The immeasurable amount of multimedia data is recorded and shared in the current era of the Internet. Among it, a video is one of the most common and rich modalities, albeit it is also one of the most expensive to process. Algorithms for fast and accurate video processing thus become crucially important for real-world applications. Video object segmentation, i.e. classifying the set of pixels of a video sequence into the object(s) of interest and background, is among the tasks that despite having numerous and attractive applications, cannot currently be performed in a satisfactory quality level and at an acceptable speed.
The problem is model in a simple and intuitive, yet powerful and unexplored way. The video object segmentation is formulating as pixel-wise retrieval in a learned embedding space. Ideally, in the embedding space, pixels belonging to the same object instance are close together, and pixels from other objects are further apart. The model is built by learning a Fully Convolutional Network (FCN) as the embedding model, using a modified triplet loss tailored for video object segmentation, where no clear correspondence between pixels is given.
There are several main advantages of this formulation: Firstly, the proposed method is highly efficient as there is no fine-tuning in test time, and it only requires a single forward pass through the embedding network and a nearest-neighbour search to process each frame. Secondly, this method provides the flexibility to support different types of user input (i.e., clicked points, scribbles, segmentation masks, etc.) in a unified framework. Moreover, the embedding process is independent of user input. Thus the embedding vectors do not need to be recomputed when the user input changes, which makes this method ideal for the interactive scenario.
Interactive Video Object Segmentation: Interactive Video Object Segmentation relies on iterative user interaction to segment the object of interest. Many techniques have been proposed for the task.
Deep Metric Learning: The key idea of deep metric learning is usually to transform the raw features by a network and then compare the samples in the embedding space directly. Usually, metric learning is performed to learn the similarity between images or patches, and methods based on pixel-wise metric learning are limited.
Proposed Architecture
The problem is to formulate video object segmentation as a pixel-wise retrieval problem, that is, for each pixel in the video, we look for the most similar reference pixel in the embedding space and assign the same label to it. The method consists of two steps:
- First, embed each pixel into a d-dimensional embedding space using the proposed embedding network.
- Secondly, perform per-pixel retrieval in embedding space to transfer labels to each pixel according to its nearest reference pixel.
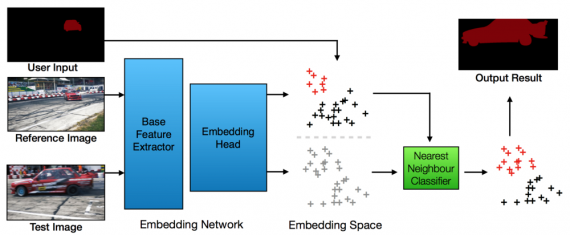
User input to fine-tune the model: The first way is to fine-tune the network to the specific object based on the user input. For example, techniques such as OSVOS or MaskTrack fine-tune the network at test time based on the user input. When processing a new video, they require many iterations of training to adapt the model to the specific target object. This approach can be time-consuming (seconds per sequence) and therefore impractical for real-time applications, especially with a human in the loop.
User input as the network input: Another way of injecting user interaction is to use it as an additional input to the network. In this way, no training is performed at test time. A drawback of these methods is that the network has to be recomputed once the user input changes. This can still be a considerable amount of time, especially for video, considering a large number of frames.
In contrast to above two methods, in the proposed work user input is disentangled from the network computation. Thus the forward pass of the network needs to be computed only once. The only computation after the user input is then the nearest neighbour search, which is very fast and enables rapid response to the user input.
Embedding Model: In the proposed Model f where each pixel xj,i is represented as a d-dimensional embedding vector ej,i = f(xj,i). Ideally, pixels belonging to the same object are close to each other in the embedding space, and pixels belonging to different objects are distant to each other. The embedding model is built on DeepLab based on the ResNet backbone architecture.
- First, the network is pre-train for semantic segmentation on COCO.
- Secondly, the final classification layer is removed and replace it with a new convolutional layer with d output channels.
- Then fine-tune the network to learn the embedding for video object segmentation.
The DEEP lab architecture is a base feature extractor and to the two convolutional layers as embedding head. The resulting network is fully convolutional, thus the embedding vector of all pixels in a frame can be obtained in a single forward pass. For an image of size h × w pixels the output is a tensor [h/8, w/8, d], where d is the dimension of the embedding space. Since an FCN is deployed as the embedding model, spatial and temporal information are not kept due to the translation invariance nature of the convolution operation. Formally, the embedding function can be represented as:
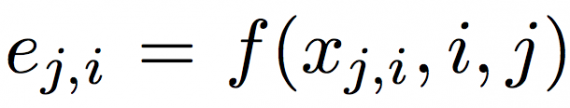
where i and j refer to the ith pixel in frame j. The modified triplet loss is used:
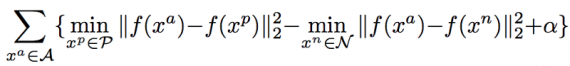
The proposed method is evaluated on the DAVIS 2016 and DAVIS 2017 data sets, both in the semi-supervised and interactive scenario. In the context of semi-supervised Video Object Segmentation (VOS), where the full annotated mask in the first frame is provided as input.
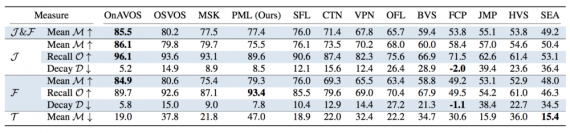
Result
This work presents a conceptually simple yet highly effective method for video object segmentation. The problem is cast as a pixel-wise retrieval in an embedding space learned via a modification of the triplet loss designed specifically for video object segmentation. This way, the annotated pixels on the video (via scribbles, segmentation on the first mask, clicks, etc.) are the reference samples, and the rest of pixels are classified via a simple and fast nearest neighbour approach.