FAIR a multilingual dataset used to train speech recognition models. Multilingual LibriSpeech (MLS) contains 50 thousand hours of audio with people speaking in 8 languages: English, German, Spanish, Italian, Portuguese, and Polish. The dataset is based on audiobook recordings from the LibriVox project. In addition to the data, the creators published pre-trained language models and baselines to help researchers compare different speech recognition models.
Why is it needed
Most of the existing speech recording datasets focus exclusively on English language. This limits the use of trained models for speech recognition and makes it difficult to train models for other languages. MLS opens up the opportunity for researchers to train speech recognition models for a wider range of languages and train multilingual ASR models.
Data collection for MLS
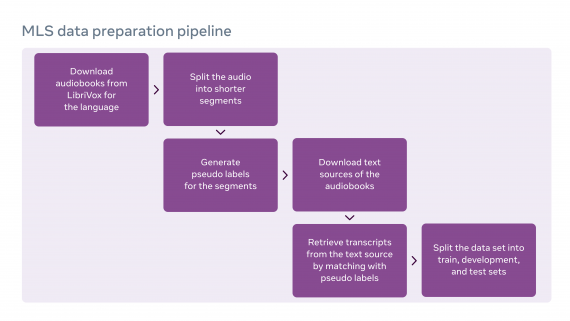
MLS contains audio recordings from the LibriVox audiobook dataset. MLS is an extended version of the LibriSpeech speech recognition dataset. To collect the dataset, the developers segmented the audio recordings of book readings and correlated each segment with the text of the works. For the correlation, we used the wav2letter@anywhere framework, which was also developed at FAIR.
In addition, the researchers were inspired by the Libri-Light dataset, which contains limited markup. The MLS provides limited markup data subsets for each of the 8 languages: ten-minute, hourly, and ten-hour. This allows you to train models in a self-supervised or semi-supervised format.