
Face recognition is a common task in deep learning, and convolutional neural networks (CNNs) are doing a pretty good job here. I guess Facebook usually performs right at recognizing you and your friends in the uploaded images.
But is this really a solved problem? What if the picture is obfuscated? What if the person impersonates somebody else? Can heavy makeup trick the neural network? How easy is it to recognize a person who wears glasses?
Disguised face recognition is still quite a challenging task for neural networks and primarily due to the lack of corresponding datasets. In this article, we are going to feature several face datasets presented recently. Each of them reflects different aspects of face obfuscation, but their goal is the same – to help developers create better models for disguised face recognition.
Disguised Faces in the Wild
Number of images: 11,157
Number of subjects: 1,000
Year: 2018
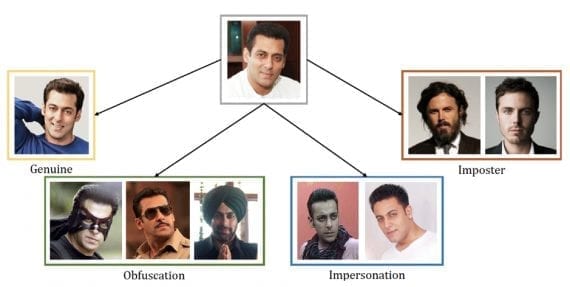
We will start with the most recent dataset presented earlier this year – Disguised Faces in the Wild (DFW). It primarily contains images of celebrities of Indian or Caucasian origin. The dataset focuses on a specific challenge of face recognition under the disguise covariate.
According to the DFW’s description, it covers disguise variations for hairstyles, beard, mustache, glasses, make-up, caps, hats, turbans, veils, masquerades and ball masks. This is coupled with other variations for pose, lighting, expression, background, ethnicity, age, gender, clothing, and camera quality.
There are four types of images in the dataset:
- Normal Face Image: each subject has a non-disguised frontal face image.
- Validation Face Image: 903 subjects have an image, which corresponds to a non-disguised frontal face image and can be used for generating a non-disguised pair within a subject.
- Disguised Face Image: each subject has from 1 to 12 face images with intentional or unintentional disguise.
- Impersonator Face Image: 874 subjects have from 1 to 21 images of the impersonators. An impersonator of a subject refers to a picture of any other person (intentionally or unintentionally) pretending to be the subject’s identity.

In total, the DFW dataset contains 1,000 normal face images, 903 validation face images, 4,814 disguised face images, and 4,440 impersonator images.
Makeup Induced Face Spoofing
Number of images: 642
Number of subjects: 107 + 107 target subjects
Year: 2017

Makeup Induced Face Spoofing dataset (MIFS) is also about impersonating but with the specific focus on makeup. The researchers extracted the images from the YouTube videos where female subjects were applying makeup to transform their appearance to resemble celebrities. It should be noted, though, that the subjects were not trying to deceive an automated face recognition system deliberately but rather, they intended to impersonate a target celebrity from a human vision perspective.
The dataset consists of 107 makeup-transformations with two before-makeup and two after-makeup images per subject. Additionally, two face images of the target identity were taken from the Internet and included to the dataset. However, it is important to point out that the target images are not necessarily those used by the spoofer as a reference during the makeup transformation process. The celebrities sometimes change their facial appearance drastically, and so, the researchers were trying to select target identity images that most resembled the after-makeup image.
And finally, all the acquired images were subjected to face cropping. This routine eliminates hair and accessories. The examples of the cropped images are provided below.

So, in total, the MIFS dataset contains 214 images of a subject before makeup; 214 images of the same subject after makeup with the intention of spoofing; and 214 images of the target subject who is being spoofed. It should also be noted that subjects are attempting to spoof multiple target identities resulting in duplicate subject identities and even multiple subjects are attempting to spoof the same target identity resulting in duplicate target identities.
Specs on Faces dataset
Number of images: 42,592
Number of subjects: 112
Year: 2017

It looks like glasses as a natural occlusion threaten the performance of many face detectors and facial recognition systems. That’s why such a dataset with all the subjects wearing glasses is of particular importance. Specs on Faces dataset (SoF) comprises 2,662 original images of size 640 × 480 pixels for 112 persons (66 males and 46 females) from different ages. The glasses are the common natural occlusion in all images of the dataset. This original set of images consists of two parts:
- 757 unconstrained face images in the wild that were captured over a long period in several locations under indoor and outdoor illumination environments;
- 1905 images that are specifically dedicated to challenging harsh illumination changes: 12 persons were filmed under a single lamp located in arbitrary locations to emit light rays in random directions.

Then, for each image of the original set, there are:
- 6 extra pictures generated by the synthetic occlusions – nose and mouth occlusion using a white block;
- 9 additional pictures made with the image filters: Gaussian noise, Gaussian blur, and image posterization using fuzzy logic.
So, in total, the SoF dataset includes 42,592 images of 112 persons and a huge bonus – handcrafted metadata that contains subject ID, view (frontal/near-frontal) label, 17 facial feature points, face and glasses rectangle, gender and age labels, illumination quality, and facial emotion for each subject.
Large Age-Gap Face Verification
Number of images: 3,828
Number of subjects: 1,010 celebrities
Year: 2017

Another challenge is a large age gap. Can the algorithm recognize a personality based on her picture from early childhood? Large-age gap dataset (LAG) was created to help developers with solving this challenging task.
The dataset is constructed with photos of celebrities discovered through the Google Image Search and YouTube videos. The large age gap may have different interpretations: from one side it refers to images with extreme difference in age (e.g., 0 to 80 years old) but on the other hand, it also refers to a significant difference in appearance due to the aging process. For instance, as pointed out by the dataset author, “0 to 15 years old is a relatively small difference in age but has a large change in appearance”.
The LAG dataset reflects both aspects of a large-age gap concept. It contains 3,828 images of 1,010 celebrities. For each identity, at least one child/young image and one adult/old image are present. Starting from the collected images, a total of 5051 matching pairs has been generated.

Bottom Line
The face recognition problem is still topical. There are lots of challenging tasks that significantly threaten the performance of the current facial recognition systems – it turns out that even glasses are a huge problem. Fortunately, the new face image datasets appear regularly. While each of them is focusing on the different aspects of the problem, together they build a great foundation for significant improvements in the performance of the facial recognition systems.






A great resource for disguised face recognition. If anyone is interested you can also check out: Sejong face database: A multi-modal disguise face database Its a disguise face database captured… Read more »