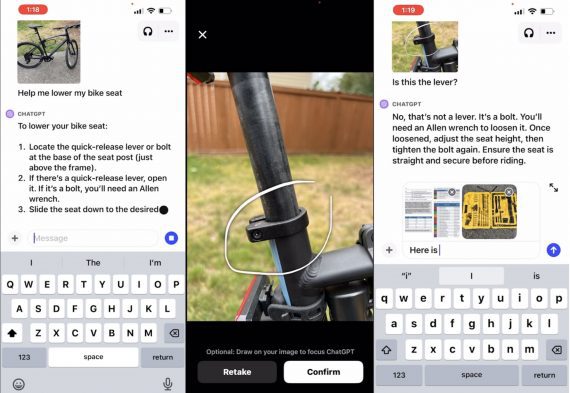
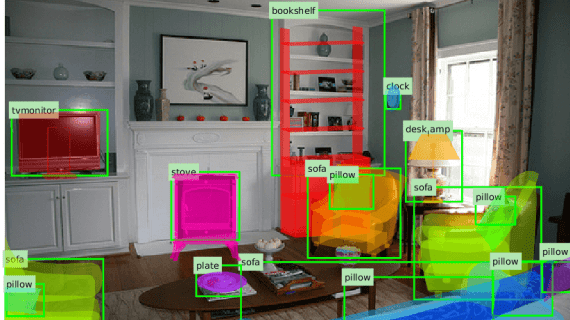
ClawGUI: the first open-source end-to-end framework for GUI agents — from training to real device
15 April 2026

ClawGUI: the first open-source end-to-end framework for GUI agents — from training to real device
Researchers from Zhejiang University have published ClawGUI — a fully open-source framework for building GUI agents that control applications through their visual interface, just like a human would: taps, swipes,…