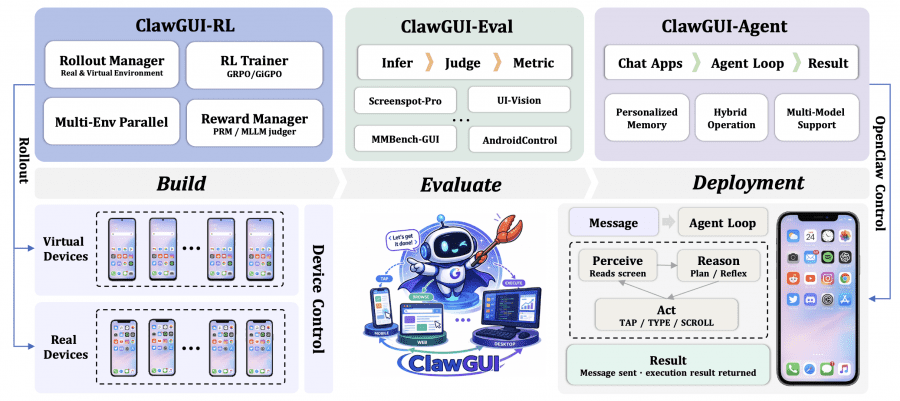
Researchers from Zhejiang University have published ClawGUI — a fully open-source framework for building GUI agents that control applications through their visual interface, just like a human would: taps, swipes, and text input. In practice, this opens up several use cases: automating mobile app testing without writing scripts by hand, controlling enterprise software without API access, voice or text control of a phone through familiar messaging apps, and a research platform for those working on GUI agents who want reproducible results on shared benchmarks. The project is released under the Apache 2.0 license: code is available on GitHub, ClawGUI-2B model weights are published on HuggingFace and ModelScope, and the evaluation dataset is available on HuggingFace Datasets.
ClawGUI-2B was trained entirely within the framework using online reinforcement learning: the agent interacts with 64 parallel phone emulators on 8 GPUs, attempts to complete tasks, and updates its weights based on the outcome — no pre-collected dataset required. On the MobileWorld GUI-Only benchmark the model achieves 17.1% task completion. The benchmark consists of 117 real mobile tasks — send a message, find a contact, change a setting, place an order — and the agent completes them purely through the visual interface, without any programmatic access to the apps. Only full completion counts: partial progress does not. 17.1% is 54% better than the baseline MAI-UI-2B of the same scale, and above significantly larger models: Qwen3-VL-32B (16x more parameters) scores 11.9%, UI-Venus-72B (36x larger) scores 16.4%.
What is a GUI agent
A GUI agent is a model that sees a screen and controls it: clicks, scrolls, types. Unlike API-based agents, it works with any application without special integration — just like a person at a computer. This applies beyond phones: desktop apps, browsers, web services — anything with a visual interface.
Progress in this area is held back not by a lack of ideas, but by three specific infrastructure problems. Nobody publishes training code for these agents — results exist, but they cannot be reproduced. Numbers across papers are incomparable because every team evaluates models differently. And finally, trained agents almost never reach real users — they stay inside the lab.
ClawGUI-RL: training GUI agents with reinforcement learning on real devices
ClawGUI-RL is the first open-source infrastructure for online RL training of GUI agents with validated support for both parallel virtual environments (Docker-based Android emulators) and real physical devices. The module code is in the clawgui-rl directory.
The key technical challenge is environment management. Emulators can freeze or crash during long training runs. ClawGUI-RL addresses this through server rotation: when a container becomes unhealthy, it is automatically replaced by a healthy one from the queue, and the task continues without interrupting training. Every run can be recorded and replayed, which helps identify where the agent went wrong and, if needed, use those recordings to build new datasets.
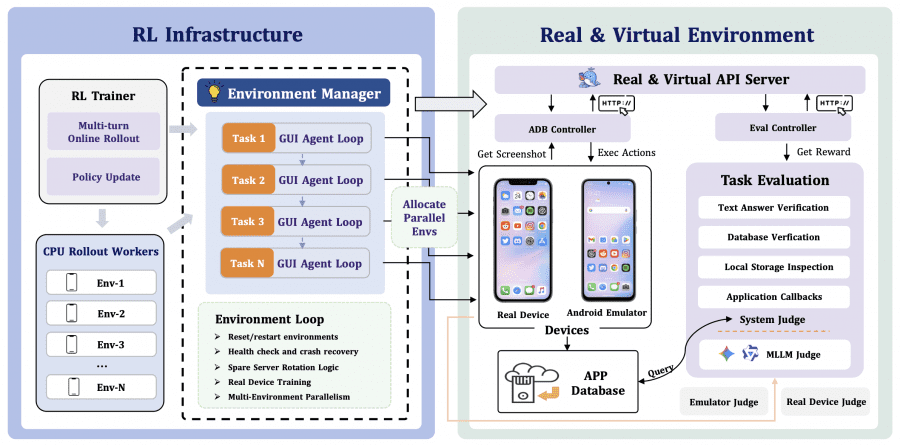
ClawGUI-RL uses a two-level reward function. By default, the agent receives a signal only at the end of a task: success gets 1, failure gets 0. For long tasks this works poorly: the agent takes dozens of steps with no feedback at all and has no idea whether it is moving in the right direction. The authors added a separate evaluator model to fix this. After each action, it looks at the before and after screenshots, analyzes the action history, and scores how much that specific step contributed toward the goal. The final signal is the sum of the outcome score and the per-step scores across the entire episode.
The framework supports several RL algorithms; the authors compared two of them. GRPO evaluates the entire trajectory and assigns the same signal to every step in the episode — regardless of whether it was a stray misclick at the start or the decisive tap at the end. GiGPO works more precisely: it compares steps that found themselves in the same situation across different runs, and scores each action individually. This matters especially for long tasks, where the quality of intermediate actions varies significantly. Replacing GRPO with GiGPO yielded +2.6% in Success Rate, or +17.9% relatively.
ClawGUI-Eval: reproducible evaluation across 6 benchmarks
ClawGUI-Eval addresses the incomparable-results problem through a strictly standardized three-stage pipeline: first inference — the model generates predictions; then judging — predictions are checked against ground truth; then metric computation. All settings for each model are fixed and documented. The dataset is published on HuggingFace, and the code is in the clawgui-eval/ directory.
The framework covers 6 benchmarks and 11+ models, including Qwen3-VL, UI-TARS, MAI-UI, Gemini, and Seed 1.8. Evaluation can be run locally on a GPU or through any OpenAI-compatible API. The result: 95.8% reproduction rate against official results across 48 model-benchmark pairs — a result is considered reproduced if the difference from the official number does not exceed 2%. This is the first time in the GUI agent field that someone else’s numbers can actually be verified.
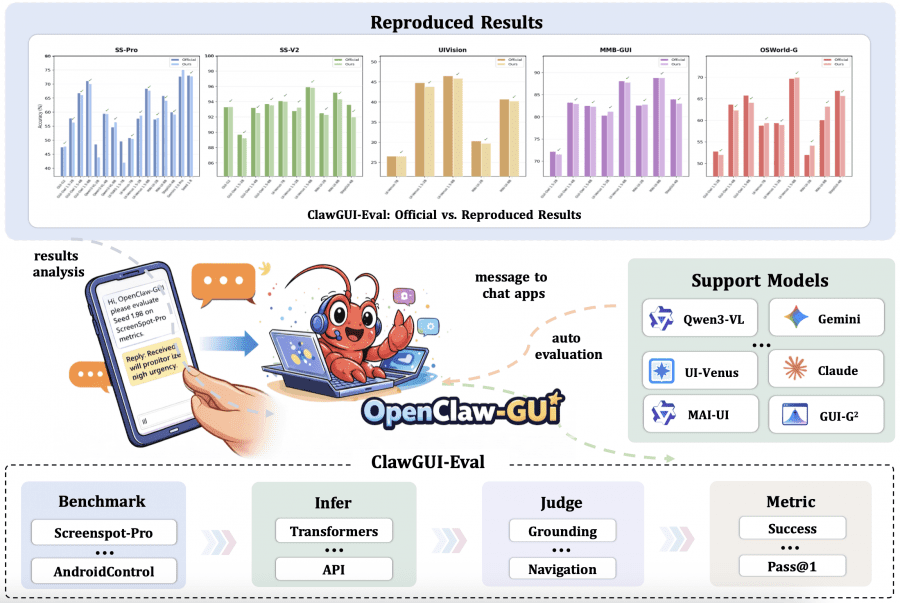
Two of the 48 reproduction attempts failed: Qwen3-VL-2B and UI-TARS 1.5-7B on ScreenSpot-Pro. Both models share one thing in common: their official evaluation configurations have not been publicly disclosed. This directly suggests that the main cause of irreproducibility in the GUI agent field is not a fundamental problem, but an infrastructure one — undocumented prompt and resolution settings. For closed-source models (Gemini, Seed 1.8), the authors applied a Zoom strategy — a two-stage crop-then-localize approach — which successfully reproduced official results without access to model weights.
One additional feature: ClawGUI-Eval is built into ClawGUI-Agent as a skill. Instead of writing scripts, you just send a message like “benchmark qwen3vl on screenspot-pro” — the agent will check the environment, launch parallel inference, evaluate results, and return a report comparing against official numbers.
ClawGUI-Agent: deployment on Android, HarmonyOS, and iOS
ClawGUI-Agent closes the loop from research to real users. Built on top of OpenClaw and powered by the nanobot engine. Supports device control through three protocols: Android via ADB, HarmonyOS via HDC, iOS via XCTest. Connects to 12+ chat platforms including WeChat, DingTalk, Feishu, Telegram, Discord, Slack, and QQ. Module code is in the clawgui-agent/ directory.
There are two operating modes: remote (the user controls a phone from another device via a messenger) and local (commands sent directly from the phone itself, no cloud required). For those who prefer a web interface, a Gradio UI is available for device management, task monitoring, and memory inspection.
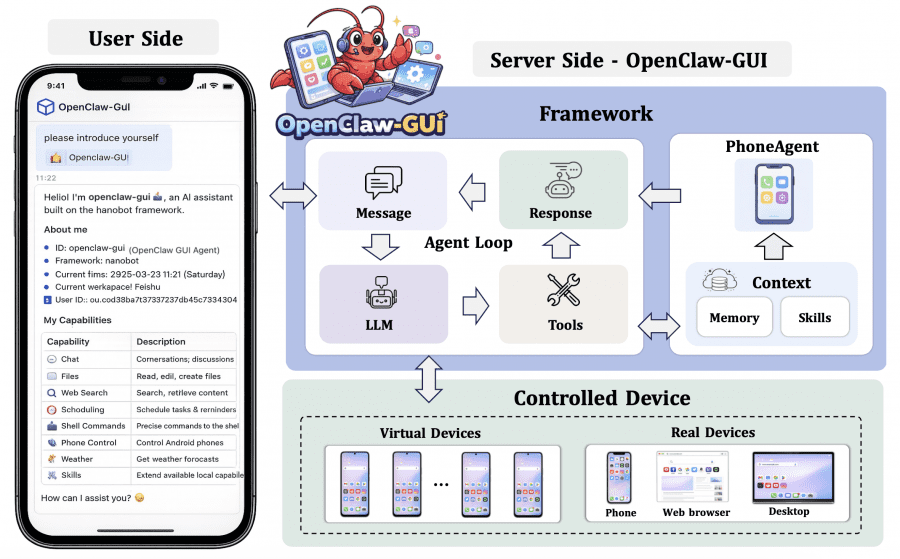
The hybrid device control approach works as follows: where an application supports a programmatic interface, the agent uses CLI (fast and precise); where it does not, it falls back to GUI (universal). During task execution, the agent automatically memorizes structured facts — contact names, frequently used apps, user habits — and stores them as vector embeddings in a persistent store. On subsequent tasks, the most relevant memories are retrieved and added to the context. Duplicates are detected and merged rather than accumulated. Every task execution is recorded as a structured episode, which can be replayed and used to build new datasets.
The ClawGUI-2B model
ClawGUI-2B is built on top of MAI-UI-2B and trained from scratch inside ClawGUI-RL: 64 parallel Android emulators, 8×A6000 GPUs with 48 GB each, GiGPO algorithm, 3 training epochs. Qwen3.5-72B was used as the evaluator model for step-level rewards — it examined each agent action and decided how much it contributed toward the goal. The model can be downloaded from HuggingFace and ModelScope.
Results: a small well-trained model vs. large untrained ones
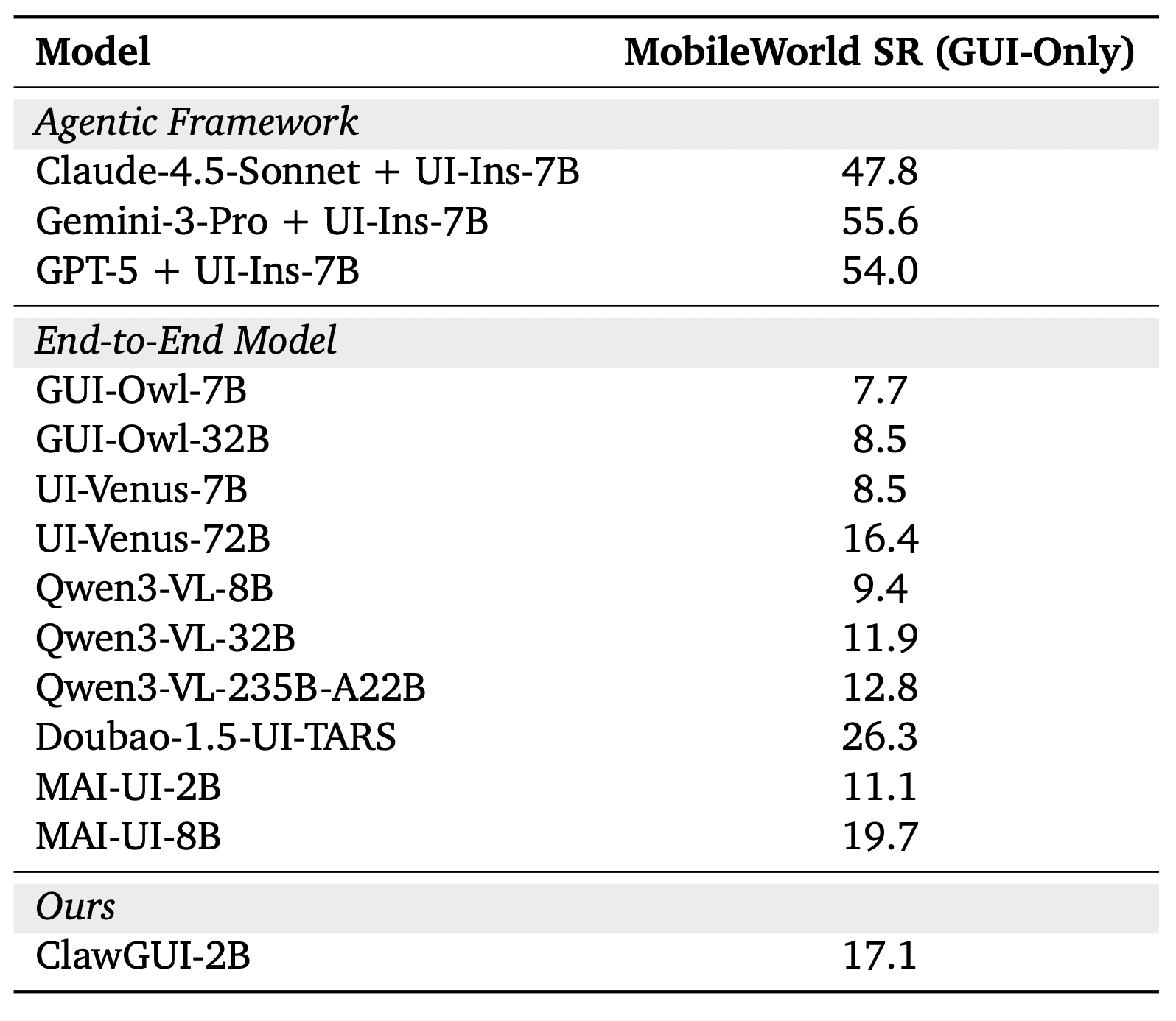
ClawGUI-2B achieved 17.1% task completion on MobileWorld GUI-Only. MAI-UI-2B with the same weights and the same scale scores 11.1%. The entire gain over MAI-UI-2B comes exclusively from the ClawGUI-RL infrastructure: both start from the same weights. This is direct evidence that training quality matters more than model scale.

Agentic frameworks with proprietary models (Gemini-3-Pro + UI-Ins-7B: 55.6%, GPT-5 + UI-Ins-7B: 54.0%) show significantly higher numbers. But the comparison is not entirely fair: Claude and Gemini here are paired with a separate model specialized in accurately locating screen elements, and are significantly more expensive to run. ClawGUI-2B is a compact model that can be run locally and fine-tuned for specific tasks.
Can this be used right now
The model can be fine-tuned for a specific application, which will improve accuracy compared to the general-purpose version. If tasks are repetitive and well-defined — for example, the same smoke test on the same app — the model can learn that scenario significantly better. The infrastructure is open. Renting one A6000 in the cloud costs from $0.27/hr on Thunder Compute to $0.91/hr on Lambda — with 8 GPUs that is $2.16 to $7.28 per hour in total.
That said, expectations should be calibrated carefully. 17.1% on MobileWorld reflects performance across diverse tasks from many different apps. On a narrow specialized task the result will be higher, but by how much depends on UI stability across app versions, the length of the action chain, and how well the model perceives the specific interface elements involved. By rough estimate, for short scenarios 40–60% is a reasonable target — and the agent will most likely be useful as a tool with human oversight rather than a fully autonomous tester. That is still better than writing and maintaining scripts by hand.
What comes next
According to the roadmap on GitHub, the next steps include: running the agent directly on the phone without a cloud server intermediary (currently user commands are processed on the server before being sent to the device, which raises privacy concerns), extending RL training to desktop and web environments, and real-time training.
A longer-term goal is to teach the agent to predict how the screen will change in response to an action before that action is taken. Currently the agent works reactively: it sees a screenshot, takes a step, observes what happened. If the model learns to anticipate the consequences of actions in advance, it will be able to plan several steps ahead — much like a person mentally running through a scenario before clicking anything.
“`