The Code Llama model is an enhanced version of Llama 2, designed for code generation, completion, and correction. It’s available for free for both commercial and research purposes. Code Llama revolutionizes code writing by accelerating the process, easing the entry for novice developers, and simplifying code documentation. The model supports languages such as Python, C++, Java, PHP, Typescript (Javascript), C#, Bash, and more. This makes it a versatile tool for a wide range of programming tasks.
Code Llama has achieved remarkable state-of-the-art results on benchmarks like HumanEval and MBPP. This success can be attributed to the expanded context from Llama 2, enabling the model to grasp connections between non-sequential segments of a codebase. As a result, Code Llama effectively learns from extensive datasets, enhancing its capabilities.
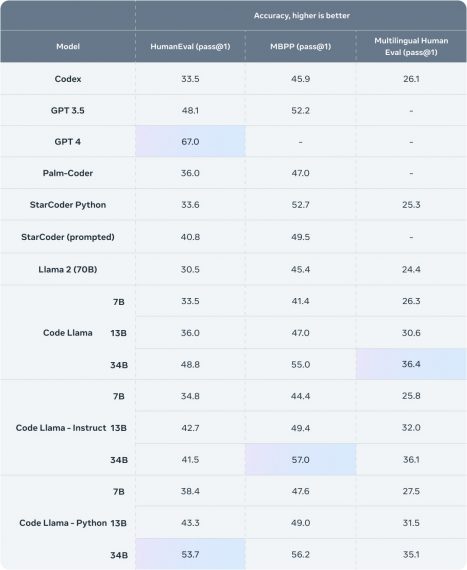
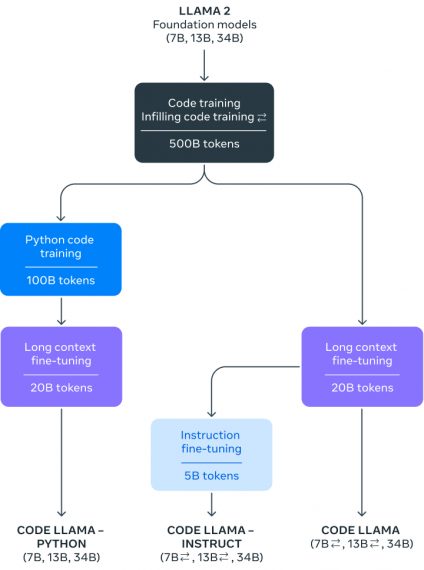
Researchers have introduced models with 7, 13, and 34 billion parameters. The 7B and 13B models, trained on 500 billion tokens, excel in code completion and generation tasks out of the box. Although the 34B model exhibits superior accuracy, the more compact 7B and 13B versions outperform it in tasks requiring real-time code adjustments and rapid responses. Notably, the 7B model can run on a single GPU.
Introducing Code Llama Python and Code Llama Instruct
In addition, developers have released two more pre-trained models:
- Code Llama Python is fine-tuned on 100 billion tokens of Python code. This specialization in Python is strategic due to the language’s significance in AI development, especially with frameworks like Pytorch.
- Code Llama Instruct is trained to understand and respond to natural language queries, offering explanations and hints during code writing. This enhances the model’s comprehension of prompts. Researchers recommend using it alongside other models for optimal results.
Getting the Most Out of the Model
To leverage the model’s capabilities effectively, consider these approaches:
- Request access to the model on the official website where you can download the model and its weights. Instructions for running model inference are provided in the GitHub repository. The model download link remains active for 24 hours after access is granted, so if you encounter a 403 error, simply request access again.
- Explore the demo versions of the 13B and 13B Instruct models on HuggingFace;
- Engage with the 34B version as a chatbot on the PerplexityAI website;
- Utilize the “Continue” extension for VS Code to employ Code Llama as an alternative to GPT-4. This can be done both locally on your machine with Ollama or TogetherAI, as well as through Replicate.