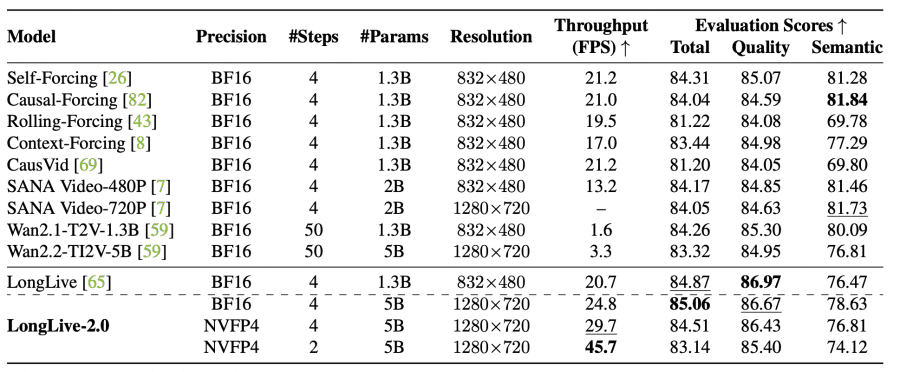
Researchers from NVIDIA have published LongLive-2.0 — an infrastructure for training and running long video generation models using NVFP4 4-bit precision quantization. Quantization is the compression of model weights by reducing the number of bits used to represent each number: BF16 stores each number in 16 bits, NVFP4 compresses them to 4 bits, so the model uses less memory and runs faster. In theory this should reduce generation quality, but the authors show that in practice results are nearly identical to BF16. The key result: a 5 billion parameter model generates video at 1280×720 resolution at 45.7 frames per second — the first time NVFP4 has been applied across the full training and inference pipeline for long video generation. Compared to the BF16 baseline, training is 2.15× faster and inference is 1.84× faster. The project is fully open: model weights, code, and datasets are available on GitHub and Hugging Face.

Why a new infrastructure was needed
Long video generation is a task where a model must sequentially produce video fragments while maintaining scene and character consistency over minutes of screen time. The problem is that the longer the video, the more GPU memory (VRAM) is required and the slower the model runs. Until now, most work in this area focused on algorithms while largely ignoring the infrastructure side.
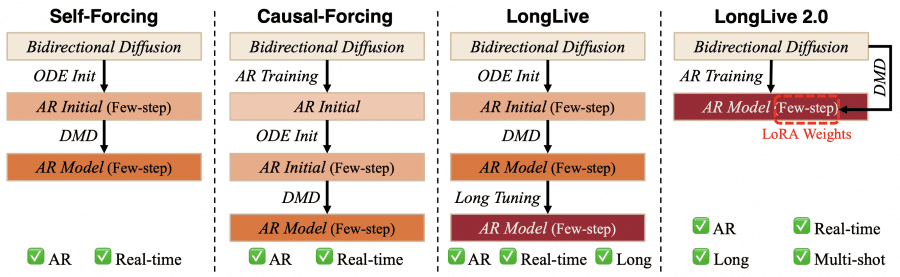
Existing approaches like Self-Forcing and Causal-Forcing rely on a complex multi-stage training pipeline: first ODE initialization (a differential equation method for bootstrapping training), then DMD (distribution matching distillation), and only then an additional fine-tuning stage on long videos. LongLive-2.0 removes this complexity entirely.
Key components of LongLive-2.0
The authors identify three core technical contributions:
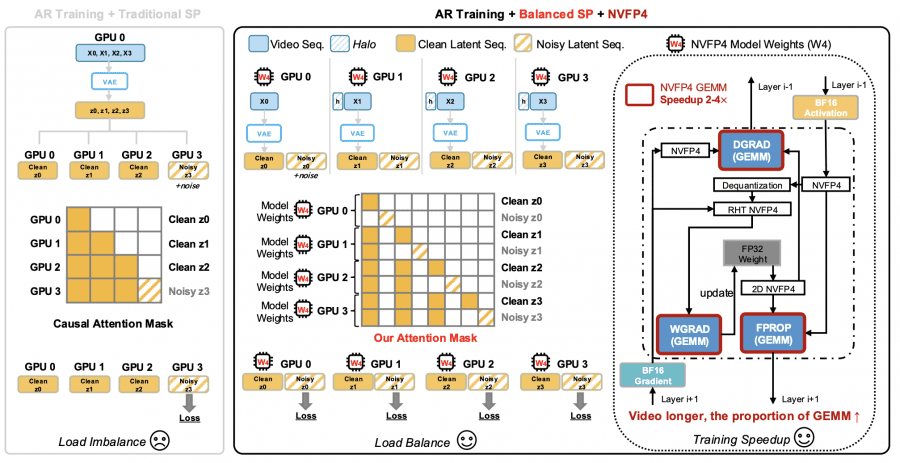
Balanced SP (balanced sequence parallelism). Standard sequence parallelism in autoregressive video training creates an imbalance: some GPUs receive mostly “clean” history tokens while others handle “noisy” target tokens. This distributes the computational workload unevenly. Balanced SP solves this by assigning each GPU both clean and noisy tokens from the same temporal chunk. Additionally, each GPU encodes only its own video segment through the VAE (variational autoencoder) rather than the full video, reducing redundant computation.
NVFP4 quantization. NVFP4 is NVIDIA’s 4-bit floating-point format, natively supported on Blackwell architecture GPUs (GB200). Each tensor element is stored in E2M1 format (2 exponent bits, 1 mantissa bit) with hierarchical scaling factors: block-wise (per 16 elements) and tensor-wise. Crucially, unlike standard INT4 integer quantization, NVFP4 uses non-uniform step sizes between values, providing better precision for small numbers. Quantization is applied to weights and activations of the DiT (Diffusion Transformer) linear layers, and weight gradients additionally pass through RHT (Random Hadamard Transform) for training stability.
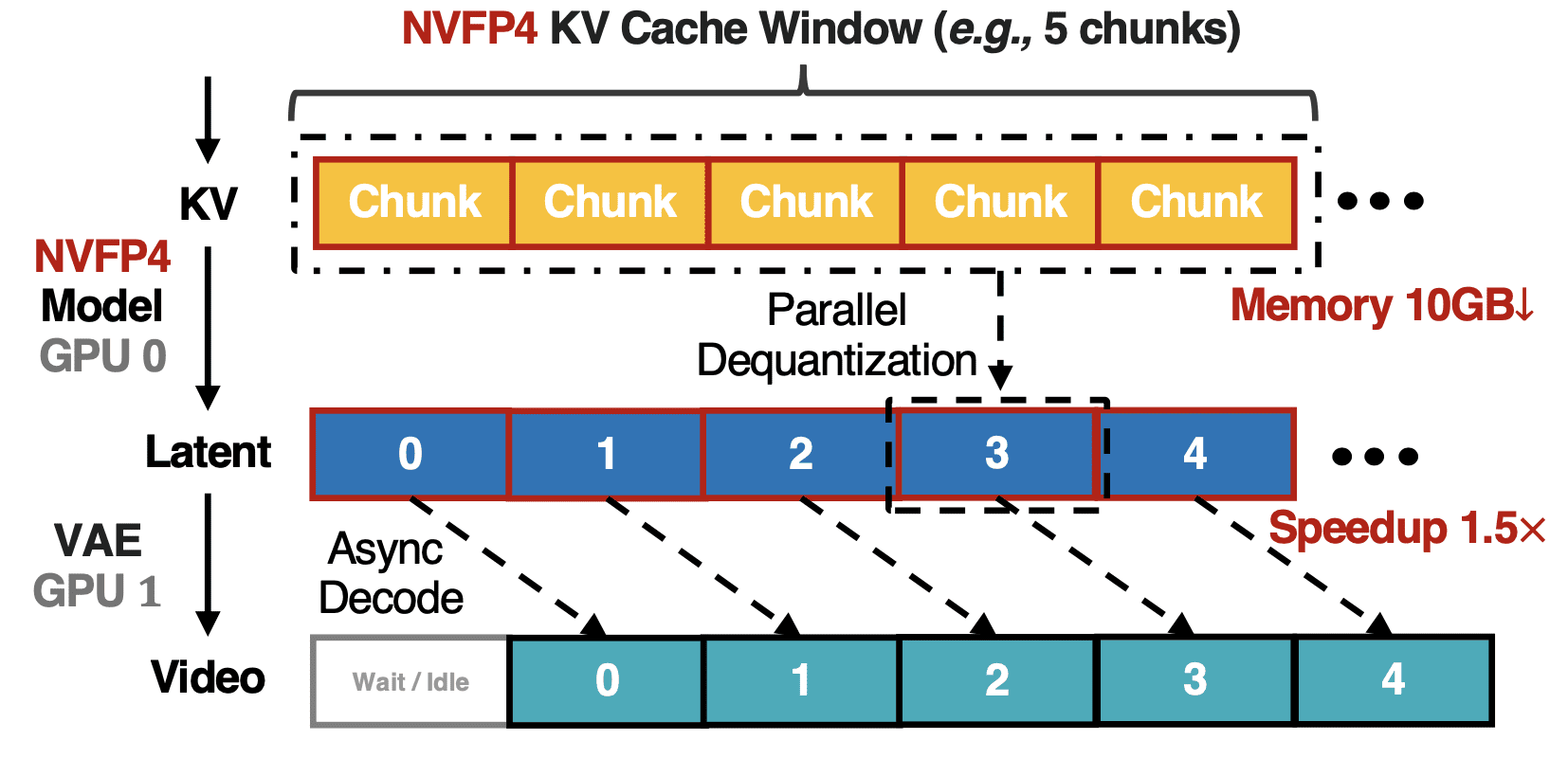
Asynchronous streaming VAE decoding. In the baseline model, all latent representations are generated first and only then decoded into pixels via the VAE. LongLive-2.0 launches decoding of each fragment in parallel with the denoising (diffusion reconstruction) of the next fragment on a separate GPU. Since denoising typically takes longer than decoding, the VAE step is almost entirely hidden behind DiT computation.
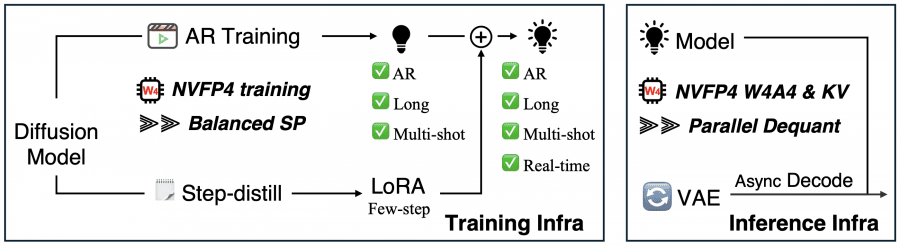
A simpler training pipeline
The key architectural decision in LongLive-2.0 is the ability to drop complex multi-stage training. The authors take the pretrained bidirectional diffusion model Wan2.2-TI2V-5B and directly fine-tune it on long multi-shot videos with an AR (autoregressive) objective. No ODE initialization, no intermediate DMD on short videos.
After this single fine-tuning stage, the result is an AR model supporting long multi-shot videos with 4 denoising steps. To obtain the 2-step real-time version, only LoRA adapters (Low-Rank Adaptation — a method for fine-tuning a small subset of parameters) are trained on top of the frozen backbone. These weights can be plugged into any model in the Wan2.2-TI2V-5B family.
How inference works: KV cache and attention sinks
During autoregressive generation the model keeps a KV cache (keys and values cache for attention) of all previously generated fragments in memory. For long videos this quickly becomes a memory bottleneck. LongLive-2.0 quantizes the KV cache to NVFP4 on the fly during generation, achieving roughly 3.6× compression.
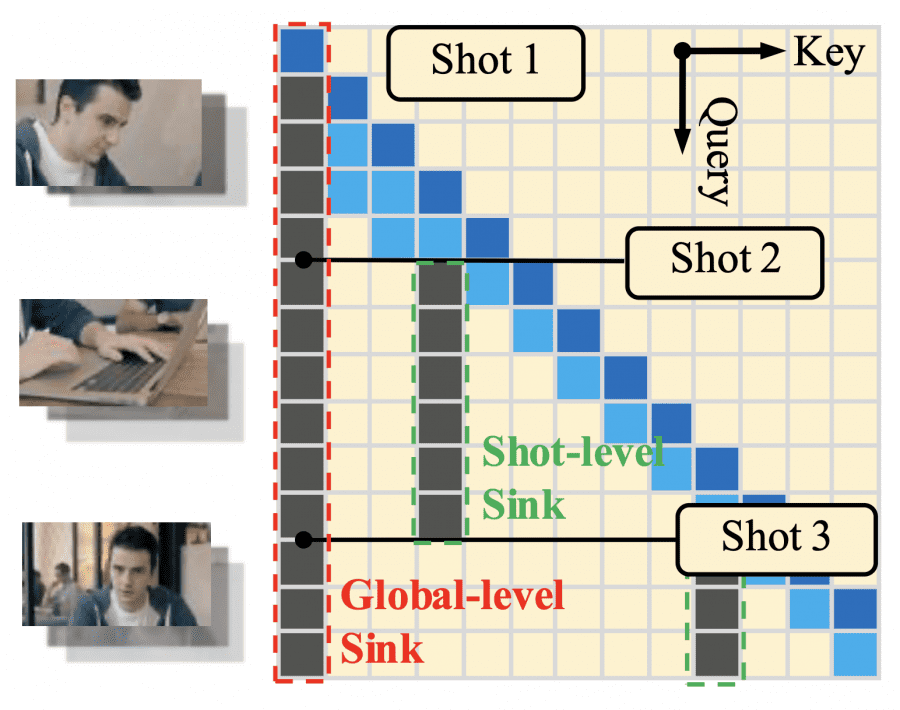
To maintain consistency within a sliding attention window, the authors introduce two-level attention sinks: the first few frames of the entire video (global sink) are permanently fixed to preserve global identity, while the first few frames of the current shot (local sink) are re-bound at every scene cut. This allows the model to maintain both global character identity and local consistency within each shot.
Results: speed and quality
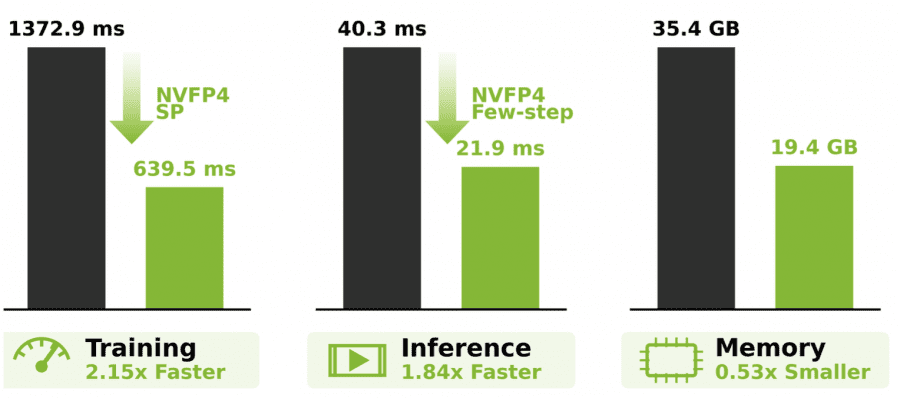
For 64-second videos, the BF16 version without parallelism runs out of memory entirely. With BF16 and standard sequence parallelism, one training iteration takes 1372.9 seconds. Balanced SP reduces this to 1196.5 seconds. Adding NVFP4 brings it down to 639.5 seconds — the 2.15× speedup the authors report.
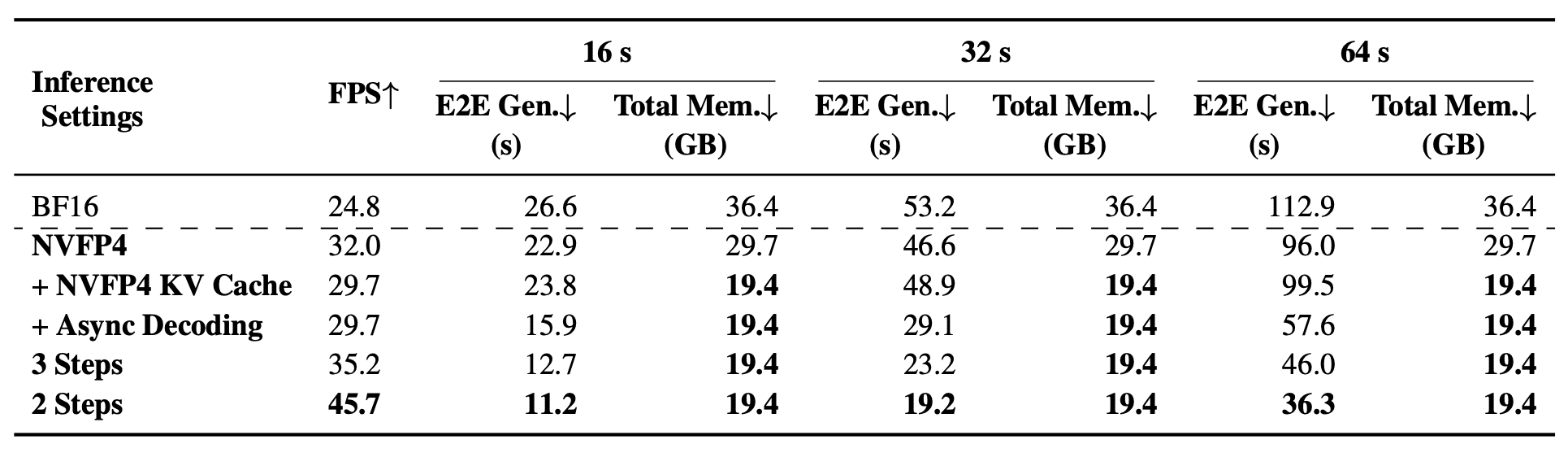
At inference, the 2-step denoising model generates a 64-second 720p video in 36.3 seconds while using 19.4 GB of GPU memory. By comparison, the BF16 version with 4 steps required 112.9 GB.
On the VBench-Long benchmark (60-second video generation) LongLive-2.0 ranks first by average rank among all compared methods — 3.67 versus 4.17 for the original LongLive. Subject consistency reaches 97.48% and background consistency 97.00%, meaning characters and environments barely drift over the course of the full video.
Limitations
The authors are upfront about the main limitation: NVFP4 inference acceleration only works on Blackwell architecture GPUs (e.g. GB200). A100 (Ampere) and H100 (Hopper) GPUs lack native hardware support for NVFP4. For those GPUs, sequence parallelism is offered as an alternative to boost inference speed — it achieves comparable throughput, but through multi-GPU parallelization rather than low-bit quantization.
In short, reaching 45.7 FPS on a single card requires a GB200. On older hardware, either multiple GPUs or lower speeds are the tradeoff.








