Google MobileDiffusion: Generating Images on Mobile Devices
4 February 2024
Google MobileDiffusion: Generating Images on Mobile Devices
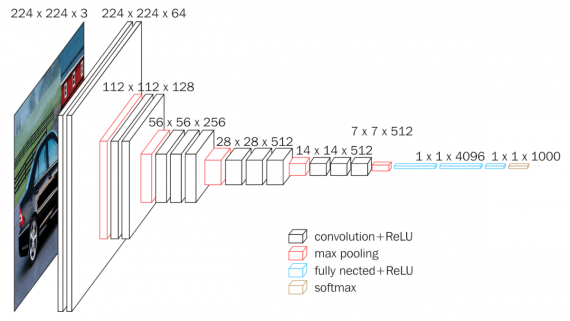
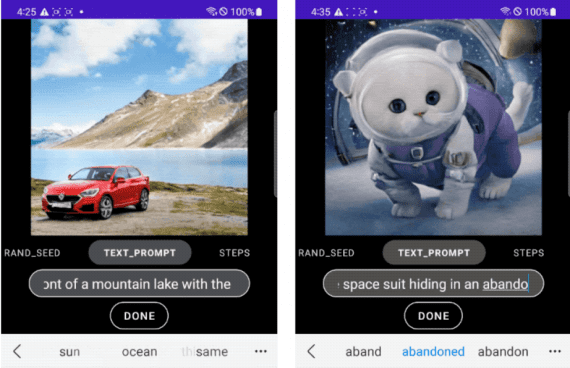
Google has introduced MobileDiffusion, a real-time text-to-image generation model that operates entirely on mobile devices. On Android and iOS devices with the latest generation processors, image generation at a resolution…