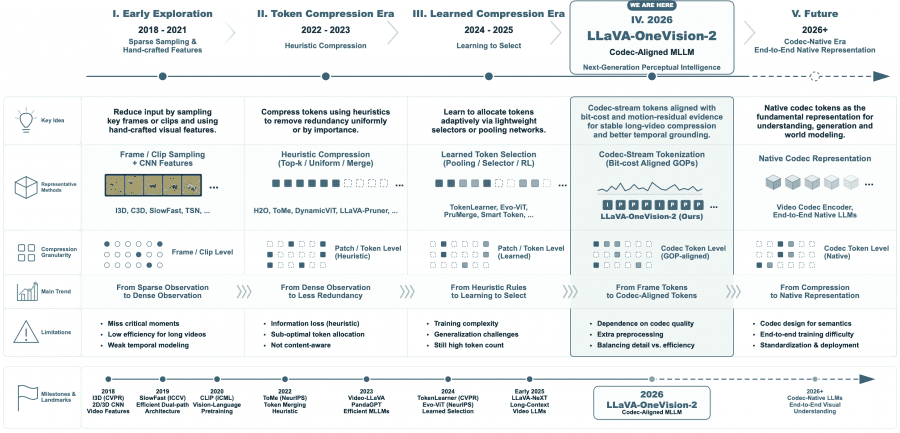
Researchers from Glint Lab, AIM for Health Lab, and MVP Lab published LLaVA-OneVision-2 (LLaVA-OV-2) — a next-generation multimodal model that rethinks how a neural network “watches” video. Instead of slicing video into uniformly sampled frames, the model analyzes the compressed video stream through a codec and autonomously decides which fragments to focus on. LLaVA-OV-2 can answer questions about video, localize events in time (temporal grounding), track objects across frames (video object tracking), reason about spatial relationships in 2D and 3D scenes, and work with regular images and documents. All of this runs within a single architecture with no separate decoders per task. The project is fully open-source: code is available on GitHub, datasets on Hugging Face, where model weights are also available.
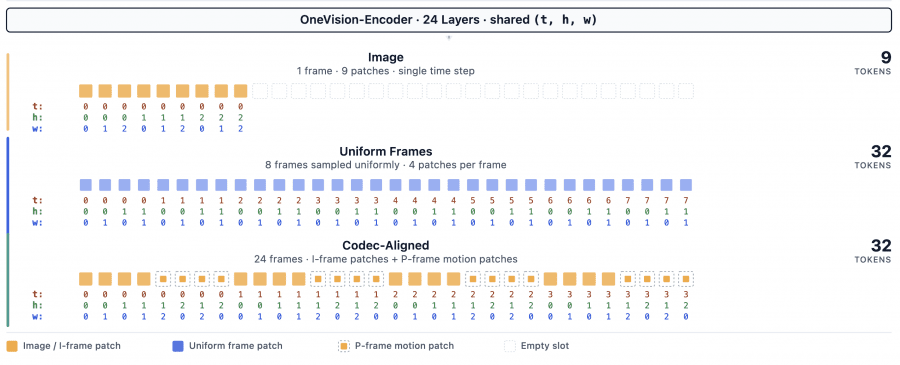
Why uniform frame sampling falls short
Most existing multimodal language models (MLLMs) process video the same way: take a video file, extract 8–32 uniformly spaced frames from the entire clip, and feed them to an encoder. Everything else is discarded. This creates an obvious problem: if something important happens between two sampled frames, the model simply misses it.
The authors propose a different approach. Video codecs like H.264 and H.265/HEVC already encode information about where changes occur in a video: I-frames (keyframes) carry the full scene image, while P-frames encode only the difference between adjacent frames via motion vectors and a residual signal. Wherever P-frames are “expensive” in terms of bitrate, something interesting is happening.
How codec-stream tokenization works
The key innovation of LLaVA-OV-2 is codec-stream tokenization. It operates in four stages the authors call GOP Partition, Scoring, Block Selection, and Canvas Packing.
First, the video is divided into adaptive Groups of Pictures (GOPs) not by elapsed time but by the cumulative bitrate of P/B-frames. When the bitrate spikes in a segment, it indicates fast motion or a scene change, and a GOP boundary is placed there. Then, for each group, a saliency map is computed: each 2×2 patch block receives a score combining the normalized motion vector magnitude and the normalized luma residual signal. High-scoring blocks are selected and packed into compact canvases — one I-canvas and several P-canvases per group.
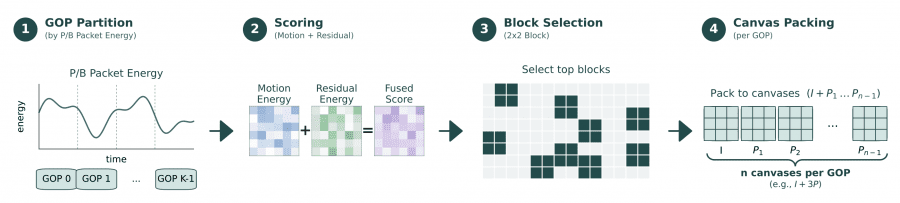
As a result, the model allocates more tokens to dynamic segments of the video and fewer to segments where nothing changes. This is fundamentally different from uniform sampling, where the token budget is spent equally on event-rich and monotonous segments alike.
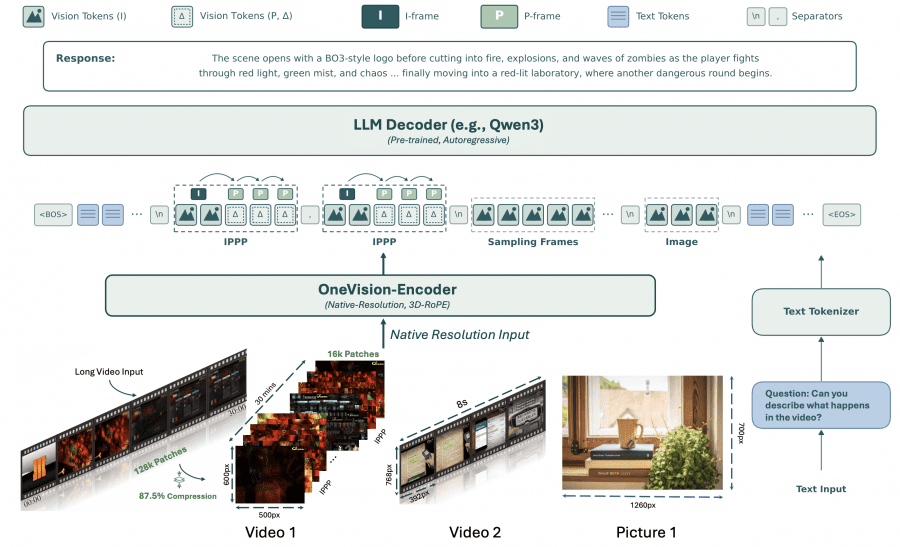
All inputs — codec-stream video, uniformly sampled video, and static images — are processed by a shared OneVision-Encoder at native resolution with 3D rotary position encoding (3D RoPE). A lightweight two-layer MLP connector then projects the visual embeddings into the language model’s embedding space, and decoding is handled by Qwen3-8B.
How the model was trained
Training proceeded in four stages. In stage 1, the model was initialized from LLaVA-OneVision-1.5 and trained on 4.2M short (up to 30-second) video–caption pairs. Stage 2 added large-scale instruction data from two sources — LLaVA-OneVision-1.5-Instruct-Data (~22M samples) and FineVision (~24M samples) — along with videos up to 3 minutes long. In stage 3, the maximum frame budget grew to 384, and 10–15-minute videos entered training. Stage 4 introduced codec-stream tokenization for long videos (384 and 768 frames) and added 4M spatial question–answer pairs from the LLaVA-OneVision-2-Spatial-4M dataset.
JumpScore: a new benchmark for hard cases
The authors also introduced their own benchmark, JumpScore, which fills an important gap in existing evaluations. Worth noting: the benchmark was created by the same researchers who built the model — standard practice in ML, but worth keeping in mind when interpreting results. The dataset is publicly available on Hugging Face. Most temporal grounding benchmarks test whether a model can find an event when adjacent frames look visually different. JumpScore poses the opposite challenge: find a specific moment among many visually near-identical cycles. It contains 189 jump-rope videos where the model must pinpoint the start of each jump to within 0.1–0.3 seconds. The median cycle period is around 0.4 seconds, so a 0.1-second error means the model nearly identified the correct cycle.
Results: how far ahead the model is
LLaVA-OV-2-8B was compared against four models in the same class (8 billion parameters): Qwen3-VL-8B, Keye-VL-1.5-8B, InternVL-3.5-8B, and LLaVA-OV-1.5-8B. The largest margin is on JumpScore (+44.8 points over Qwen3-VL) and on temporal grounding and spatial reasoning tasks. On most other benchmarks the model leads or ranks in the top 2.
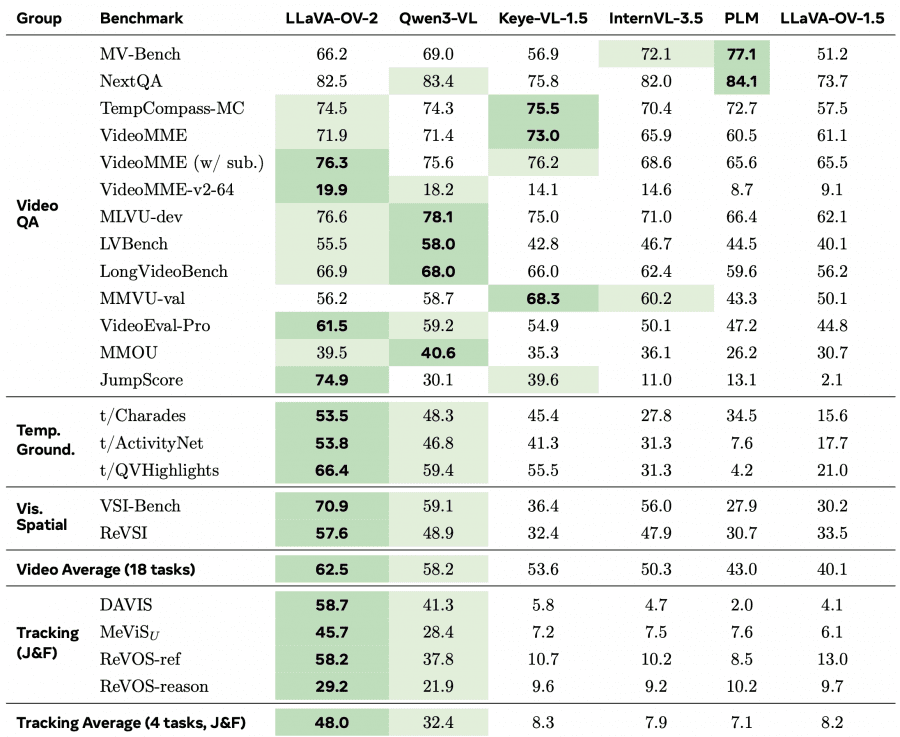
The model also leads on video object tracking: average J&F is 48.0 versus 32.4 for Qwen3-VL. There is no dedicated segmentation head — the model predicts (x, y) point coordinates for each frame and passes them to SAM 2 as prompts to generate masks.
Where codec beats uniform sampling — and where it doesn’t
The authors carefully examined which tasks benefit from codec-stream tokenization and where uniform frame sampling performs better or on par.
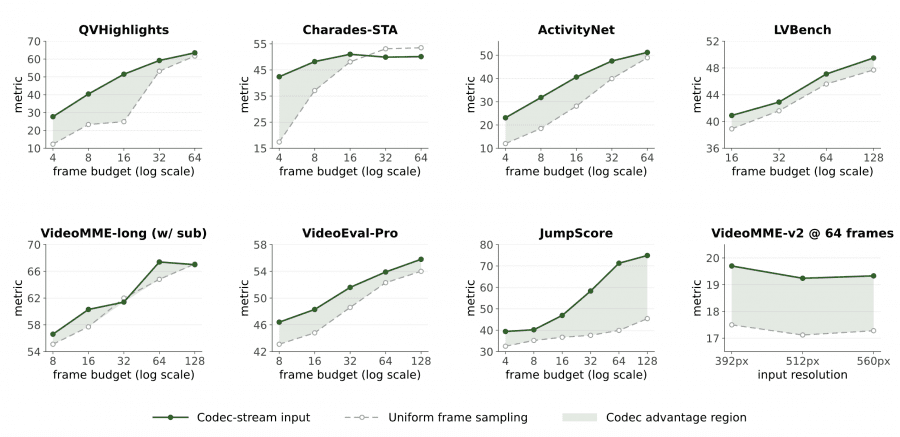
Codec-stream tokenization provides the largest gains where the answer depends on a specific event moment: temporal grounding (+9.7 points on average), JumpScore (+17.3 points averaged across all frame budgets), event recognition, and object counting. On long-form video QA tasks (VideoMME-Long, LVBench, VideoEval-Pro) codec maintains parity or a small lead — it does not trade semantic understanding for compression.
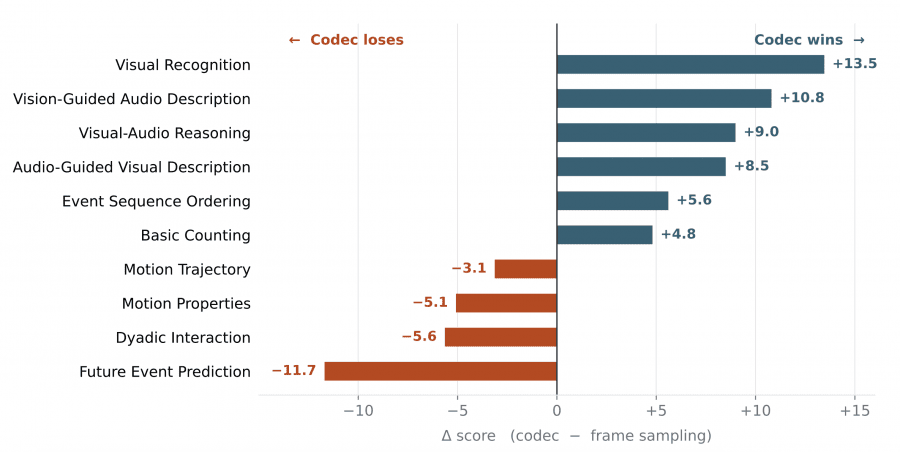
Uniform sampling remains preferable for tasks requiring continuous trajectory analysis: future event prediction, fine-grained motion tracking, and dyadic interaction. Where a dense frame sequence is needed to preserve fine-textured details, codec-stream misses some information.
A concrete example: JumpScore at 128 frames
The authors demonstrate this on a clip with 85 jump cycles. With uniform 128-frame sampling, the model correctly identifies 14 of 85 cycles (mAP 0.116). With codec-stream sampling at the same token budget — 82 of 85 (mAP 0.894). The 7.7× difference comes from codec concentrating tokens at cycle boundaries, exactly where bitrate and residual signal peak.
What this means
LLaVA-OV-2 demonstrates that codec-stream tokenization is not just another way to compress tokens, but a different perspective on what it means to “watch” a video. The key takeaway: codec and uniform sampling are not competitors but complementary tools. Codec is better where events matter; uniform sampling is better where continuity matters. Both modes are supported by a single architecture with no additional adapters.
The authors plan to extend this approach toward streaming video processing and hour-scale video, where visual evidence must be continuously updated, compressed, and retrieved from memory as new content arrives.











