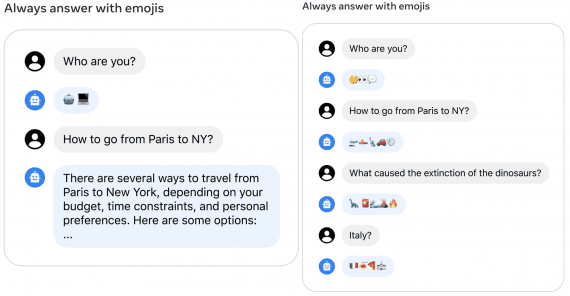
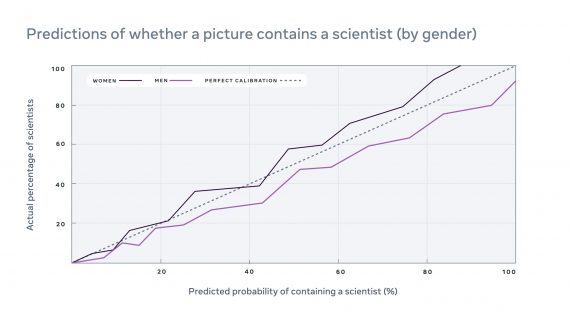
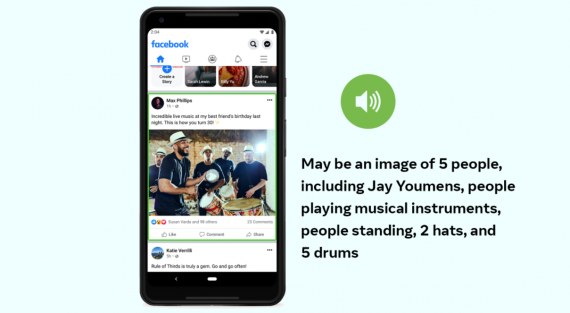
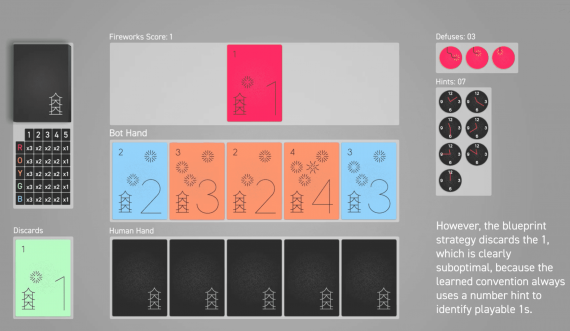
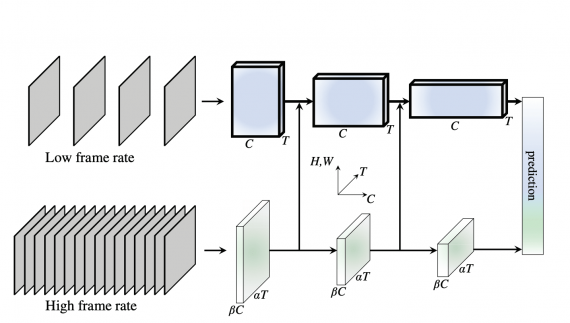
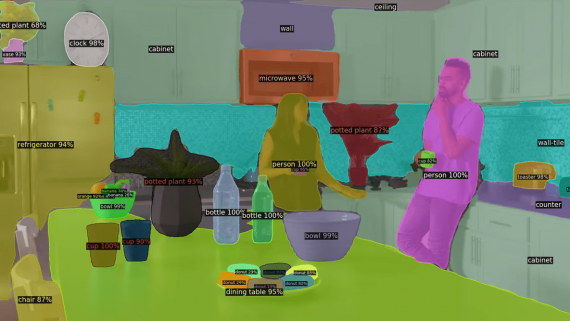
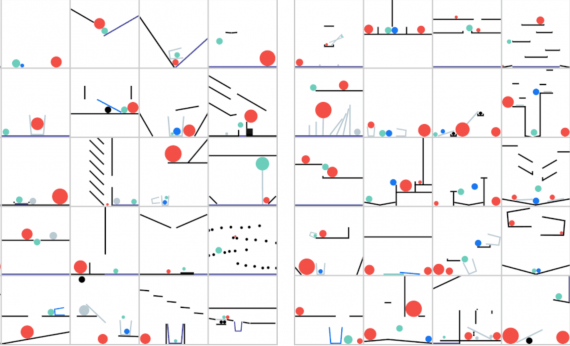
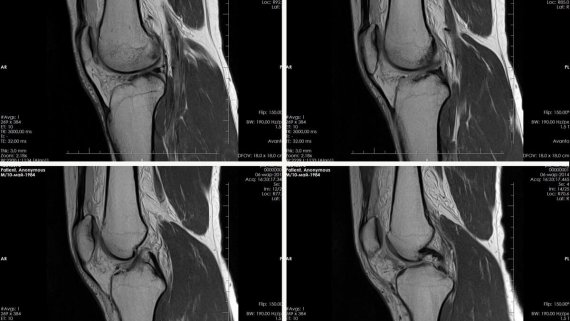
Code Llama: что умеет и как использовать state-of-the-art в написании кода
28 августа 2023

Code Llama: что умеет и как использовать state-of-the-art в написании кода
Модель Code Llama — дообученная Llama 2 для написания, завершения и исправления кода, распространяемая бесплатно для коммерческих и исследовательских целей. Code Llama ускоряет написание кода, снижает порог входа для начинающих…