
Face detection is a fundamental problem in computer vision since it is usually a key step towards many subsequent face-related applications, including face parsing, face verification, face tagging and retrieval, etc. Face detection has been widely studied over the past few decades, and numerous accurate and efficient methods have been proposed for most constrained scenarios. Modern face detectors have achieved impressive results on the large and medium faces; however, the performance on small faces is far from satisfactory. The main difficulty for small face (e.g., 10 × 10 pixels) detection is that small faces lack sufficient detailed information to distinguish them from the similar background, e.g., regions of partial faces or hands. Another problem is that modern CNN-based face detectors use the down-sampled convolutional (conv) feature maps with stride 8, 16 or 32 to represent faces, which lose most spatial information and are too coarse to describe small faces.
To deal with the nuisances in face detection, a unified, end-to-end convolutional neural network for better face detection based on the classical generative adversarial network (GAN) framework is proposed. There are two sub-networks in this detector, a generator network, and a discriminator network.
In the generator sub-network, a super-resolution network (SRN) is used to up-sample small faces to a fine scale for finding those tiny faces. Compared to re-sizing by a bilinear operation, SRN can reduce the artefact and improve the quality of up-sampled images with large upscaling factors. However, even with such sophisticated SRN, up-sampled images are unsatisfactory (usually blurring and lacking fine details) due to faces of very low resolutions (10 × 10 pixels).
Therefore, a refinement network (RN) is proposed to recover some missing details in the up-sampled images and generate sharp, high-resolution images for classification. The generated images and real images pass through the discriminator network to JOINTLY distinguish whether they are real images or generated high-resolution images and whether they are faces or non-faces. More importantly, the classification loss is used to guide the generator to generate clearer faces for easier classification.
Network Architecture
The generator network includes two components (i.e. upsample sub-network and refinement sub-network), and the first sub-network takes the low-resolution images as the inputs and the outputs are the super-resolution images. Since the blurry small faces lack fine details and due to the influence of MSE loss, the generated super-resolution faces are usually blurring. So the second subnetwork is used to refine the super-resolution images from the first sub-network. In the end, a classification branch is added to the discriminator network for the purpose of detection, which means the discriminator network can classify faces and non-faces as well as distinguish between the fake and real images.
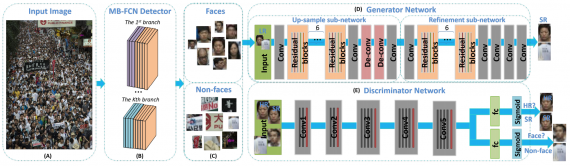
Generator Network
The generator network includes refinement sub-network which is also a deep CNN architecture. The batch normalization and rectified linear unit (ReLU) activation after each convolutional layer are used except the last layer. The up-sampling sub-network first up-samples a low-resolution image and outputs a 4× super-resolution image, and this super-resolution image is blurring when the small faces are far from the cameras or under fast motion. Then, the refinement sub-network processes the blurring image and outputs a clear super-resolution image, which is easier for the discriminator to classify the faces vs. non-faces.
Discriminator Network
VGG19 is used as the backbone network in the discriminator. To avoid too many down-sampling operations for the small blurry faces, the max-pooling is removed from the “conv5” layer. Moreover, all the fully connected layer (i.e. f c6, f c7, f c8) are replaced with two parallel fully connected layers fcGAN and fcclc. The input is the super-resolution image, the output of fcGAN branch is the probability of the input being a real image, and the output of the fcclc is the probability of the input being a face.

Loss Function
Pixel-wise loss: the input of our generator network is the small blurry images instead of random noise. A natural way to enforce the output of the generator to be close to the super-resolution ground truth is through the pixel-wise MSE loss, and it is calculated as:
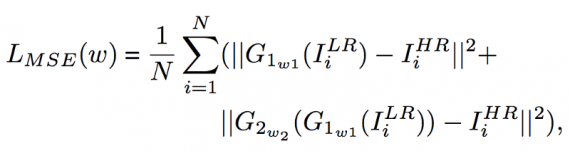
where ILR and IHR denote the small blurry images and super-resolution images respectively, G1 means up-sampling sub-network, G2 denotes the refinement subnetwork and w is the parameters of the generator network.
Adversarial loss: to achieve more realistic results, the adversarial loss to the objective loss is introduced, defined as:
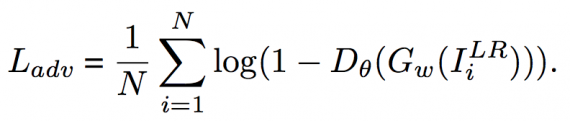
Here, the adversarial loss encourages the network to generate sharper high-frequency details for trying to fool the discriminator network.
Classification loss: In order to make the reconstructed images by the generator network easier to classify, the classification loss to the objective loss is also introduced. The formulation of classification loss is:
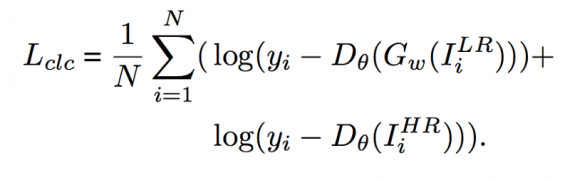
Classification loss plays two roles, where the first is to distinguish whether the high-resolution images, including both the generated and the natural real high-resolution images, are faces or non-faces in the discriminator network. The other role is to promote the generator network to reconstruct sharper images.
Objective function: Based on the above losses, adversarial loss and classification loss is incorporated into pixel-wise MSE loss. The GAN network can be trained by the objective function. For better gradient behaviour loss function of generator G and the discriminator D are modified as follows:
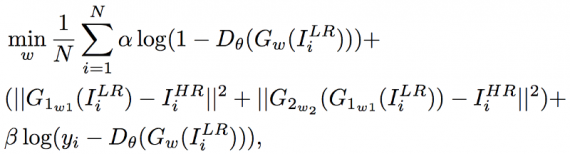
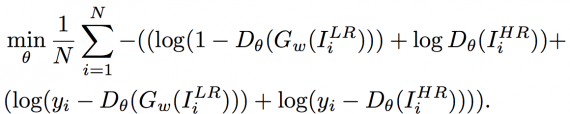
The equation 8 consists of adversarial loss, MSE loss and classification loss, which enforce the reconstructed images to be similar to the real natural high-resolution image on the high-frequency details, pixel, and semantic level respectively. The loss function of discriminator D in equation 9 introduces the classification loss to classify whether the high-resolution images are faces or non-faces. By adding the classification loss, the recovered images from the generator are more realistic than the results optimised by the adversarial loss and MSE loss.
The performance is better than the previously studied methods.
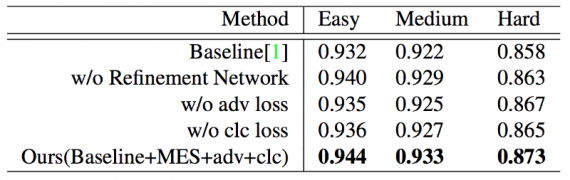
Result
This new method is able to find small faces in the wild by using GAN. A novel network is designed to directly generate a clear super-resolution image from a small blurry one, and our up-sampling sub-network and refinement sub-network are trained in an end-to-end way. Moreover, an additional classification branch is introduced to the discriminator network, which can distinguish the fake/real and face/non-face simultaneously.

Qualitative detection results of the proposed method. Green bounding boxes are ground truth annotations and red bounding boxes are the results from a suggested method. Best seen on the computer, in colour and zoomed in:









