If your application performs landmark detection, face alignment, face recognition or face analysis, the first step is always face detection. And in fact, face detection progressed tremendously in the last few years. The existing algorithms successfully address such challenges as large variations in scale, pose or appearance. However, there are still some issues that are not specifically captured by the existing approaches and face detection datasets.
The group of researchers, headed by Hajime Nada from Fujitsu, identified a new set of challenges for face detection and even collected a dataset of face images that involved these issues. In particular, their dataset includes images with rain, snow, haze, illumination variations, motion and focus blur, and lens impediments. Finally, it also contains a set of distractors – images that don’t include human faces but include objects that can be easily mistaken for faces.
Let’s now discover how existing state-of-the-art approaches to face detection perform on this new challenging dataset. Is there a gap between their performance and real-world requirements? We’ll find out right away!
Face detection datasets
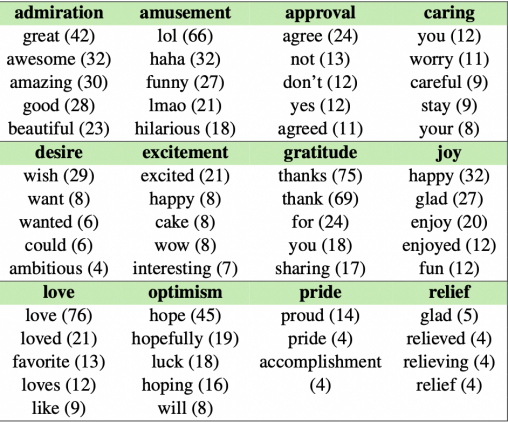
Several datasets have been created specifically for face detection. The table below summarizes information on the most widely used datasets.
Let’s briefly discuss some pros and cons of these datasets:
- AFW includes 205 images collected from Flickr. It has 473 face annotations as well as a facial landmark and poses labels for each face. Variations in face appearance are very limited.
- PASCAL FACE has a total of 851 images with 1,341 annotations. It also has limited variations in facial appearance.
- FDDB has 2,845 images with 5,171 annotations. The authors of this dataset attempted to capture a wide range of difficulties. However, the images were collected from Yahoo! and mainly picture celebrities, making this dataset inherently biased.
- MALF is a large dataset with 5,250 images and 11,900 annotations. It is constructed explicitly for fine-grained evaluations.
- IJB-C is a massive dataset containing 138,000 face images, 11,000 face videos, and 10,000 non-face images. It was explicitly constructed for face detection and recognition.
- WIDER FACE is a recently introduced dataset with over 32,300 images. It includes large variations in scale, pose, and occlusion but doesn’t focus on specifically capturing weather-based degradations.
- UCCS dataset contains some weather-based degradations. However, the images were collected from a single location using a surveillance camera. Hence, this dataset lacks diversity.
As you can see, even though there are some huge datasets with large variations in face appearance, there is still a lack of datasets that capture weather-based degradations and other challenging conditions with a large set of images in each condition.
Here is where the proposed dataset comes in!
UFDD Dataset
Unconstrained Face Detection Dataset (UFDD) includes 6,424 images with 10,895 annotations. It captures variations in weather conditions (rain, snow, haze), motion and focus blur, illumination variations, lens impediments. See the distribution of images in the table below.

Notably, the UFDD dataset also includes a large set of distractor images that is usually ignored by the existing datasets. Distractors either contain non-human faces such as animal faces or no faces at all. The presence of such images is especially important to measure the performance of a face detector in rejecting non-face images and to study the false positive rate of the algorithms.
Images were collected from different sources on the web such as Google, Bing, Yahoo, Creative commons search, Pixabay, Pixels, Wikimedia commons, Flickr, Unsplash, Vimeo, and Baidu. After collection and duplicates removal, the images were resized to have a width of 1024 while preserving their original aspect ratio.
For annotations, the images were uploaded to Amazon mechanical turk (AMT). Each image was assigned to around 5 to 9 AMT workers, who were asked to annotate all recognizable faces in the image. Once the annotation was complete, the labels were cleaned and consolidated.
Evaluation and Analysis
The researchers selected several recent face detection approaches to evaluate them on the proposed UFDD dataset:
- Faster-RCNN is among the first end-to-end CNN-based object detection methods. It was selected as a baseline approach because this method was the first to propose anchor boxes, and now most face detectors are based on anchor boxes.
- HR-ER approach specifically addresses the problem of large variations in scale by designing scale-specific detectors based on ResNet-101.
- SSH consists of multiple detectors placed on top of different conv layers of VGG-16 to explicitly address scale variations.
- S3FD is based on the popular object detection framework called single shot detector (SSD) with VGG-16 as the base network.
These algorithms were evaluated on the proposed UFDD dataset in two different scenarios:
- After they were pre-trained on the original WIDER FACE dataset.
- After they were pre-trained on the synthetic WIDER FACE dataset, which was created by complementing original images with such variations as rain, snow, blur and lens impediments (see the example on the image below).

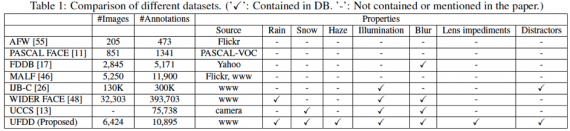
The next figure shows the precision-recall curves corresponding to different approaches as evaluated on the UFDD dataset.
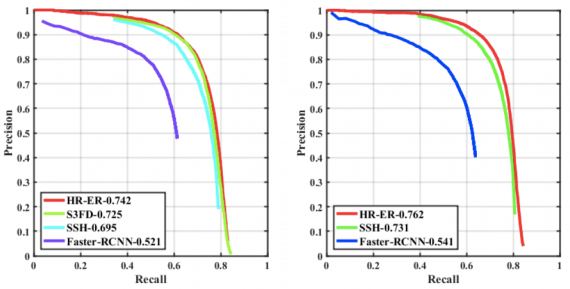
Table 3 below contains the mean average precision (mAP) corresponding to different methods and different training sets.
As you can see, these new challenging conditions are not well-addressed by the existing state-of-the-art approaches. However, the detection performance improves when the networks are trained on the synthesized dataset. This further confirms the necessity of the dataset that reflects the real-world conditions such as rain and haze.
Cohort analysis
Next, the researchers individually analyzed the effect of different conditions on the performance of recent state-of-the-art face detection methods. See below the detections results for all benchmark methods:

Here are the results in the form of precision-recall curves.
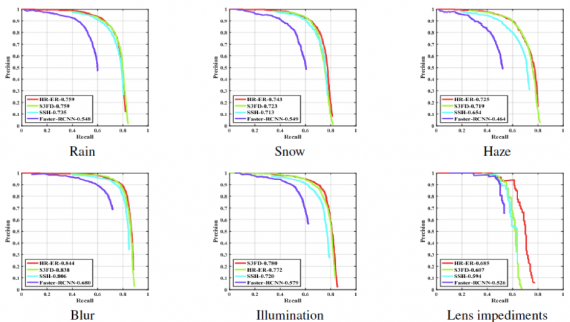
The results demonstrate that all the degradations hinder the performance of the benchmarked methods. This doesn’t come as a surprise considering that they are trained on the datasets that usually don’t include a sufficient number of images with these conditions.
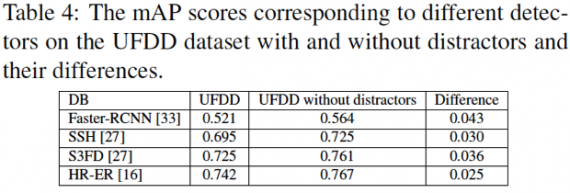
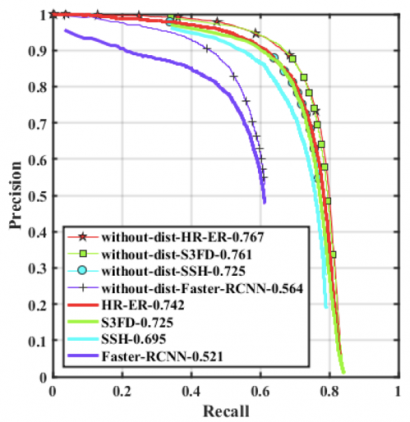
Evaluation results also uncover a significant effect of the distractors on the performance of our face detection algorithms. These images contain objects that can be easily mistaken for human faces, and thus, lead to a high false positive rate. See the drop in the detection accuracies in the presence of distractor images:
Bottom Line
Despite the immense progress in the last few years, face detection algorithms still demonstrate a significant gap in their performance when processing the images taken in extreme weather conditions, containing motion and focus blur or lens impediments. That’s mainly due to the fact that existing datasets ignore these conditions.
The newly created UFDD dataset addresses this issue, and hopefully, it will fuel further research in unconstrained face detection, and we’ll soon witness some new state-of-the-art approaches that can easily detect faces in the extreme conditions.