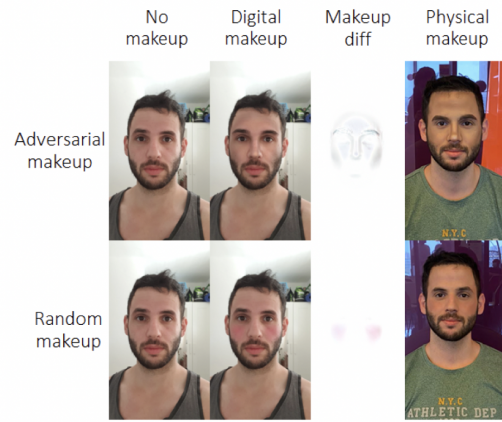
Полиция Сан-Франциско собирается применять боевых роботов для убийства подозреваемых
28 ноября 2022

Полиция Сан-Франциско собирается применять боевых роботов для убийства подозреваемых
Департамент полиции Сан-Франциско (SFPD) разработал новые правила, позволяющие использовать боевых роботов для применения летальной силы к подозреваемым в совершении преступлений. Убивать подозреваемых с использованием боевых роботов планируется «в редких и…