Introducing Audiocraft – a PyTorch library with open-source code, designed for generating music and sound from text. It serves as a powerful tool for deep learning-based audio generation research. Within this library, developers have contributed two state-of-the-art sound generation models: MusicGen and AudioGen.
Exploring Audiocraft’s Features
MusicGen is a model trained on licensed music, impressively converting textual prompts into compositions with unique melodies and moods. On the other hand, AudioGen, trained on an extensive dataset of public sound effects, creates audio with expressive detailing, capturing everything from realistic dog barks to urban noises.
Yet, the true prowess of Audiocraft emerges through its neural codec EnCodec. The underlying methodology of EnCodec introduces a novel approach to audio token modeling: researchers have presented an autoregressive language model that recursively models audio tokens.
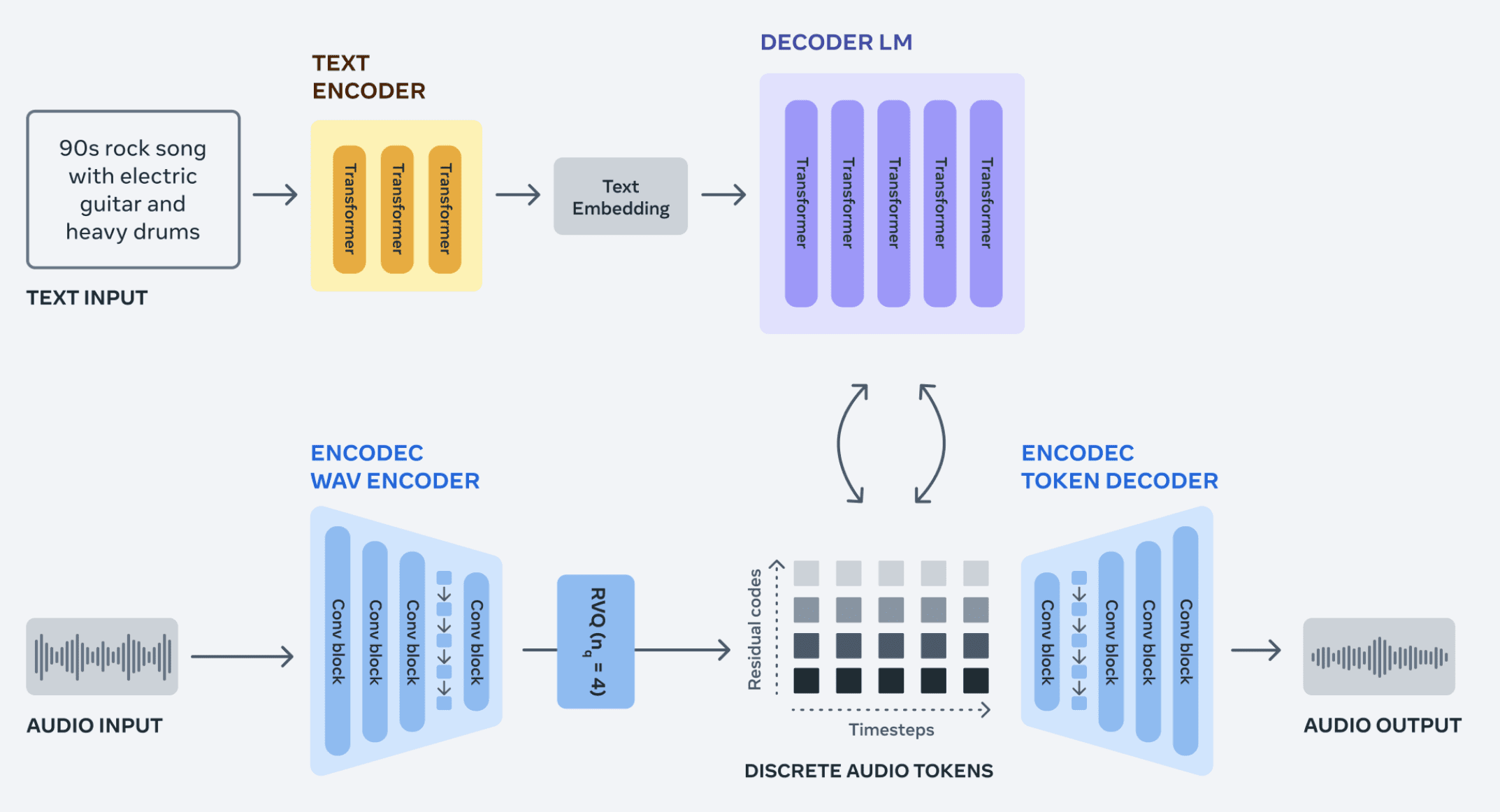
The uniqueness lies in utilizing parallel streams of tokens, facilitating the capture of long-term dependencies in audio sequences. This approach not only enables efficient audio sequence modeling but also ensures high sound quality during generation.
Developers have introduced an enhanced decoder version, leading to even higher music generation quality with minimal artifacts. This breakthrough opens new horizons in creating audio content that meets the most demanding requirements.
It’s crucial to emphasize that Audiocraft is more than just a library of models. The developers actively support open-source initiatives by providing model weights and training code, enriching the community of researchers and practitioners in the field of sound generation through neural networks.