Deep learning made a lot of progress in image recognition and visual arts. The deep learning approach is used to solve the problems of image recognition, image captioning, image segmentation, etc. One of the main problems is that you need a lot of data to train a model and these datasets are not easily available. Lots of research teams working to create different kind of datasets.
Similarly, one of the problem in robotics manipulation requires the detection and pose estimation of multiple object categories. It’s a two-fold challenge for designing robotic perception algorithms. The difficult is creating a model with the less number of training data. Another problem is acquiring ground truth data, which are time-consuming, error-prone and potentially expensive. Existing techniques for obtaining real-world data do not scale. As a result, they are not capable of generating the large datasets that are needed for training deep neural networks.
“Falling Things” Dataset
These problem has been founded when using synthetically generated data. Synthetic data is any production data applicable to a given situation that is not obtained by direct measurement. Researchers have been using synthetic data as an efficient means of both training and validating deep neural networks for which getting ground truth data is very hard such as for segmentation task. 3D pose estimation and detection task lie within this category where acquiring ground truth is complicated and fit for synthetic data.
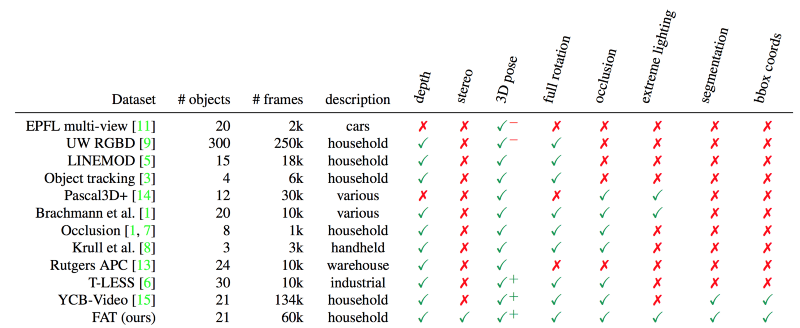
Falling Things (FAT) dataset which consists of more than 61,000 images for training and validating a robotics scene understanding algorithms in a household environment. There are only two datasets are present with accurate ground truth poses of multiple objects, i.e. T-LESS and YCB-Video. But the problem with of these datasets is that they didn’t contain extreme lightning condition and or multiple modalities. But state of the art solution is FAT which incorporates the capabilities which were not present in the other two datasets.

Unreal Engine
The state of the art FAT dataset is generated by using Unreal Engine 4(UE4). The data is generated for three virtual environments within UE4: a kitchen, sun temple, and forest. These environments were chosen for their high-fidelity modeling and quality, as well as for the variety of indoor and outdoor scenes. For every environment, five specific manually selected locations are covering a range of terrain and lighting conditions (e.g., on a kitchen counter or tile floor, next to a rock, above a grassy field, and so forth). By doing this 15 different locations consisting of a variety of 3D backgrounds, lighting conditions, and shadows are yielded.
There are 21 household objects from the YCB. The objects were placed in random positions and orientations within a vertical cylinder of radius 5 cm and height of 10 cm placed at a fixation point. As the objects fell, the virtual camera system was rapidly teleported to random azimuths, elevations, and distances with respect to the fixation point to collect data. Azimuth ranged from –120◦ to +120◦ (to avoid collision with the wall, when present), elevation from 5◦ to 85◦, and distance from 0.5 m to 1.5 m. The virtual camera used in data generation is consist of a pair of stereo RGBD camera. This design decision allows the dataset to support at least three different sensor modalities. Whereas single RGBD sensors are commonly used in robotics, stereo sensors have the potential to yield higher quality output with fewer distortions, and a monocular RGB camera has distinct advantages regarding cost, simplicity, and availability.
The dataset consists of 61,500 unique images having an image resolution of 960 x 540, and it’s divided into two parts:
1. Single Objects: The first part of the dataset was generated by dropping each object model in isolation ∼5 times at each of the 15 locations.
2. Mixed objects: the second part of the dataset was generated in the same manner except for a random number of objects sampled uniformly from 2 to 10. To allow multiple instances of the same category in an image, the object has been sampled with replacement.
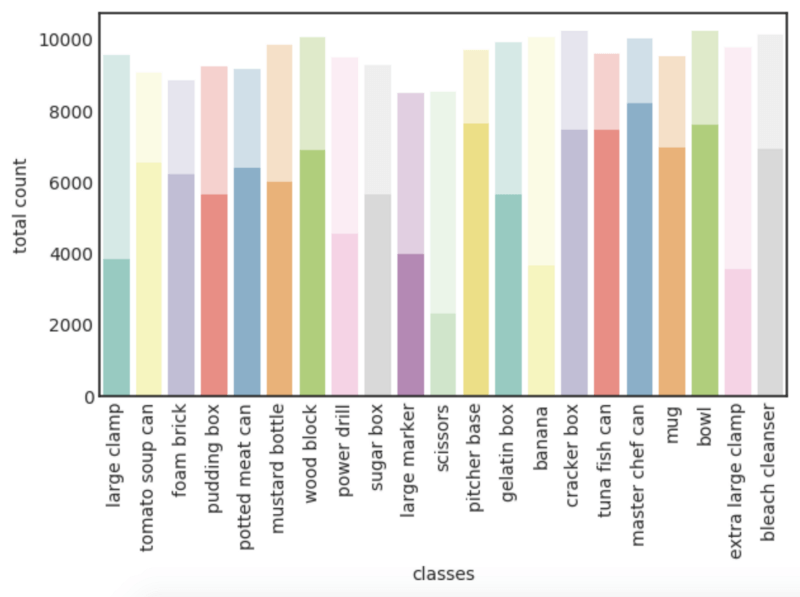
To split the dataset for training and testing is to hold out one location per scene as the test sets, and leave the other data for training. Figure 2 shows the total number of occurrences of each object class in the FAT dataset.
Bottom Line
This new dataset will help to accelerate research in object detection and pose estimation, segmentation and depth estimation. The proposed dataset focuses on household items from the YCB dataset.
This dataset helps researchers to find solutions for open problems like object detection, pose estimation, depth estimation from monocular and/or stereo cameras, and depth-based segmentation, to advance the field of robotics.

Note: The dataset will be publicly available no later than June 2018.