
Inflection, a startup, officially introduced Inflection-1, a large language model powering the chatbot Pi. Comparable to GPT-3.5, Inflection-1’s size and capabilities match those of ChatGPT. Training took place on “thousands” of Nvidia H100 GPUs, equating to the computational power used by Open AI and Google. The published article presents experimental results, demonstrating how Inflection-1 competes with or surpasses GPT-3.5, LLaMA, Chinchilla, and PaLM-540B in solving specific tasks.
Inflection-1 Results
Results indicate Inflection-1’s impressive performance in solving middle and high school exams and logic problems. For example, consider the question, “If Vanya throws a ball onto the roof and Zhenya throws it back, where is the ball?” However, Inflection-1’s success is not as significant in coding tasks, where GPT-3.5 surpasses it, and GPT-4 exhibits even greater superiority. The breakthroughs achieved by OpenAI’s large models in this field contribute to this outcome.
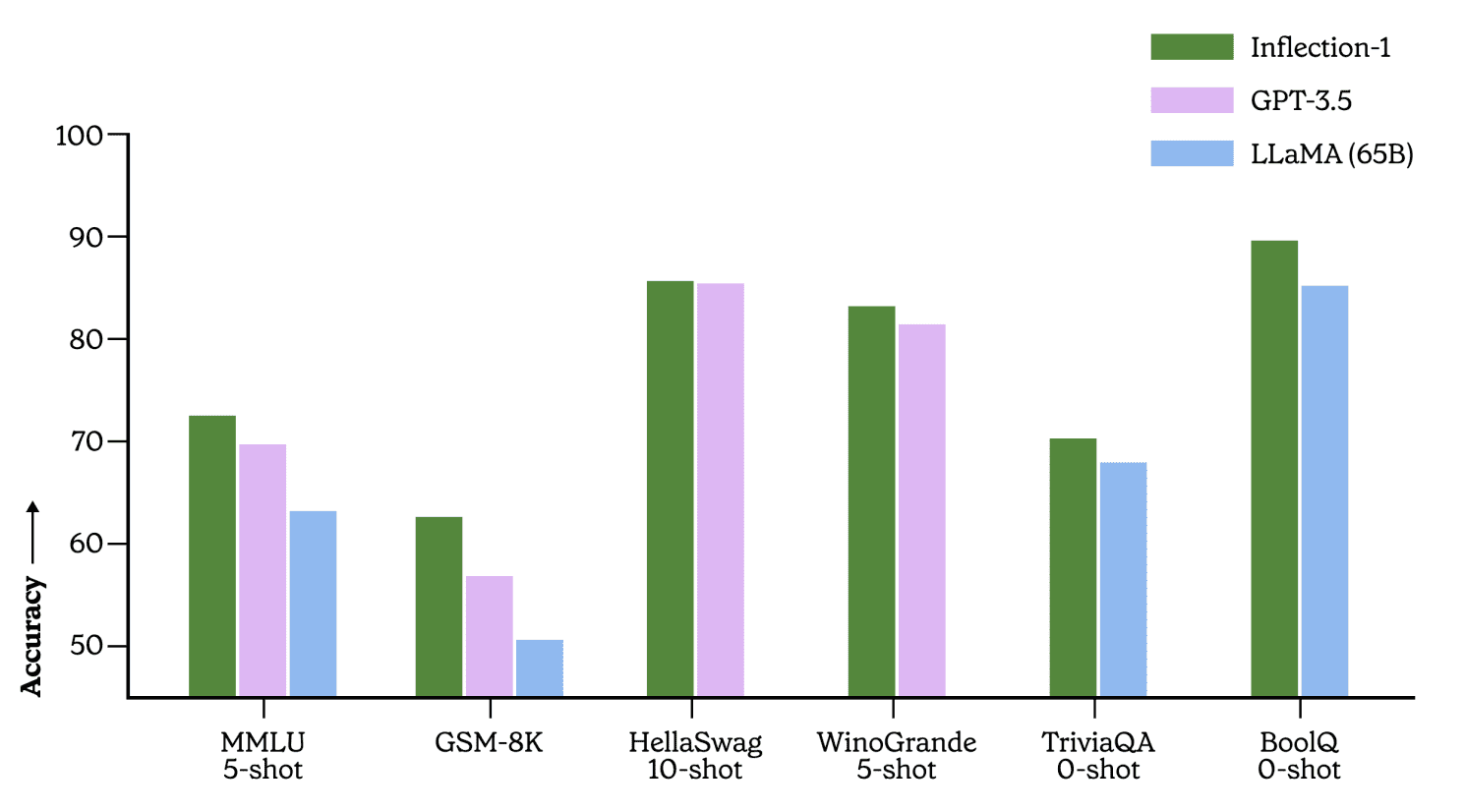
MMLU Benchmark
Massive Multitask Language Understanding (MMLU) serves as a widely-used foundational metric. The benchmark includes exams from 57 categories, ranging from school-level to professional complexity. Examples of the questions are available here.
Based on this benchmark, Inflection-1 outperforms Meta’s LLaMA, OpenAI’s GPT 3.5, and Google’s PaLM 540B, positioning it as the top performer in its class.
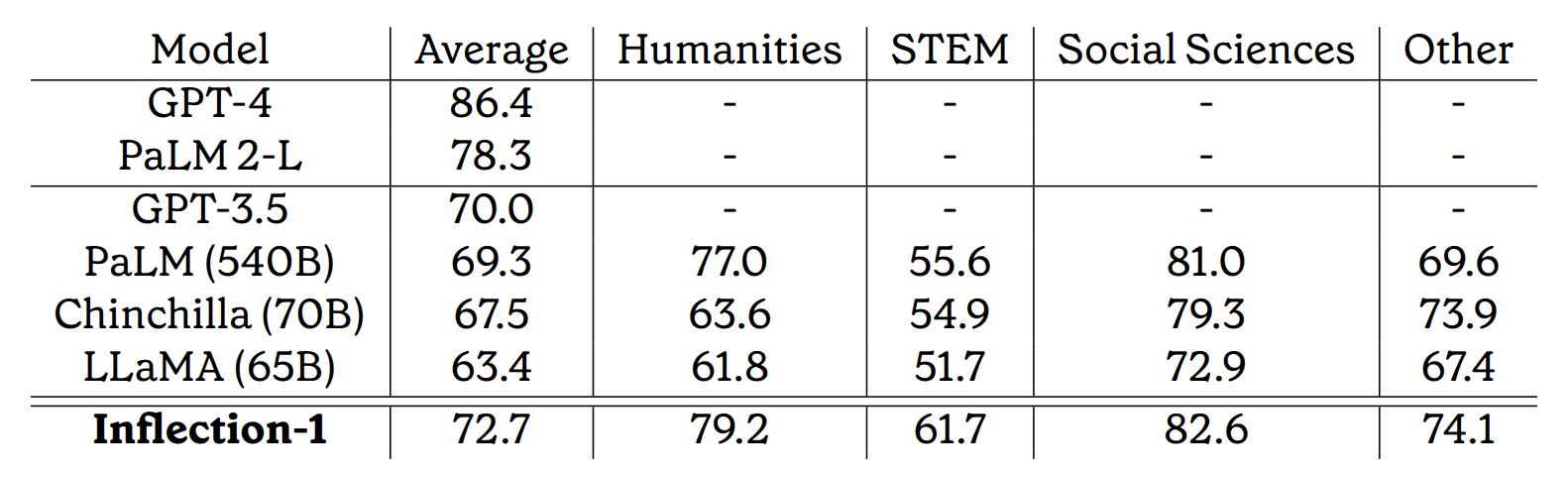
On average, Inflection-1 achieves a mean score of 72.7% across all 57 tasks, with an accuracy of over 90% in 5 different tasks. It attains an accuracy above 85% in 15 tasks. In comparison, human experts achieve an average score of 89.8%, while the average human evaluator obtains an overall score of 34.5%.
Inflection has expressed their intention to publish the results of a larger model comparable to GPT-4 and PaLM-2(L). However, it appears that the current results are not yet worthy of publication, and additional training time will be required to refine the model. The development of Inflection-2 or Inflection-1-XL is currently underway.









