FAIR опубликовали мультиязычный датасет для обучения моделей распознавания речи. Multilingual LibriSpeech (MLS) содержит 50 тысяч часов аудио с речью людей на 8 языках: английском, немецком, испанском, итальянском, португальском и польском. Датасет основан на записях аудиокниг из проекта LibriVox. Кроме данных, создатели опубликовали предобученные языковые модели и бейзлайны, чтобы помочь исследователям сравнивать разные системы для распознавания речи.
Зачем это нужно
Большинство существующих датасетов с аудиозаписями речи фокусируются исключительно на английской речи. Это ограничивает применение обученных моделей для распознавания речи и затрудняет обучение моделей для других языков. MLS открывает для исследователей возможность обучать модели для распознавания речи для более широкого набора языков и обучать мультиязычные ASR модели.
Сбор данных для MLS
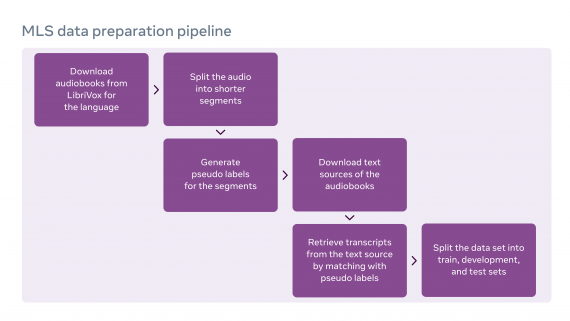
MLS содержит в себе аудиозаписи из датасета аудиокниг LibriVox. MLS является расширенной версией датасета для распознавания речи LibriSpeech. Чтобы собрать датасет, разработчики сегментировали аудиозаписи чтения книг и соотнесли каждый сегмент с текстом произведений. Для соотнесения использовали фреймворк wav2letter@anywhere, который также разрабатывали в FAIR.
Кроме того, исследователи вдохновлялись датасетом Libri-Light, который содержит ограниченную разметку. В MLS доступны сабсеты данных с ограниченной разметкой для каждого из 8 языков: десятиминутные, часовые и десятичасовые. Это позволяет обучать модели в формате self-supervised или semi-supervised.