Robotics, augmented reality, autonomous driving – all these scenarios rely on recognizing 3D properties of objects from 2D images. This puts 3D object recognition as one of the central problems in computer vision.
Remarkable progress has been achieved in this field after the introduction of several databases that provide 3D annotations to 2D objects (e.g., IKEA, Pascal3D+). However, these datasets are limited in scale and include only about a dozen object categories.
This is not even close to the large-scale image datasets such as ImageNet or Microsoft COCO, while these are huge datasets that stay behind the significant progress in image classification task in recent years. Consequently, large-scale datasets with 3D annotations are likely to significantly benefit 3D object recognition.
In this article, we present one large-scale dataset, ObjectNet3D, and also several specialized datasets for 3D object recognition: MVTec ITODD and T-LESS – for industry settings and Falling Things dataset – for object recognition tasks in the context of robotics.
ObjectNet3D
Number of images: 90,127
Number of objects: 201,888
Number of categories: 100
Number of 3D shapes: 44,147
Year: 2016
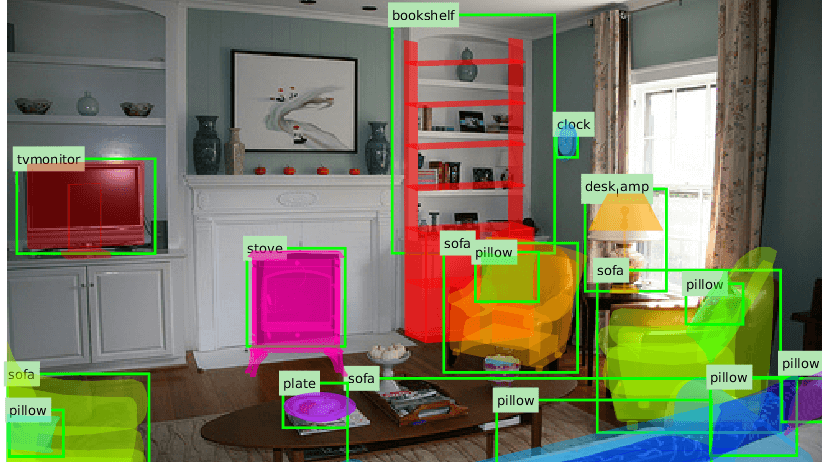
ObjectNet3D is a large-scale database, where objects in the images are aligned with the 3D shapes, and the alignment provides both accurate 3D pose annotation and the closest 3D shape annotation for each 2D object. The scale of this dataset allows for significant progress with such computer vision tasks as recognizing 3D pose and 3D shape of objects from 2D images.

To construct this database, resort to images from existing image repositories and propose an approach to align 3D shapes (available from existing 3D shapes repositories) to the objects in these images.
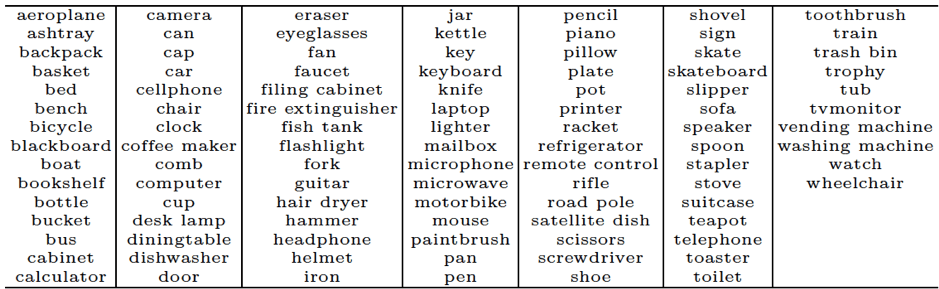
In their work, the researchers consider only rigid object categories, for which they can collect a large number of 3D shapes from the web. Here is the full list of categories:
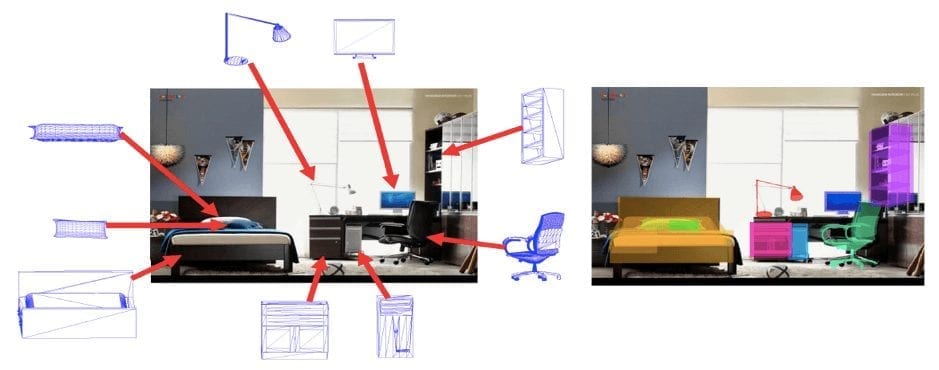
2D images were collected from the ImageNet dataset and additionally, through Google Image Search for categories that are not sufficiently covered by the ImageNet dataset. 3D shapes were acquired from Trimble 3D Warehouse and ShapeNet repository. Then, objects in the image were aligned with the 3D shapes using a camera model, which is described in detail in the corresponding paper. Finally, 3D annotations were provided to objects in 2D images.
The resulting dataset can be used for object proposal generation, 2D object detection, joint 2D detection and 3D object pose estimation, image-based 3D shape retrieval.
MVTec ITODD
Number of scenes: 800
Number of objects: 28
Number of 3D transformations: 3500
Year: 2017

MVTec ITODD is a dataset for 3D object detection and pose estimation with a strong focus on industrial settings and applications. It contains 28 objects arranged in over 800 scenes and labeled with their rigid 3D transformation as ground truth. The scenes are observed by two industrial 3D sensors and three grayscale cameras, allowing to evaluate methods that work on 3D, image, or combined modalities. The dataset’s creators from MVTec Software GmbH have chosen to use grayscale cameras because they are much more prominent in industrial setups.
As mentioned in the dataset description, the objects were selected such that they cover a range of different values with respect to surface reflectance, symmetry, complexity, flatness, detail, compactness, and size. Here are the images of all objects included to the MVTec ITODD along with their names:

For each object, scenes with only a single instance and scenes with multiple instances (e.g., to simulate bin picking) are available. Each scene was acquired once with each of the 3D sensors, and twice with each of the grayscale cameras: once with and once without a random projected pattern.
Finally, for all objects, manually created CAD models are available for training the detection methods. The ground truth was labeled using a semi-manual approach based on the 3D data of the high-quality 3D sensor.
This dataset provides a great benchmark for the detection and pose estimation of 3D objects in the industrial scenarios.
T-LESS
Number of images: 39K training + 10K test images from each of three sensors
Number of objects: 30
Year: 2017

T-LESS is a new public dataset for estimating the 6D pose, i.e. translation and rotation, of texture-less rigid objects. This dataset includes 30 industry-relevant objects with no significant texture and no discriminative color or reflectance properties. Another unique property of this dataset is that some of the objects are parts of others.
Researchers behind T-LESS have chosen different approaches to the training images and test images. Thus, training images in this dataset depict individual objects against a black background, while test images originated from twenty scenes with varying degree of complexity. Here are the examples of training and test images:

All the training and test images were captured with three synchronized sensors, including a structured-light and a time-of-flight RGB-D sensor and a high-resolution RGB camera.
Finally, two types of 3D models are provided for each object: 1) manually created CAD model, and 2) a semi-automatically reconstructed one.
This dataset can be very useful for evaluating approaches to 6D object pose estimation, 2D object detection and segmentation, 3D object reconstruction. Considering the availability of images from three sensors, it is also possible to study the importance of different input modalities for a given problem.
Falling Things
Number of images: 61, 500
Number of objects: 21 household objects
Year: 2018

The Falling Things (FAT) dataset is a synthetic dataset for 3D object detection and pose estimation, created by NVIDIA team. It was generated by placing 3D household object models (e.g., mustard bottle, soup can, gelatin box, etc.) in virtual environments.
Each snapshot in this dataset consists of per-pixel class segmentation, 2D/3D bounding box coordinates for all objects, mono and stereo RGB images, dense depth images, and of course, 3D poses. Most of these elements are illustrated in the above image.

The FAT dataset includes the variety of object poses, backgrounds, composition, and lighting conditions. See some examples below:
For more details on the process of building the FAT dataset, check our article dedicated entirely to this dataset.
The Falling Things dataset provides a great opportunity to accelerate research in object detection and pose estimation, as well as segmentation, depth estimation, and sensor modalities.
Bottom Line
3D object recognition has multiple important applications, but progress in this field is limited by the available datasets. Fortunately, there were several new 3D object recognition datasets introduced in recent years. While they have different scale, focus and characteristics, each of these datasets makes a significant contribution to the improvement of current 3D object recognition systems.