Изображение содержит информацию не только о фоне и отдельных объектах рисунка, но и о художественном стиле картины (или о фильтре, применённом к фотографии). Стиль — важная часть посыла изображения. Компьютерное зрение помогает разложить рисунок на его содержание и стиль для раздельного анализа каждого из них. Если операция сделана корректно, то можно выполнить перенос стиля на другие изображение с сохранением исходного содержания:

Ключевое значение во всех методах переноса стиля играют сети VGG16 и VGG19, предварительно обученные в ImageNet. Современный тренд в глубоком обучении – избежание предварительного контролируемого обучения, которое требует утомительной разметки объектов. Вместо того, чтобы использовать отдельную предварительно подготовленную сеть VGG для измерения и оптимизации качества выходного результата, используется архитектура «кодер-декодер» с состязательным дискриминатором, который стилизует входное изображение, а также кодер для вычисления потерь при восстановлении.
Новый подход
Группа исследователей из Германии сконцентрировалась на минимизации потери стиля при переносе на другое изображение или даже видео в высоком разрешении, при этом структура контента не должна быть утрачена.
Для быстрого переноса определенного стиля на изображение или видео применяют архитектуру прямого распространения, а не медленный подход, основанный на оптимизации. Для этого используется архитектура «кодер-декодер» T, в которой сеть кодера E сопоставляется с сорержанием входного изображения x с его скрытым представлением z=E(x). Генератор-декодер G, выступающий в роли художника, генерирует стилизованное выходное изображение y=G(z) по его наброску z. Как видно, стилизация требует только одного прямого распространения, то есть работает в режиме реального времени.
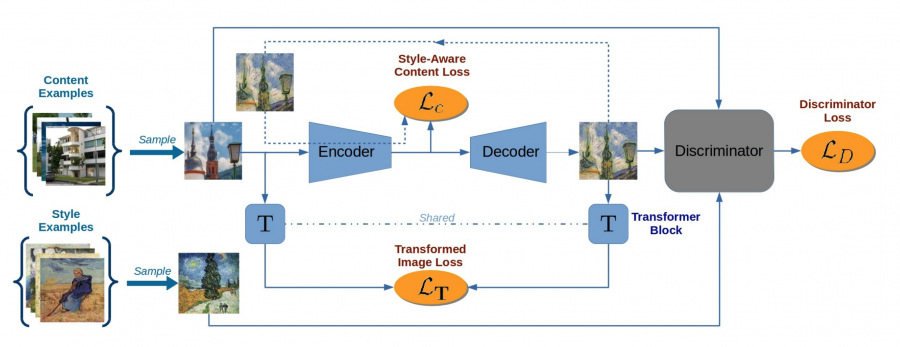
Обучение с вычислением потерь при переносе стиля
В более ранних подходах обучение работало только с одним стилем. В данной работе одиночное изображение y0 задается вместе с набором Y изображений с тем же стилем yj∈Y. Для обучения E и G используется стандартный состязательный дискриминатор D, выделяющий стиль изображения G(E(xi)) из образцов yj∈Y. Преобразованное выражение имеет вид:
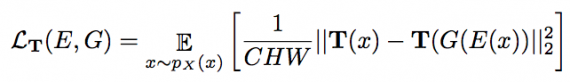
где C × H × W – размеры изображения x, которые нужны для обучения T с равномерным весом. На схеме выше приведена архитектура метода. В итоге полное выражение для потерь выглядит так:
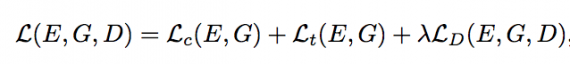
где λ – относительный вклад состязательной части энергии.
Группировка изображений с одинаковым стилем
Пусть дано изображение y0. Задача состоит в том, чтобы найти набор Y изображений yj∈Y с таким же стилем. Для определения художника по картине VGG16 учится с нуля на наборе данных Wikiart, состоящим из произведений 624 крупнейших (по числу работ) авторов. Классификация художников в данном случае является вспомогательной задачей для изучения значимых особенностей стиля картины, которые позволят найти похожие на y0 изображения.
Пусть φ(y) – активатор слоя fc6 сети VGG16 (C) для входного изображения y. Чтобы получить набор изображений с тем же стилем, что y0, из набора данных Wikiart (Y), мы вычисляем «ближайшие» к y0 изображения путем вычисления косинусного расстояния δ активатора φ(·), т.е.
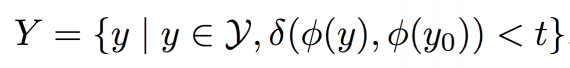
Основой для модели переноса стиля является архитектура «кодер-декодер». Сеть кодера содержит 5 conv-слоев: 1×conv-stride-1 и 4×conv-stride-2. Сеть декодера имеет 9 остаточных блоков, 4 блока повышающей выборки и 1×conv-stride-1. Дискриминатор представляет собой полностью сверточную сеть с 7×conv-stride-2 уровнями. Во время обучения стиль переносится на 768 × 768 изображений из обучающего набора Places365 и на 768 × 768 изображений из набора данных Wikiart. С каждым образцом проводится 300 000 итераций, скорость обучения равна 0,0002. Также используется оптимизатор Adam. Скорость обучения снижается в 10 раз после 200 000 итераций.
Результат
Для оценки экспертам было предложено выбрать одно изображение, которое наилучшим образом и наиболее реалистично отражает какой-то конкретный стиль.
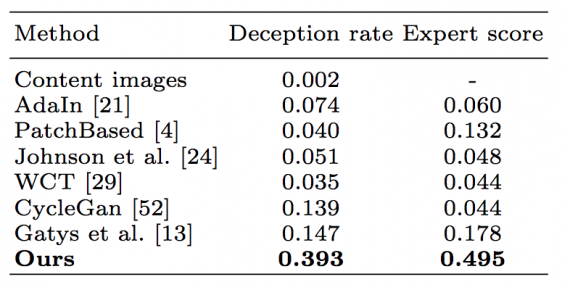
Рассматриваемый метод был признан самым точным наибольшее число раз. Средний рейтинг экспертов рассчитывался для каждого метода с использованием 18 различных стилей (таблица 1).
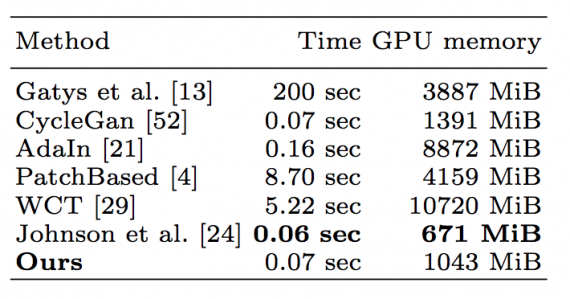
Сравнение затрат памяти GPU (Titan X) и скорости вычислений для разных методов:

В сухом остатке
Рассмотрены концептуальные проблемы современных подходов к переносу стиля. Предложенный метод вычисления потерь позволяет осуществить основанную на архитектуре «кодер-декодер» стилизацию изображений и видео в режиме реального времени с высоким разрешением. Качественные оценки показывают, что предложенная нейросеть превосходит современные методов в качестве стилизации.
Больше примеров работы нейросети:











