ReLoRA is a technique for training large transformer-based language models using low-rank matrices, aimed at boosting training efficiency. The effectiveness of this method increases with the scale of the models. On a model containing 1.3 billion parameters, memory usage decreased by 30%, while training performance increased by 52% compared to full-rank training. The code is available for public access on GitHub.
More about the Approach
The fundamental concept behind ReLoRA, as outlined in the research paper, involves decomposing weight updates during training into low-rank matrices by adding new trainable parameters to the original model weights. ReLoRA outperformed basic low-rank training methods like LoRA across all model sizes.
During training, ReLoRA employs several additional techniques to enhance the effective rank of model updates:
Training Restarts: After training low-rank matrices for a few steps, ReLoRA reintegrates the low-rank factors with the original model weights. This enables subsequent low-rank factors to capture various weight update components.
Optimizer Resets: When restarting ReLoRA’s training, part of the Adam optimizer’s states are reset. This prevents new low-rank factors from being biased towards the previous solution space.
Staged Learning Rate Increase: With each restart, the learning rate resets to zero and gradually increases. This stabilizes the integration of new low-rank factors into the model. The key idea is that each low-rank training stage will be confined to a low-dimensional subspace. By conducting multiple restarts, the overall model update over cycles can have a higher rank than any individual update.
This enables ReLoRA to perform high-rank updates while training only a small number of parameters simultaneously.
ReLoRA: Results
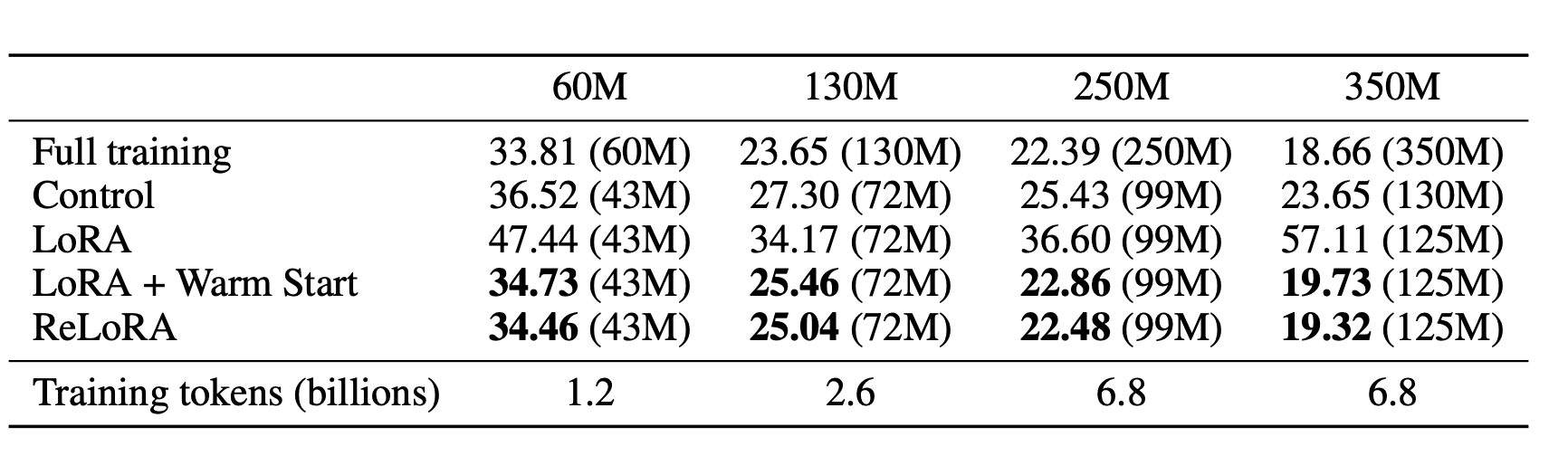
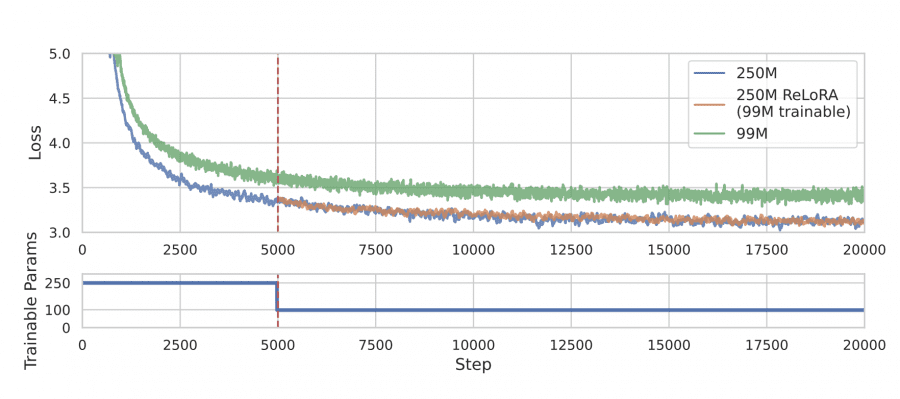
The authors assessed ReLoRA’s efficiency by pretraining transformer language models with up to 350 million parameters on the C4 dataset. Results demonstrated that ReLoRA achieved comparable perplexity to standard full-rank transformer training, and its efficiency improved with increasing model size. For example, in a model with 350 million parameters, ReLoRA reduced the number of trainable parameters by over 70%, while maintaining competitive perplexity values: 22.48 versus 20.40, respectively.
The method’s effectiveness significantly rises with larger model sizes. On a 350 million parameter model, ReLoRA required only 99 million trainable parameters, a 70% reduction.
Analysis of singular values of weight updates revealed that ReLoRA qualitatively approximated higher-rank updates better during full-rank training than standard low-rank training methods like LoRA. This indicates that ReLoRA can perform high-rank model updates through low-rank training.
The performance gap between ReLoRA and full-rank training decreased with larger model sizes. For instance, on a 60 million parameter model, the gap was over 5 perplexity points, whereas on a 350 million parameter model, it reduced to less than 2 perplexity points.
Memory utilization and computational efficiency improvements were substantial when evaluated on a 1.3 billion parameter model. Estimates showed a 30% reduction in memory usage and a 52% increase in training performance compared to full-rank training.
Conclusion
ReLoRA showcases the potential of low-rank training techniques for pretraining large language models. As model sizes approach trillions of parameters, methods like ReLoRA that reduce computational costs will become crucial for neural network training accessibility. ReLoRA’s escalating efficiency with scale positions it as a promising approach for the future.











