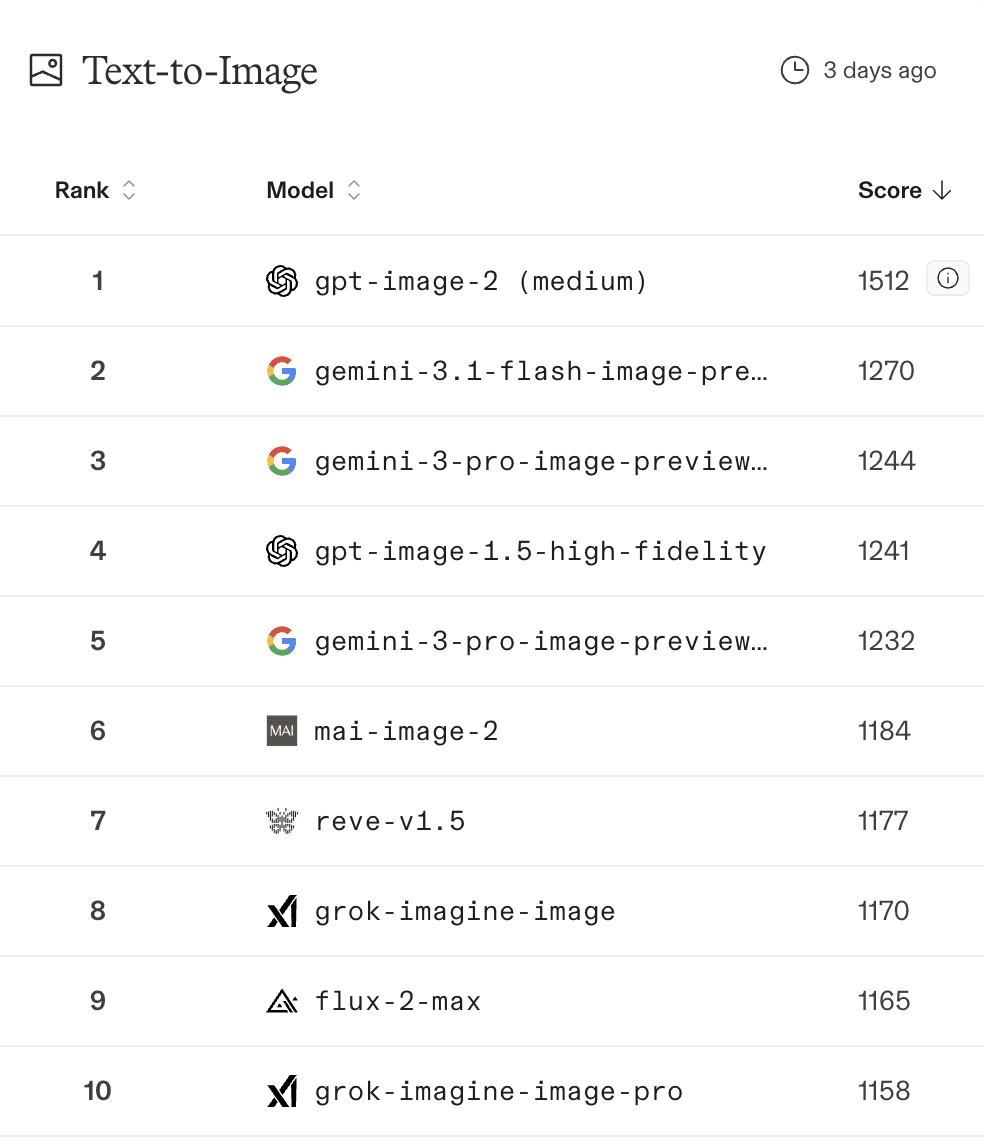
April 21, 2026, OpenAI released ChatGPT Images 2.0 powered by the gpt-image-2 model. According to LM Arena, the new model immediately took first place across all image generation categories with a +242 Elo point lead over the nearest competitor — primarily due to near-perfect multilingual text rendering and precise instruction following.
The key technical advancement is the integration of the O-series reasoning mechanism. Before starting generation, the model plans the composition, verifies object counts, and checks prompt constraints. In ChatGPT this is called thinking mode and is available to Plus, Pro, and Business subscribers. Via the API the thinking parameter accepts three levels: low, medium, and high. The standard mode without reasoning is available to all ChatGPT users for free. API access is open to all registered OpenAI developers.
A brief history: from GPT Image 1 to version 2.0
To understand the scale of the changes, it helps to look at how this model family evolved. GPT Image 1 launched in March 2025 as a native image generation feature inside GPT-4o. In the first week, 130 million users created more than 700 million images, and Sam Altman wrote that the GPUs were “literally melting.” In December 2025, GPT Image 1.5 arrived with improved instruction following and more accurate color reproduction, taking second place in the LM Arena leaderboard. Now gpt-image-2 is here, which OpenAI positions not as a toy generator but as a full-scale tool for visual workflows.
In parallel, on May 12, 2026, OpenAI plans to shut down DALL-E 2 and DALL-E 3 — an official signal that gpt-image-2 is becoming the production replacement for the entire previous generation.
Technical specs: what changed
The core difference between gpt-image-2 and its predecessors is not just improved rendering but a completely rebuilt architecture. Research Lead Boyuan Chen confirmed the architecture was “revamped from scratch,” though he declined to clarify whether the model uses a diffusion or autoregressive approach. The most significant addition is the integration of O-series reasoning, making gpt-image-2 the first image model with native thinking capabilities.
Here is a comparison of key parameters against the previous version:
| Feature | gpt-image-1 | gpt-image-2 |
|---|---|---|
| Maximum resolution | 1024 px | 2000 px on the long edge |
| Aspect ratios | 1:1, 3:2, 2:3 | 1:1, 3:2, 2:3, 16:9, 9:16, 3:1, 1:3 |
| Images per request | 1 | up to 10 (with style consistency) |
| Text rendering | English only, often garbled | multilingual, including Cyrillic, CJK, Indic scripts |
| Reasoning mode | no | yes (thinking parameter) |
| Web search during generation | no | yes, in thinking mode |
| Knowledge cutoff | — | December 2025 |
The updated knowledge cutoff of December 2025 allows the model to produce more accurate and contextually relevant images. This matters most for infographics, educational content, and visual explainers where factual accuracy is as important as aesthetics.
Thinking mode: plan first, render second
Thinking mode is arguably the most interesting technical addition. The model reads the prompt, plans the layout, renders sharp multilingual text, and can produce up to ten images in a single request at up to 2000 pixels across a wide range of aspect ratios the previous version did not support.
The thinking parameter has three levels: low, medium, and high. They trade generation latency for layout accuracy. For diagrams, tables, and any image that must get numbers right, medium is the most practical default. In thinking mode the model can also run web searches mid-generation, which helps with infographics using real data or maps that need correct labels.
Here is a basic API request with reasoning enabled:
curl https://api.openai.com/v1/images/generations
-H "Authorization: Bearer $OPENAI_API_KEY"
-H "Content-Type: application/json"
-d '{
"model": "gpt-image-2",
"prompt": "A four-panel infographic on OAuth 2.1, arrows labeled in English and Japanese.",
"size": "2000x1000",
"n": 1,
"quality": "high",
"thinking": "medium"
}'One important cost note: thinking is billed separately via reasoning tokens. A prompt with strict layout constraints will cost more than a loose illustration request.
Pricing and availability
For developers, the model is available via the API with reasoning mode, per-token pricing, and the same endpoint structure used in production. Token costs per the official OpenAI pricing page: $5 per million input text tokens, $10 per million output text tokens, $8 per million input image tokens, and $30 per million output image tokens. At standard 1024×1024 high quality, that works out to roughly $0.21 per image — about 60% more than gpt-image-1, reflecting the larger canvas and the reasoning step.
Standard gpt-image-2 is available to free ChatGPT users. Thinking mode, extended reasoning, and web search during generation are restricted to Plus, Pro, and Business subscribers. API access is tied to an OpenAI developer account.
The model is also available inside Codex, OpenAI’s coding environment, enabling visual asset creation within the same workspace used for writing code, building slide decks, and other deliverables.
Benchmark results
According to Arena, gpt-image-2 holds first place across all Image Arena Leaderboard categories: 1512 on text-to-image, 1513 on single-image editing, and 1464 on multi-image editing, with a +242 Elo lead over the next model on text-to-image. That is a substantial gap: in the Elo rating system, a 242-point difference translates to roughly an 80% win probability in blind comparisons.
Independent developer reactions on X converged on one point: this is not just prettier generation but a meaningfully more useful model for UI mockups, documentation, product visuals, and iterative design workflows. The most interesting systemic implication is that image generation is starting to function as a frontend for coding agents — generate a visual UI spec, then hand it to Claude Code or another coding agent as a reference for implementation.
Community reaction
The response across X and AI communities has been broadly positive, with some caveats. Users had been anticipating this release for weeks. The model had been referred to as “GPT-image-2” on Reddit and X well before the official launch. Earlier in April, a Reddit user reported that OpenAI was already testing the model inside ChatGPT with a limited audience.
Specific examples that spread through the community included manga comics with consistent recurring characters and evolving storylines, personalized “Where’s Waldo?” scenes, and full magazine spreads with accurately readable text blocks. Early testers highlighted UI mockup accuracy and text rendering as the standout practical improvements.
Figma, Canva, Adobe Firefly, and fal all announced gpt-image-2 integrations on launch day — a signal that the model is being treated as infrastructure, not just a ChatGPT feature.
On the critical side: photorealistic faces at close crop still produce artifacts. Precise brand assets with exact logo geometry are unreliable. Long text blocks (full paragraphs inside an image) break down after a few hundred characters. Style consistency holds within a single batch request but drifts across separate sessions.
Competition
Before gpt-image-2, Google Gemini led the LM Arena text-to-image leaderboard, with gpt-image-1.5 in second place. With the new release, OpenAI’s model took first with a significant lead. The main competitors in the reasoning-plus-image space are Google Nano Banana 2 (released slightly earlier) and a growing set of open-weight multimodal models narrowing the gap on text rendering.
The practical choice for developers: gpt-image-2 is the better option when text rendering accuracy, reasoning over composition, and integration with the rest of the OpenAI stack matter most. Open-weight multimodal alternatives win on per-image cost, self-hosting, and permissive commercial licenses.
Conclusion
gpt-image-2 is the first serious attempt to apply reasoning to image generation at production scale. The model has moved beyond being a “picture generator” and is closer to a tool that understands the visual task: plans slides, assembles infographics, renders accurate multilingual text, and verifies its own output. That is a fundamentally different class of capability compared to DALL-E and GPT Image 1.
The +242 Elo gap on Arena and the same-day integrations from Figma, Canva, and Adobe are good indicators that the market treats this as production infrastructure, not an academic demo. Real limitations remain — photorealistic faces, precise logos, long coherent text — but the practical surface area is already significantly broader than what any predecessor could cover.
Read also: Claude Code: Getting Started Guide