
Action recognition is vital for many real-life applications, including video surveillance, healthcare, and human-computer interaction. What do we need to do to classify video clips based on the actions being performed in these videos?
We need to identify different actions from video clips where the action may or may not be performed throughout the entire duration of the video. This looks similar to the image classification problem, but in this case, the task is extended to multiple frames with further aggregation of the predictions from each frame. And we know that after the introduction of the ImageNet dataset, deep learning algorithms are doing a pretty good job in image classification. But do we observe the same progress in video classification or action recognition tasks?
Actually, there is a number of things that turn action recognition into a much more challenging task. This includes huge computational cost, capturing long context, and of course, a need for good datasets.
A good dataset for action recognition problem should have a number of frames comparable to ImageNet and diversity of action classes that will allow for generalization of the trained architecture to many different tasks.
Fortunately, several such datasets were presented during the last year. Let’s have a look.
Kinetics-600
Number of videos: 500,000
Number of action classes: 600
Year: 2018
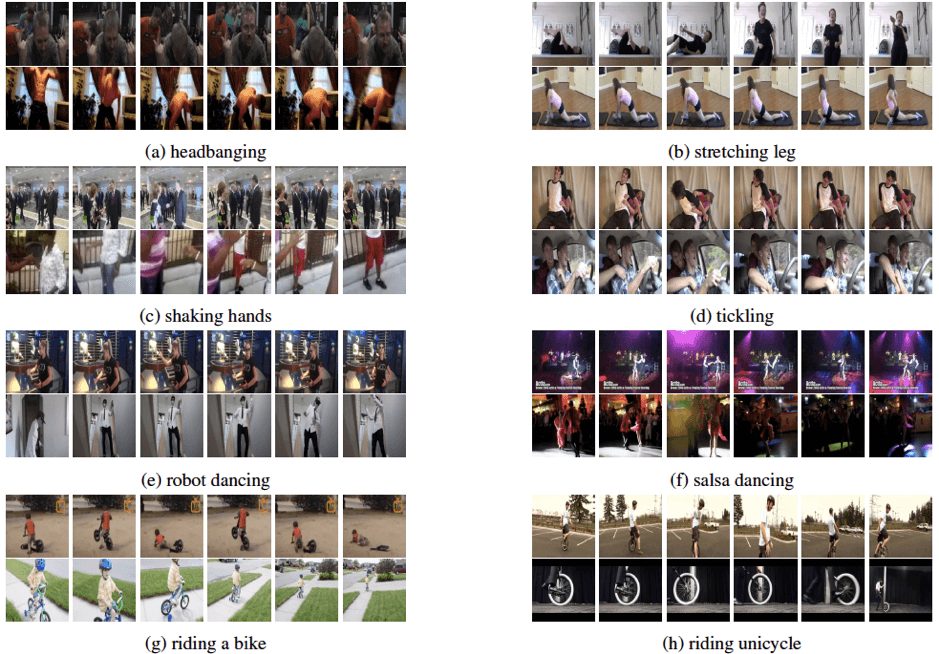
We start with the dataset introduced by Google’s DeepMind team. This is a Kinetics dataset – a large-scale, high-quality dataset of YouTube URLs created to advance models for human action recognition. Its last version is called Kinetics-600 and includes around 500,000 video clips that cover 600 human action classes with at least 600 video clips for each action class.
Each clip in Kinetics-600 is taken from a unique YouTube video, lasts around 10 seconds and is labeled with a single class. The clips have been through multiple rounds of human annotation. A single-page web application was built for the labeling task, and you can see the labeling interface below.
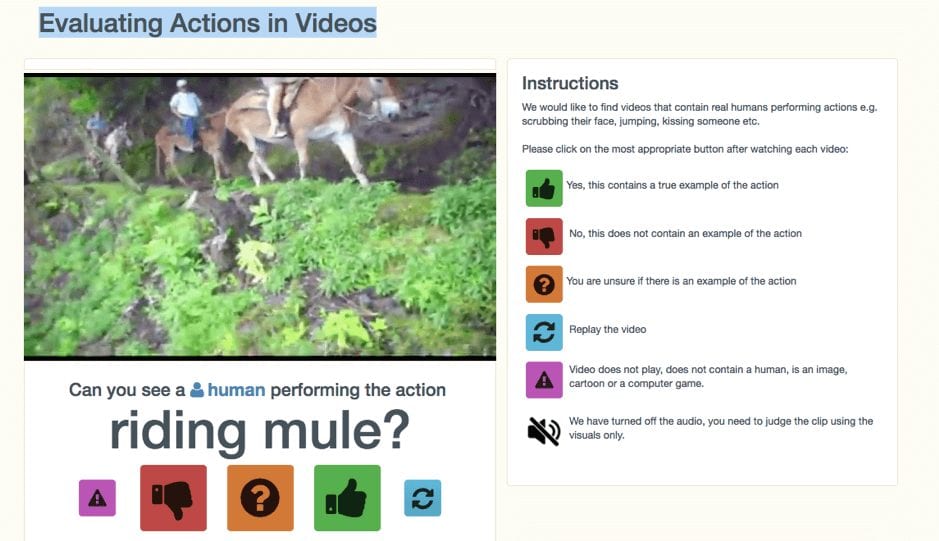
If a worker responded with ‘Yes’ to the initial question “Can you see a human performing the action class-name?”, he was also asked the follow-up question “Does the action last for the whole clip?” in order to use this signal later during model training.
The creators of Kinetics-600 have also checked if the dataset is gender balanced and discovered that approximately 15% of action classes are imbalanced but this doesn’t lead to a biased performance.
The actions cover a broad range of classes including human-object interactions such as playing instruments, arranging flowers, mowing a lawn, scrambling eggs and so on.
Moments in Time
Number of videos: 1,000,000
Number of action classes: 339
Year: 2018

Moments in Time is another large-scale dataset, which was developed by the MIT-IBM Watson AI Lab. With a collection of one million labeled 3-second videos, it is not restricted to human actions only and includes people, animals, objects and natural phenomena, that capture the gist of a dynamic scene.
The dataset has a significant intra-class variation among the categories. For instance, video clips labeled with the action “opening” include people opening doors, gates, drawers, curtains and presents, animals and humans opening eyes, mouths and arms, and even a flower opening its petals.
That’s natural for the humans to recognize that all of the above-mentioned scenarios belong to the same category “opening” even though visually they look very different from each other. So, as pointed out by the researchers, the challenge is to develop deep learning algorithms that will be also able to discriminate between different actions, yet generalize to other agents and settings within the same action.
The action classes in Moments in Time dataset are chosen such that they include the most commonly used verbs in the English language, covering a wide and diverse semantic space. So, there are 339 different action classes in the dataset with 1,757 labeled videos per class on average; each video is labeled with only one action class.

As you can see from the image, the annotation process was very straightforward: workers were presented with video-verb pairs and asked to press a Yes or No key responding if the action is happening in the scene. For the training set, the researchers run each video through annotation at least 3 times and required a human consensus of at least 75%. For the validation and test sets, they increased the minimum number of rounds of annotation to 4 with a human consensus of at least 85%.
SLAC
Number of videos: 520,000 videos –> 1.75M 2-second clips
Number of action classes: 200
Year: 2017
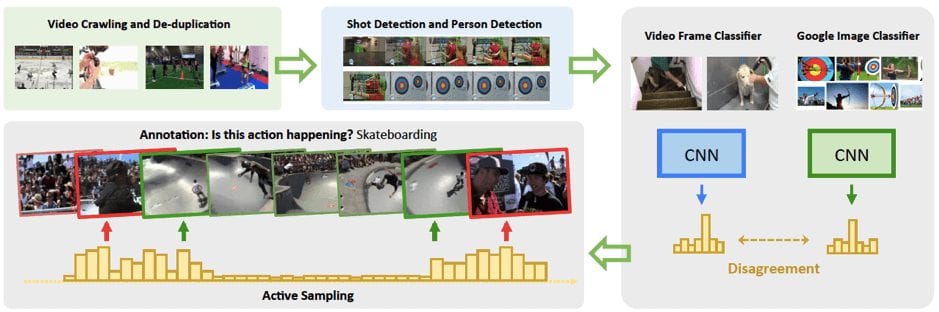
A Sparsely Labeled ACtions Dataset (SLAC) is introduced by the group of researchers from MIT and Facebook. The dataset is focused on human actions, similarly to Kinetics, and includes over 520K untrimmed videos retrieved from YouTube with an average length of 2.6 minutes. 2-second clips were sampled from the videos by a novel active sampling approach. This resulted in 1.75M clips, including 755K positive samples and 993K negative samples as annotated by a team of 70 professional annotators.
As you see, the distinctive feature of this dataset is the presence of negative samples. See the illustration of negative samples below.

The dataset includes 200 action classes taken from the ActivityNet dataset.
Please note that even though the paper introducing this dataset was released in December 2017, the dataset is still not available for download. Hopefully, this will change very soon.
VLOG
Number of videos: 114,000
Year: 2017

The VLOG dataset differs from the previous datasets in the way it was collected. The traditional approach to getting data starts with a laundry list of action classes and then searching for the videos tagged with the corresponding labels.
However, such an approach runs into trouble because everyday interactions are not likely to be tagged on the Internet. Could you imagine uploading and tagging video of yourself opening a microwave, opening a fridge, or getting out of bed? The people tend to tag unusual things like for example, jumping in a pool, presenting the weather, or playing the harp. As a result, available datasets are often imbalanced with more data featuring unusual events and less data on our day-to-day activities.
To solve this issue, the researchers from the University of California suggest starting out with a superset of what we actually need, namely interaction-rich video data, and then annotating and analyzing it after the fact. They start data collection from the lifestyle VLOGs – an immensely popular genre of video that people publicly upload to YouTube to document their lives.

As the data was gathered implicitly, it represents certain challenges for annotation. The researchers decided to focus on the crucial part of the interaction, the hands, and how they interact with the semantic objects at a frame level. Thus, this dataset can also make headway on the difficult problem of understanding hands in action.
Bottom Line
The action recognition problem requires huge computational costs and lots of data. Fortunately, several very good datasets have appeared during the last year. Together with the previously available benchmarks (ActivityNet, UCF101, HMDB), they build a great foundation for significant improvements in the performance of the action recognition systems.







[…] Quelle […]
Thanks, I have just been looking for information about this subject for a long time and yours is the best I’ve discovered till now. However, what in regards to the… Read more »
I do agree with all the ideas you have introduced on your post. They are very convincing and will definitely work. Still, the posts are very short for newbies. May… Read more »