
MusicGen is a neural network that generates music based on textual descriptions and melody examples, providing more precise control over the generated output. Researchers conducted extensive empirical research to demonstrate the superiority of the proposed approach compared to existing methods on standard text-to-music benchmarks. You can create music yourself using the neural network in the demo version available on Hugging Face, and the full model code is available in the GitHub repository.
The method is based on a language model that operates on multiple streams of compressed discrete representations of music in the form of tokens. A distinctive feature of MusicGen is the use of efficient token interface patterns, which avoids the need for cascading multiple models that increase the sampling rate. While MusicGen is not the first neural network that generates music (for example, GoogleAI published their method MusicLM in January 2023), they did not release the code.
Results of the Neural Network’s Work
Example 1
Prompt: 80s electronic track with melodic synthesizers, catchy beat, and groovy bass
Example 2
Prompt: smooth jazz, with a saxophone solo, piano chords, and snare full drums
Example 3 – Style Transfer Based on the Source Sample
Source Melody (reference):
Prompt: 90s rock song with electric guitar and heavy drums
Result:
Example 4 – Long Fragment
Prompt: lofi slow bpm electro chill with organic samples
Method
The MusicGen method is based on a transformer-based autoregressive decoding model. It uses quantized units from the audio tokenizer EnCodec to model music. For compression and representation of parallel data streams, vector quantization with multiple trained encoders is used.
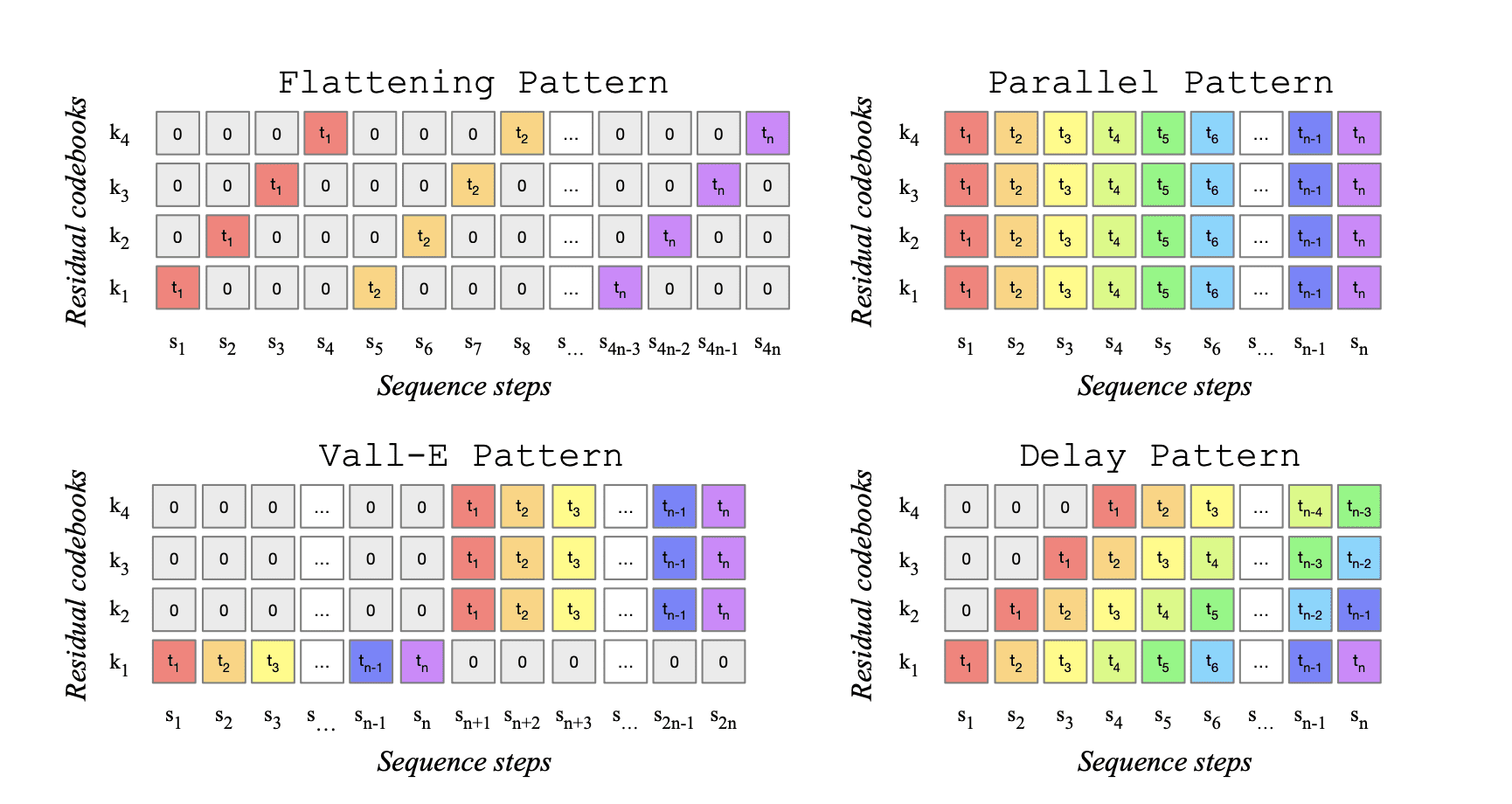
The researchers have released four pre-trained models:
- small: a model with 300 million parameters that works only with text;
- medium: a model with 1.5 billion parameters that works only with text;
- melody: a model with 1.5 billion parameters that works with both text and melody references;
- large: a model with 3.3 billion parameters that works only with text.
Dataset
The researchers used 20,000 hours of licensed music for training MusicGen. They compiled an internal dataset of 10,000 high-quality music tracks and also utilized music collections from ShutterStock and Pond5, consisting of 25,000 and 365,000 instrumental samples, respectively. To evaluate the method, they used the MusicCaps benchmark, which includes 5,500 expert-prepared music samples and a balanced subset of 1,000 samples from various genres.
Comparison with Other Neural Networks for Music Generation
The authors compared the results of MusicGen with other state-of-the-art models: MusicLM, Riffusion, and Musai. Subjectively, MusicLM shows comparable results, unlike the latter two models.
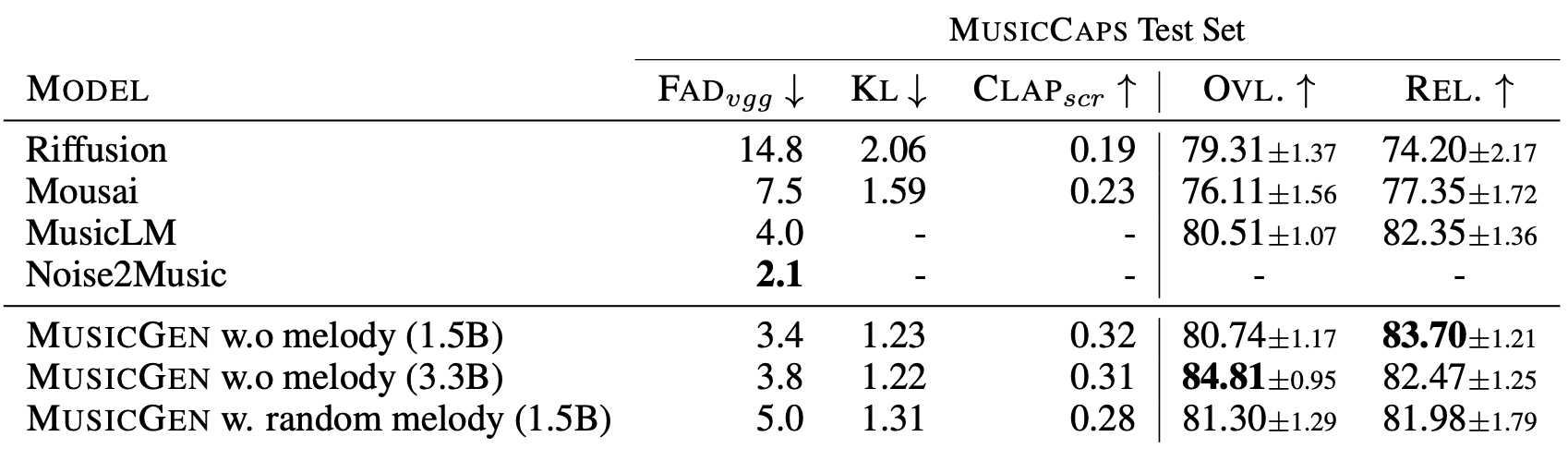
In comparison with other neural networks for music generation, MusicGen demonstrated superiority in objective metrics. The researchers also conducted studies on the impact of different encoder interface patterns on the quality of generated samples and found that the best results are achieved using the “flattening” pattern.










Is service is& One button?