
In June 2018, IBM announced that an Artificial Intelligence System engaged in the first-ever live, public debates with humans. Their so-called “Project Debater” as the first cognitive system able to debate humans on complex topics, has been tested against a champion debater and proved it is able to engage in a complex debate on controversial topics.
Project Debater
Project Debater is in fact, just one in the series of successful large-scale AI projects from IBM research, that is mainly focused to push one of the boundaries of AI: mastering language. Over a period of six years, a global research team led by IBM’s Haifa, Israel Lab was able to build a cognitive system with remarkable debating capabilities: first, data-driven speech writing and delivery; second, listening comprehension that can identify key claims hidden within long continuous spoken language; and third, modeling human dilemmas in a unique knowledge graph to enable principled arguments.
Building such a complex AI system requires careful identification of separate tasks, as well as careful design and implementation of many modules and sub-modules that will be capable of solving those tasks. To build “Project Debater” involves advancing research in a range of artificial intelligence fields (as noted by IBM). To facilitate this research, the large research team working on Project Debater developed and used a number of datasets and published them as open-source datasets for the community.
IBM’s project debater datasets can be found on this page, and they can be downloaded upon request after filling out a request form. The datasets are released under the following licenses:
© Copyright IBM 2014. Released under CC-BY-SA.
Datasets
All the data under Project Debater dataset repository have been divided into 5 major groups, each one comprising several sub-groups of datasets. This kind of structuring the datasets helps not only organizing the data in the most convenient way but also designing the whole system modules and sub-modules.
1. Argument Detection
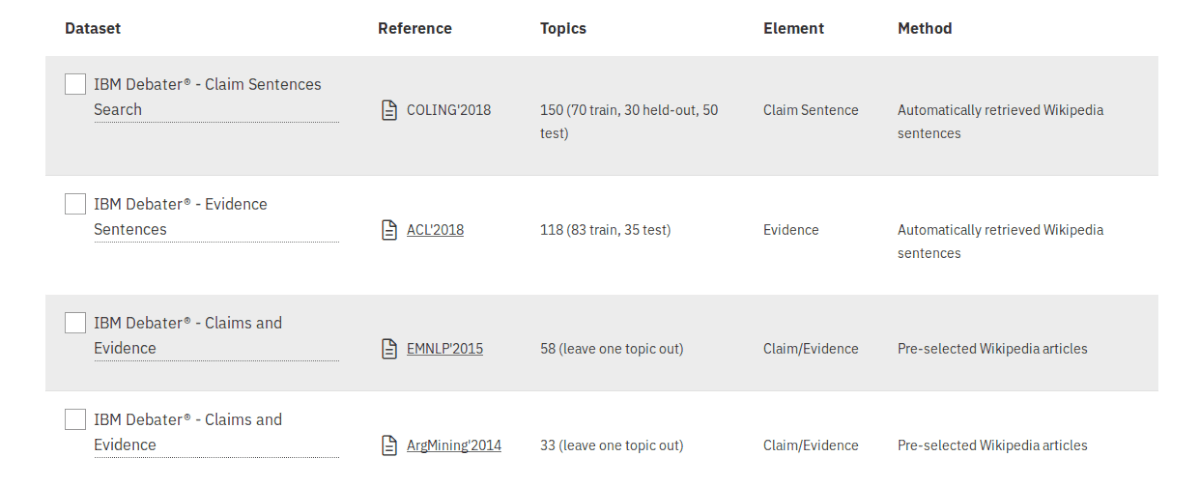
The first major group of datasets is Argument Detection and it falls within the Argument Mining research field, which is considered a prominent AI field. 4 datasets are available under this group: “Claims Sentences Search”, “Evidence Sentences “ and two “Claims and Evidence” datasets.
2. Argument Stance Classification and Sentiment Analysis
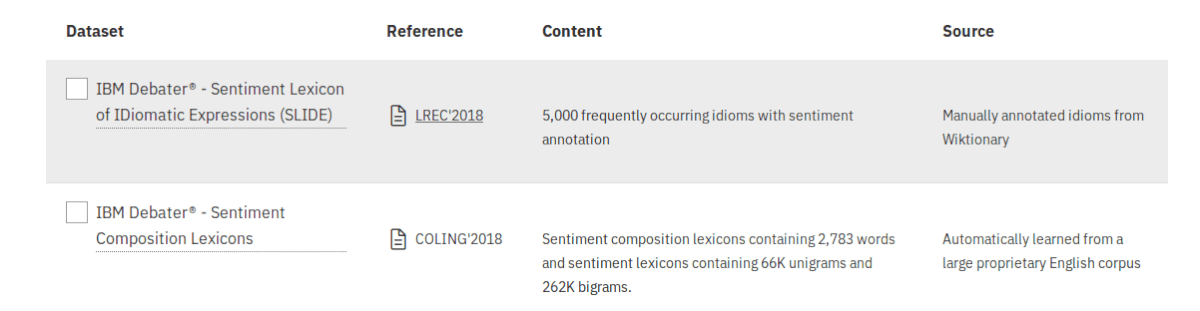
Another major group of NLP datasets from Project Debater is the “Argument Stance Classification and Sentiment Analysis”. It contains three subgroups: Claim Stance (contains one dataset that includes stance annotations for claims), Sentiment Analysis (contains two large datasets that were used to build the stance classification engine) and Expert Stance under which are contained datasets about experts’ stance towards a debate (currently there is only one dataset – Wikipedia Category stance, containing manually extracted Wikipedia categories).
Claim Stance

Semantic Analysis
Expert Stance

3. Debate Speech Analysis
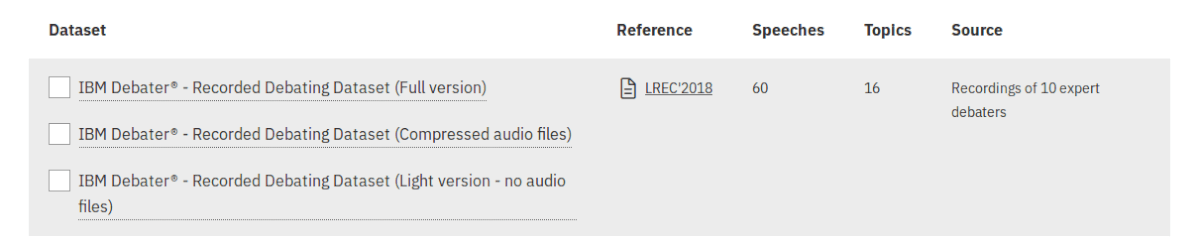
An important part of a debating cognitive system (and many other conversational systems) is speech analysis and understanding. Project Debater built and used “Recorded Debating Dataset” containing recordings of 10 expert debaters. This dataset is available in three versions: full dataset compressed audio files and light version (no audio data).
4. Expressive Text to Speech
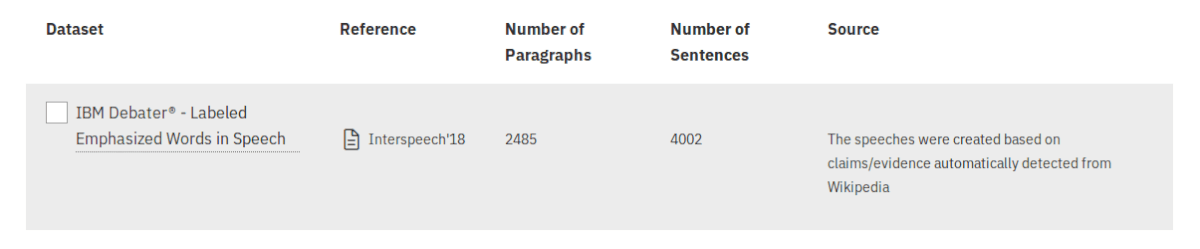
This group contains data on translating text to speech and more specifically (in the single dataset available now under this category) emphasizing some parts or words in the speech.
5. Basic NLP Tasks
The development of a cognitive debating system such as Project Debater involves many basic NLP tasks. This category contains the datasets developed for Project Debater which fall into “basic NLP” and are divided into three sub-groups:
5.1 Semantic Relatedness: Two datasets are available for semantic relatedness tasks: Wikipedia Oriented Relatedness Dataset and Multi-word Term Relatedness Benchmark
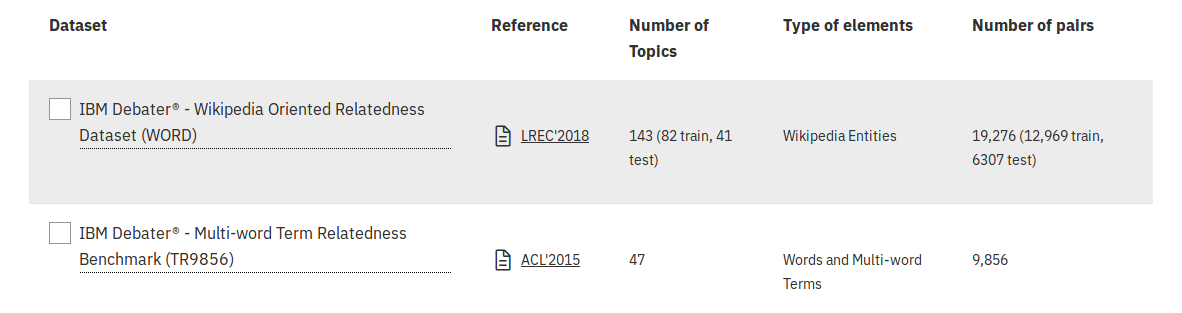
5.2 Mention Detection: A category which contains the datasets related to the task of detecting mentioned concepts (from a knowledge database) in a text (or speech). One dataset is available in this sub-group for the moment.

5.3 Text Clustering: A general group which comprises datasets used for text clustering. As of now, Project Debater has developed and used a single dataset named: “Thematic Clustering of Sentences”.

More datasets from the Project Debater are expected to be released as the project evolves, making the Debater Dataset a large and comprehensive repository of diverse NLP datasets.


