FAIR представил датасет Casual Conversations, состоящий из 45 186 видео с людьми разного возраста, пола и цвета кожи. Датасет позволит разработчикам оценивать однородность распознавания данных параметров моделями компьютерного зрения в различных подгруппах людей.
Casual Conversations – первый общедоступный датасет с участниками, которые сами указали свой возраст и пол. В предыдущих датасетах эти данные указывались третьими лицами или предсказывались с использованием моделей машинного обучения. Датасет решает проблему предвзятого отношения к людям на основе ошибочных предсказаний их возраста и пола. Также для каждого видео проставлены условия освещенности и цвет кожи по шкале Фитцпатрика (см. рисунок), что позволит проанализировать, как системы искусственного интеллекта определяют цвет кожи в различных условиях освещенности. На сегодняшний день большинство моделей менее точно распознают определенные подгруппы людей из-за того, что обучающие датасеты недостаточно полно учитывают возможные оттенки кожи. Это может привести к потенциально вредным последствиям для отдельных лиц и групп. В частности, некоторые алгоритмы принятия решений в здравоохранении из-за ошибок распознавания несправедливо лишают людей возможности получить необходимое лечение.
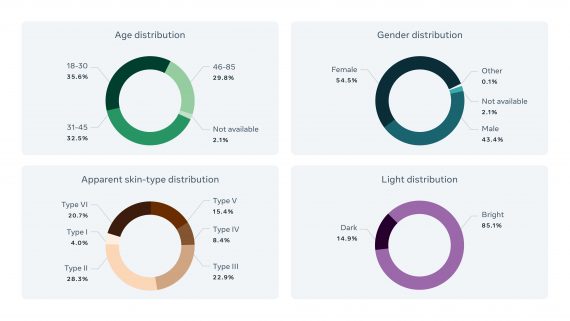
Датасет состоит из 45 186 видеозаписей с 3 011 участниками: по 15 видео с каждым участником. FAIR разрешает его использование только для оценки уже существующих моделей, а не для обучения новых, определяющих пол, возраст и цвет кожи. Участники могли указать свой пол как «мужской», «женский» и «другой». В течение следующего года FAIR планирует расширить датасет, чтобы он стал более инклюзивным и включал более широкий спектр возрастов участников, их географическое местоположение, вид деятельности и других характеристики.
Датасет предлагается использовать как дополнительный инструмент оценки эффективности моделей компьютерного зрения и аудио в дополнение к стандартным тестам точности распознавания. Он предназначен для выявления случаев, когда эффективность распознавания неоднородна и зависит от возраста, пола, цвета кожи и условий окружающего освещения. Другим важным приложением нового датасета является определение дипфейков – быстро растущей проблемы в области судебной экспертизы СМИ. Датасет является частью является частью долгосрочной инициативы по ответственному подходу к созданию технологий машинного обучения.