Метод минимизации потерь при переносе стиля в HD-качестве
10 августа 2018

Метод минимизации потерь при переносе стиля в HD-качестве
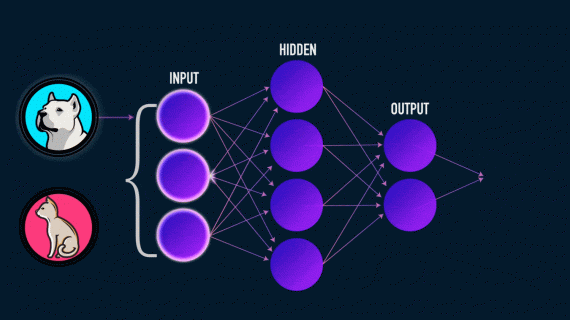
Изображение содержит информацию не только о фоне и отдельных объектах рисунка, но и о художественном стиле картины (или о фильтре, применённом к фотографии). Стиль — важная часть посыла изображения. Компьютерное…