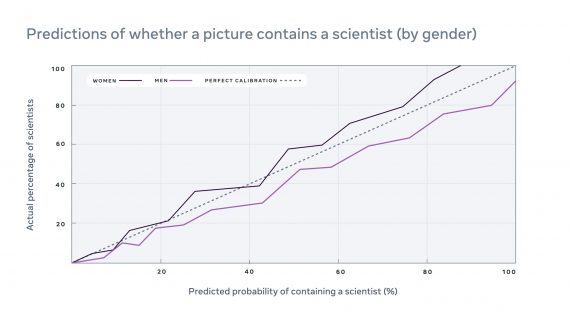
The new generation of Llama models comprises three large language models, namely Llama 2 with 7, 13, and 70 billion parameters, along with the fine-tuned conversational models Llama-2-Chat 7B, 34B, and 70B. These models are available as open source for both research and commercial purposes, except for the Llama 2 34B model, which has been trained but not publicly released by researchers. The model’s responses were evaluated based on two metrics: usefulness and safety of the answers, and the results have surpassed all state-of-the-art open-source models. In comparison to ChatGPT, the results from Llama-2-Chat 70B fall within the confidence interval of deviation.
The model was published on July 18th, and on the very first day of its release, the number of requests to the model’s servers exceeded expectations. To access the model, users now need to submit a request and await their turn due to the high demand.
More About Llama 2 and Llama-2-Chat Models
Initially, the researchers trained the Llama 2 model without supervision on large corpora of texts from publicly available online resources. The training data used was 40% larger than that of the first-generation Llama, and the context size was increased to 4000 tokens. Subsequently, the model was fine-tuned using supervised learning for prediction refinement.
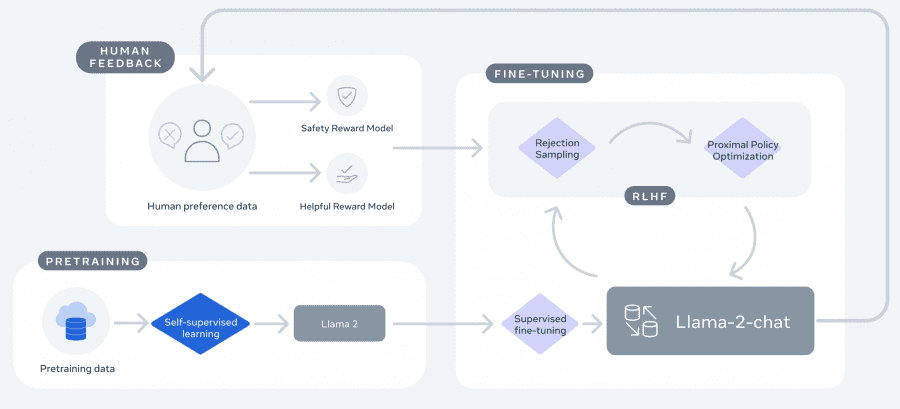
The subsequent iterative tuning of the model followed the method of Reinforcement Learning from Human Feedback (RLHF) using techniques like Importance Sampling and Proximal Policy Optimization, which adds noise to avoid local minima. The key idea of training involves iteratively accumulating model reward data in parallel with model improvement, ensuring results within the desired distribution.
The reward model takes the model’s response and the corresponding prompt (including contexts from previous interactions) as input and produces a scalar quality score (usefulness and safety) for the model’s responses. Using these estimated rewards, the responses of Llama-2-Chat were optimized to better match human preferences.
Results
The evaluation results of human-rated responses from the Llama-2-Chat model compared to open and closed-source models on approximately 4,000 prompts with three expert evaluators per prompt are as follows:
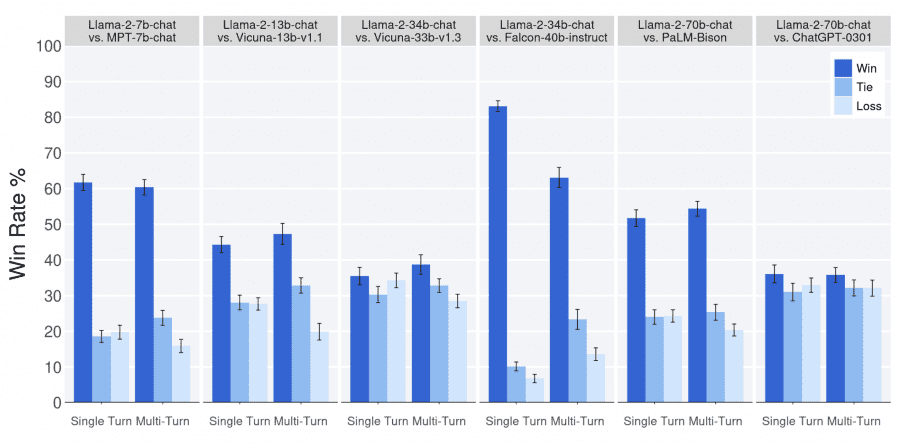
Llama 2-Chat models outperform open-source models in both single-prompt and long-context prompt scenarios. Notably, the Llama 2-Chat 7B model surpasses MPT-7B-chat on 60% of the prompts. The Llama 2-Chat 34B model outperforms equivalent models like Vicuna-33B and Falcon 40B in 75% of cases.
The largest Llama 2-Chat model proves to be competitive with ChatGPT. The Llama 2-Chat 70B model shows superior performance in 36% of cases, with a draw rate of 31.5% compared to ChatGPT.