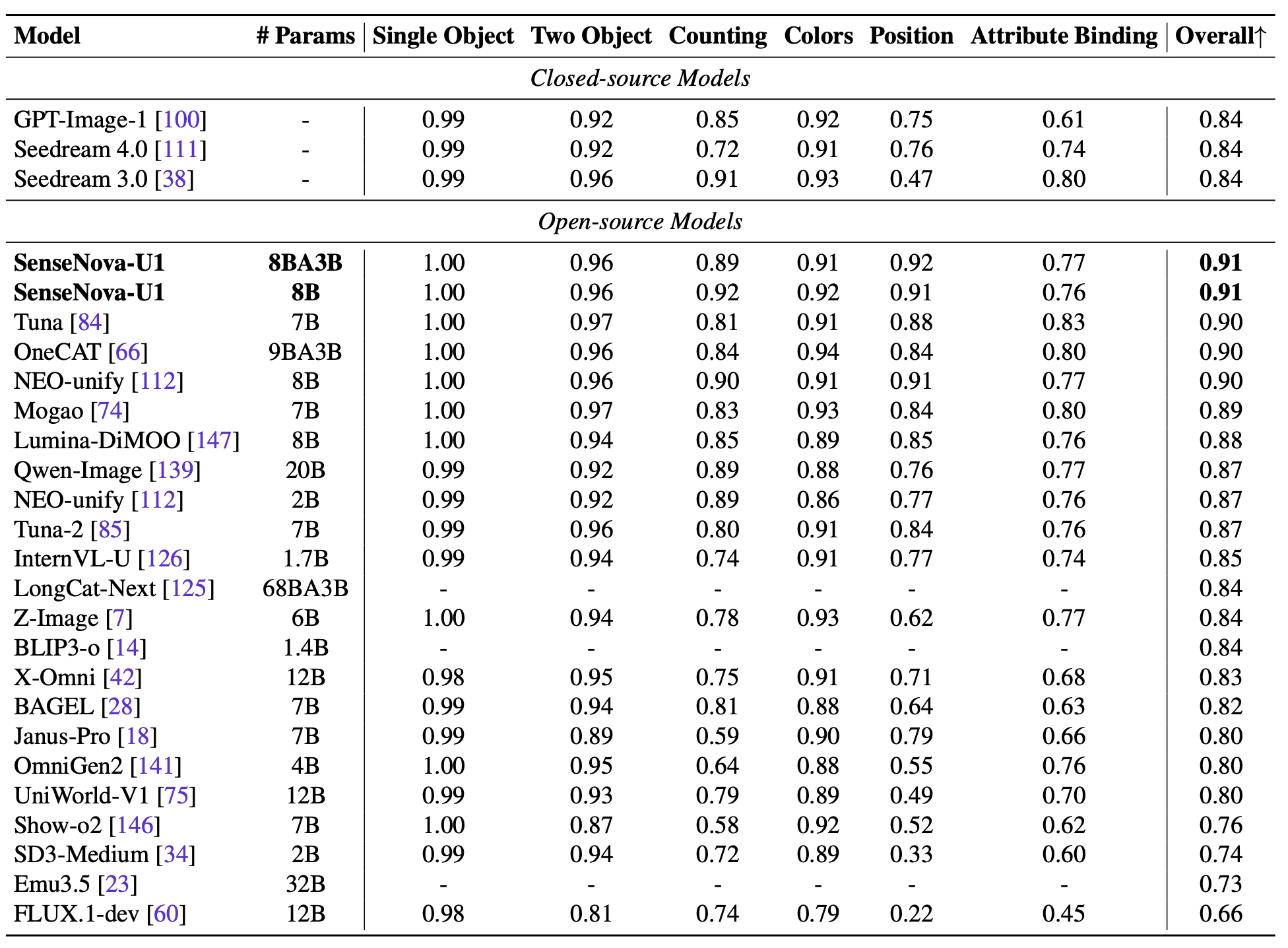
The model also shows strong results on image editing and image generation tasks. The gap is especially noticeable on benchmarks with a lot of text inside images and complex layouts.
The RISEBench results are:
- SenseNova-U1-8B-MoT — 58.2;
- SenseNova-U1-A3B-MoT — 57.4;
- Qwen-Image-Edit-2511 — 49.9;
- BAGEL — 36.5;
- FLUX.1-Kontext-Dev — 26.0;
- OmniGen — 22.0.
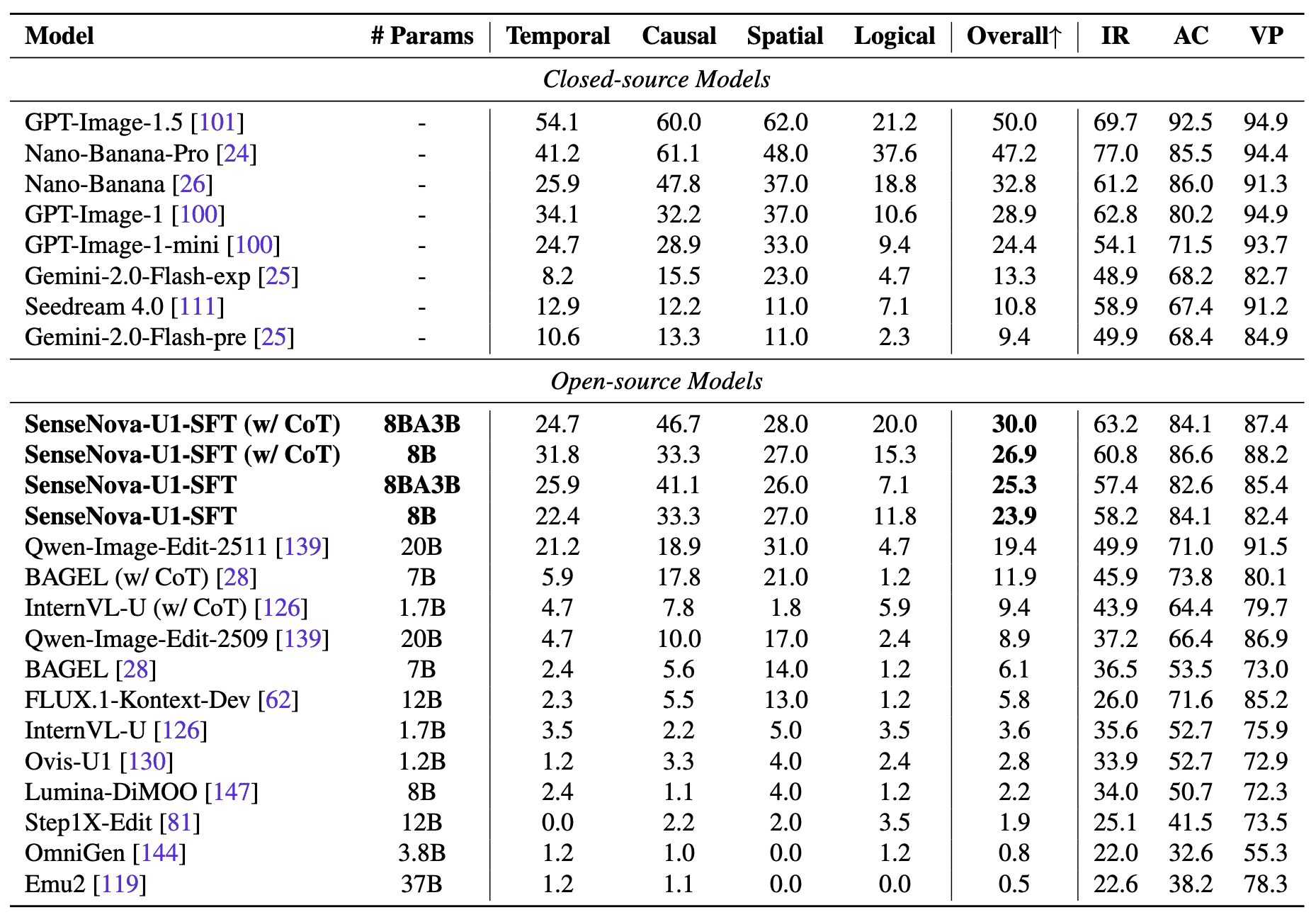
The authors separately emphasize that the model performs well on interleaved generation, where text, images, diagrams, and layouts need to be generated together inside one document.
In the ablation study, the authors show that removing the VAE and visual encoder really helps preserve both image semantics and fine visual details.
Why this matters
Most AI companies are now moving toward universal multimodal models. Gemini, Qwen-Image, BAGEL, and other models are gradually combining image understanding and generation.
But many approaches still keep a separation between the visual encoder and the diffusion generation pipeline. SenseNova-U1 is interesting because it tries to remove this separation completely.
The authors effectively test the hypothesis that multimodal intelligence can emerge inside a single transformer backbone without special intermediate representation spaces.
It is also interesting that the authors have already released a public demo with multimodal interaction, image generation, and image editing directly in the browser. For an open-weight multimodal model of this scale, this is still rare.
This is not yet a perfect universal multimodal model. But the work shows that direct modeling in pixel space is starting to compete with latent diffusion even on complex generation and multimodal reasoning tasks.
The work shows that multimodal models are gradually moving toward unifying generation, understanding, and language modeling inside a single architecture.









