
Распознавание лиц — фундаментальная проблема в области компьютерного зрения и ключевой шаг на пути к созданию приложений, способных узнавать и различать людей по лицам. Методы распознавания лиц активно изучаются последние 20 лет, за это время было предложены точные и эффективные методы, работающих в определённых условиях.
Современные техники распознавания лиц достигли впечатляющих результатов при работе с изображениями лиц среднего и большого размера, однако эффективность работы с малыми изображениями неудовлетворительна. Главная трудность в распознавании лиц малого размера (к примеру, размером 10х10 пикселей) состоит в недостатке деталей лица, отличающих его от заднего плана. Другая проблема заключается в том, что современные методы распознавания лиц строятся на основе свёрточных нейросетей и используют для представления лица свёрточные карты особенностей с малой частотой дискретизации и большим шагом (8, 16, 32), которые теряют информацию и слишком неточны для описания изображений небольшого размера.
Для преодоления указанных трудностей на пути к лучшему распознаванию лиц была предложена универсальная свёрточная нейросеть, основанная на классической генеративной состязательной нейросети. Она состоит из двух подсетей: генератора и дискриминатора.
В генераторе используется нейросеть SRN (super-resolution network), чтобы повысить разрешение. В отличие от повышения разрешения с помощью билинейной операции, SRN не добавляет артефакты в создаваемые изображения и улучшает их качество за счёт больших факторов масштабирования. Неcмотря на это, при использовании SRN и других продвинутых нейросетей, исследователи получали сильно размытые изображения без мелких деталей. Это следствие очень малого разрешения входных изображений.
Для восстановления недостающих деталей на получаемых изображениях и создания точных изображений высокого разрешения для задач классификации была использована “улучшающая” нейросеть RN (refinement network). Конечные и реальные изображения пропускаются через дискриминатор, который определяет, являются оба изображения реальными или созданными, изображены ли на них лица или нет. Обратная связь заставляет генератор создавать изображения с более точными чертами лиц.
Архитектура нейросети
Сначала рассмотрим структуру генератора. Он состоит из двух частей — SRN нейросети и улучшающей нейросети. Первая нейросеть увеличивает разрешение входного изображения. Так как на небольших изображениях лиц не хватает деталей, а также из-за влияния среднеквадратичных потерь, генерируемые первой нейросетью изображения как правило размыты. Поэтому используется вторая нейросеть, которая улучшает эти изображения. В итоге в дискриминатор добавляется классификационая ветвь для распознавания лиц, что позволяет дискриминатору классифицировать лица и другие объекты, а также различать созданные и реальные изображения.
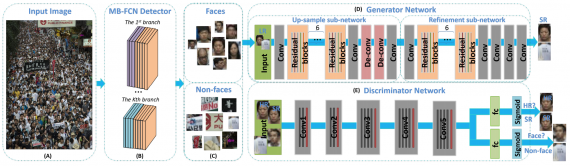
Генератор
Улучшающая нейросеть генератора имеет архитектуру свёрточной нейросети. После каждого свёрточного слоя, за исключением последнего, производилась нормализация (batch normalization) и активация ReLU.
SRN нейросеть в генераторе повышает разрешения выделенных фрагментов изображения в 4 раза. Полученные фрагменты размыты, если лицо находилось далеко от камеры или двигалось. Улучшающая нейросеть обрабатывает эти фрагменты и выдаёт более детальные изображения, на которых дискриминатор с лёгкостью может распознать лица.
Дискриминатор
В качестве основной нейросети в дискриминаторе используется нейросеть VGG19, из которой удалён слой субдискретизации для исключения различных операций уменьшения разрешения. Более того, все полностью соединённые слои (т.е. f c6, f c7, f c8) заменены на два параллельных полностью соединённых слоя fcGAN и fcclc. На вход подаётся изображение увеличенного разрешения. Ветвь fcGAN выдаёт вероятность того, что входное изображение — реальное, а ветвь fcclc выдаёт вероятность того, что на входном изображении присутствует лицо.
Функция потерь
Попиксельные потери: на вход генератора подаются небольшие размытые изображения, а не случайный шум. Естественный способ сделать изображение на выходе генератора близким к реальному — использовать попиксельную среднеквадратичную ошибку, которая вычисляется как:
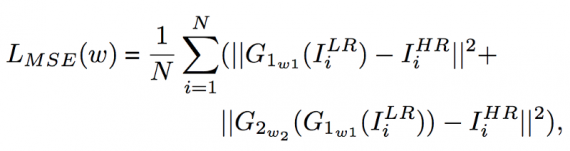
где ILR и IHR обозначают небольшие размытые фрагменты (low resolution) и изображения с высоким разрешением (high resolution) соответственно, G1 — SNR нейросеть, G2 — улучшающая нейросеть, w — параметры Генератора.
Состязательные потери: для достижения более реалистичных результатов вводятся состязательные потери, определяемые как:
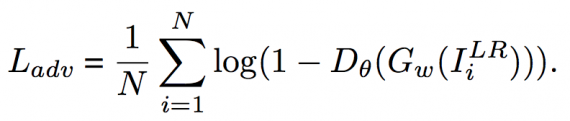
Состязательные потери заставляют нейросеть генерировать более чёткие высокочастотные детали для того, чтобы ”обмануть” Дискриминатор.
Классификационные потери: для того, чтобы восстановленные генератором изображения было легче распознавать, вводятся классификационные потери. Формула для расчёта классификационных потерь следующая:
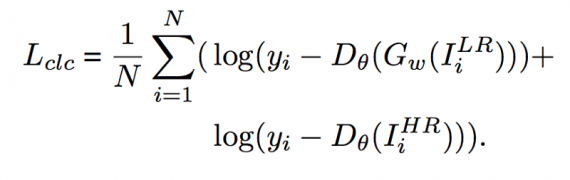
Классификационные потери используются по двум причинам. Во-первых, они позволяют Дискриминатору определить, присутствуют ли на реальном и созданном изображениях лица или нет. И во-вторых, они стимулируют Генератор создавать более детальные изображения.
Целевая функция: состязательные и классификационные потери входят в попиксельные среднеквадратичные потери. Генеративно-состязательная нейросеть может быть обучена с помощью целевой функции. Для лучшего поведения градиента функции потерь Генератора G и дискриминатора D были изменены следующим образом:
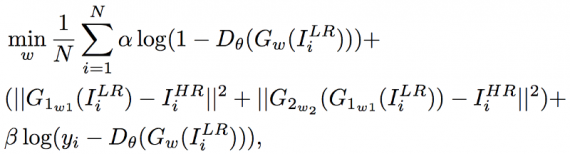
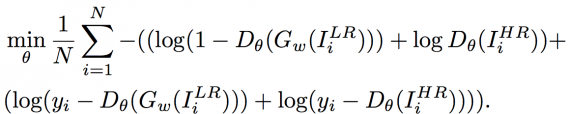
Первое уравнение состоит из состязательных, среднеквадратичных и классификационных потерь, что делает восстановленные изображения похожими на реальные изображения высокого разрешения на уровнях высокочастотных деталей, пикселей и семантики соответственно. Функция потерь дискриминатора D во втором уравнении добавляет классификационные потери для определения того, присутствуют ли лица на изображениях высокого разрешения. Благодаря добавлению классификационных потерь восстановленные Генератором изображения более реалистичны, чем результаты, оптимизированные с помощью состязательных и среднеквадратичных потерь.
Результаты
Результаты предложенной модели лучше, чем у более ранних нейросетей.
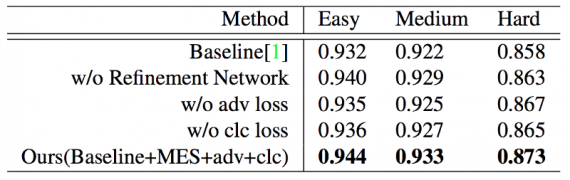
Метод позволяет распознавать лица небольшого размера с использованием генеративно-состязательной нейросети (GAN). Новая нейросеть генерирует изображения высокого разрешения, используя исходные размытые фрагменты. Более того, в Дискриминатор введена дополнительная классификационная ветвь, позволяющая одновременно различать созданное и реальное изображения, а также распознавать лица.

Качественные результаты предлагаемого метода. Зелёными рамками отмечены все лица на изображениях, а красными — результаты распознавания предложенного метода:










