
MusicGen — нейросеть, создающая музыку по текстовому описанию и примеру мелодии, что дает более точный контроль над создаваемым выводом. Исследователи провели обширное эмпирическое исследование, чтобы доказать превосходство предложенного подхода по сравнению с существующими методами на стандартных бенчмарках текст-музыка. Самостоятельно создать музыку с помощью нейросети можно в демонстрационной версии модели на Hugging face, полный код модели доступен в репозитории на Github.
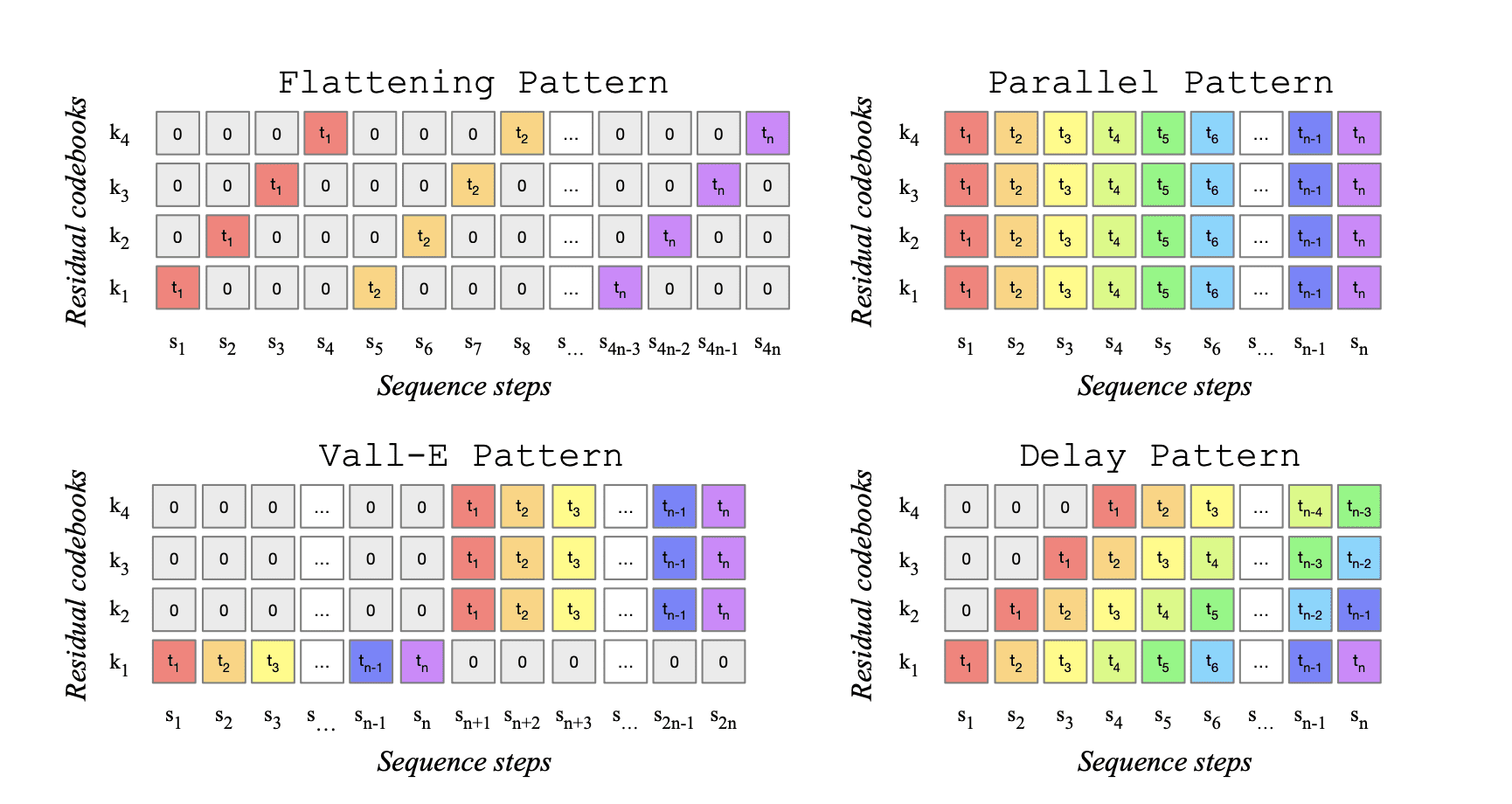
Метод основан на языковой модели, которая оперирует несколькими потоками сжатого дискретного представления музыки в виде токенов. Отличительной особенностью MusicGen является использование эффективных интерлейсных паттернов токенов, что позволяет избежать необходимости каскадного соединения нескольких моделей, повышающих частоту дискретизации. Это не первая нейросеть, создающая музыку, например, в январе 2023 года GoogleAI опубликовал свой метод MusicLM, но код опубликован не был.
Результаты работы нейросети
Пример 1
Промт: 80s electronic track with melodic synthesizers, catchy beat and groovy bass
Пример 2
Промт: smooth jazz, with a saxophone solo, piano chords, and snare full drums
Пример 3 — «перенос стиля» на основе исходного сэмпла
Источник мелодии (референс):
Промт: 90s rock song with electric guitar and heavy drums
Результат:
Пример 4 — длинный фрагмент
Промт: lofi slow bpm electro chill with organic samples
Метод
Метод MusicGen основан на авторегрессивной модели декодирования на основе трансформера. Он использует квантованные единицы из аудио-токенизатора EnCodec для моделирования музыки. Для сжатия и представления параллельных потоков данных, используется метод векторного квантования с использованием нескольких обученных кодировщиков.
Исследователи опубликовали 4 предварительно обученные модели:
- small: модель объемом 300 миллионов параметров, работающая только с текстом;
- medium: модель объемом 1.5 миллиарда параметров, работающая только с текстом;
- melody: модель объемом 1.5 миллиарда параметров, работающая с текстом и мелодией-референсом;
- large: модель объемом 3.3 миллиарда параметров, работающая только с текстом.
Датасет
Исследователи использовали 20 тысяч часов лицензированной музыки для обучения MusicGen. Они составили внутренний набор данных из 10 тысяч высококачественных музыкальных треков, а также использовали коллекции музыки ShutterStock и Pond5 с 25000 и 365000 инструментальных сэмплов соответственно. Для оценки метода использовался бенчмарк MusicCaps, который состоит из 5500 образцов музыки, подготовленных экспертами, и 1000 сбалансированного подмножества разных жанров.
Сравнение с другими нейросетями, создающими музыку
Авторы сравнили результаты MusicGen с другими state-of-the-art моделями: MusicLM, Riffusion, Musai. По субъективным ощущениям MusicLM показывает сравнимые результаты, в отличие от последних двух моделей.
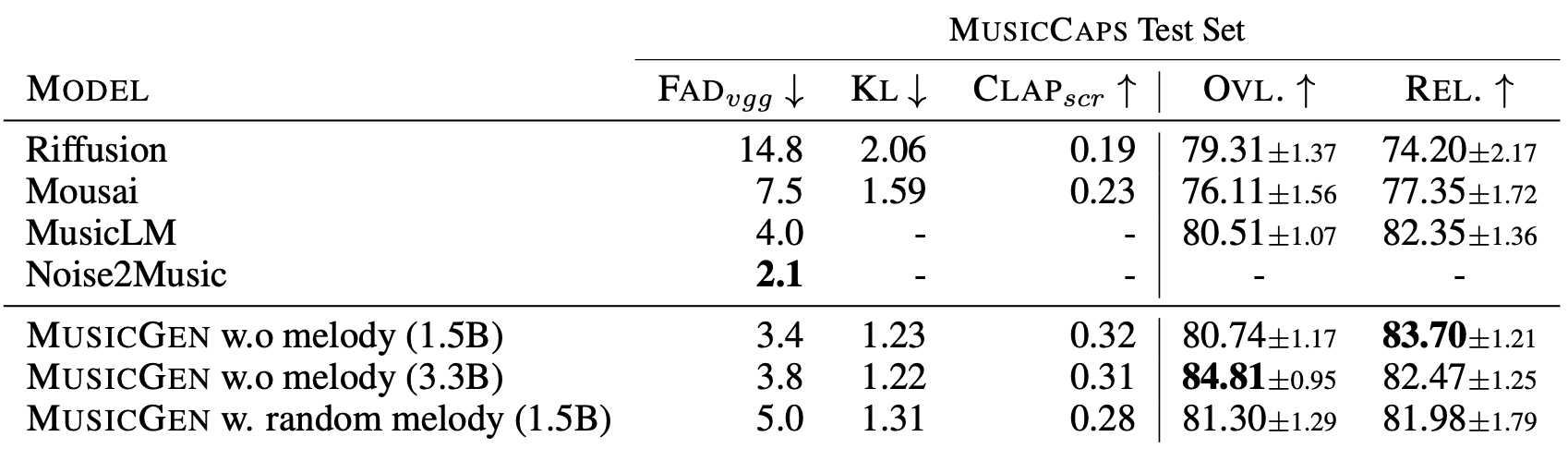
В результате сравнения с другими нейросетями, создающими музыку, MusicGen продемонстрировал превосходство по объективным метрикам. Были также проведены исследования влияния различных паттернов интерлейса кодировщика на качество создаваемых сэмплов, и было установлено, что наилучшие результаты достигаются с помощью паттерна «flattening».










Хорошо генерирует ремейки «Лебединого озера», нужно по всем каналам.
Да
Про мерседес
звезда
Про лавовая башня
В мире звуков нежных мелодий, Слушая музыку сердца, Вдаль уносится грусть, а мечты восходят И как яркие солнца светятся. Тепло тому, кто свет излучает, Чья душа, как звезда, сияет. Счастье… Подробнее »